 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on Sentiment Analysis: Tasks, Approaches and Applications
Nov 19, 2023Sentiment analysis (SA) is an emerging field in text mining. It is the process of computationally identifying and categorizing opinions expressed in a piece of text over different social media platforms. Social media plays an essential role in knowing the customer mindset towards a product, services, and the latest market trends. Most organizations depend on the customer's response and feedback to upgrade their offered products and services. SA or opinion mining seems to be a promising research area for various domains. It plays a vital role in analyzing big data generated daily in structured and unstructured formats over the internet. This survey paper defines sentiment and its recent research and development in different domains, including voice, images, videos, and text. The challenges and opportunities of sentiment analysis are also discussed in the paper. \keywords{Sentiment Analysis, Machine Learning, Lexicon-based approach, Deep Learning, Natural Language Processing}
ssFPN: Scale Sequence (S^2) Feature Based-Feature Pyramid Network for Object Detection
Aug 25, 2022
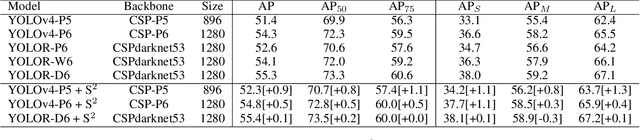

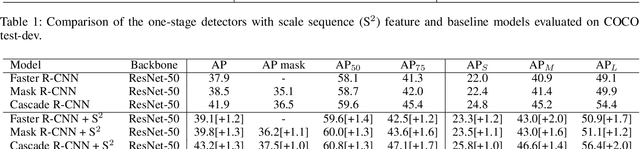
Feature Pyramid Network (FPN) has been an essential module for object detection models to consider various scales of an object. However, average precision (AP) on small objects is relatively lower than AP on medium and large objects. The reason is why the deeper layer of CNN causes information loss as feature extraction level. We propose a new scale sequence (S^2) feature extraction of FPN to strengthen feature information of small objects. We consider FPN structure as scale-space and extract scale sequence (S^2) feature by 3D convolution on the level axis of FPN. It is basically scale invariant feature and is built on high-resolution pyramid feature map for small objects. Furthermore, the proposed S^2 feature can be extended to most object detection models based on FPN. We demonstrate the proposed S2 feature can improve the performance of both one-stage and two-stage detectors on MS COCO dataset. Based on the proposed S2 feature, we achieve upto 1.3% and 1.1% of AP improvement for YOLOv4-P5 and YOLOv4-P6, respectively. For Faster RCNN and Mask R-CNN, we observe upto 2.0% and 1.6% of AP improvement with the suggested S^2 feature, respectively.
Group-based Bi-Directional Recurrent Wavelet Neural Networks for Video Super-Resolution
Jun 14, 2021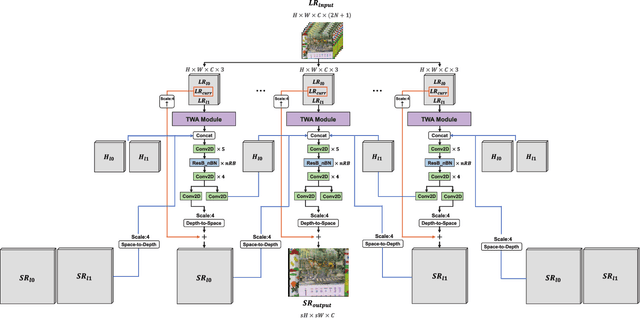


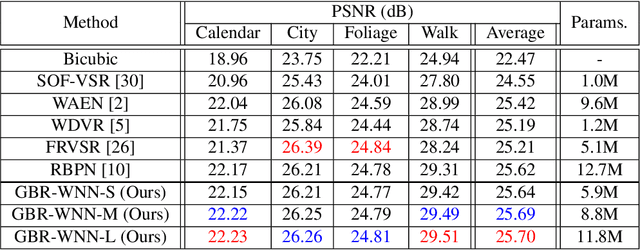
Video super-resolution (VSR) aims to estimate a high-resolution (HR) frame from a low-resolution (LR) frames. The key challenge for VSR lies in the effective exploitation of spatial correlation in an intra-frame and temporal dependency between consecutive frames. However, most of the previous methods treat different types of the spatial features identically and extract spatial and temporal features from the separated modules. It leads to lack of obtaining meaningful information and enhancing the fine details. In VSR, there are three types of temporal modeling frameworks: 2D convolutional neural networks (CNN), 3D CNN, and recurrent neural networks (RNN). Among them, the RNN-based approach is suitable for sequential data. Thus the SR performance can be greatly improved by using the hidden states of adjacent frames. However, at each of time step in a recurrent structure, the RNN-based previous works utilize the neighboring features restrictively. Since the range of accessible motion per time step is narrow, there are still limitations to restore the missing details for dynamic or large motion. In this paper, we propose a group-based bi-directional recurrent wavelet neural networks (GBR-WNN) to exploit the sequential data and spatio-temporal information effectively for VSR. The proposed group-based bi-directional RNN (GBR) temporal modeling framework is built on the well-structured process with the group of pictures (GOP). We propose a temporal wavelet attention (TWA) module, in which attention is adopted for both spatial and temporal features. Experimental results demonstrate that the proposed method achieves superior performance compared with state-of-the-art methods in both of quantitative and qualitative evaluations.
Deepfake Detection Scheme Based on Vision Transformer and Distillation
Apr 03, 2021



Deepfake is the manipulated video made with a generative deep learning technique such as Generative Adversarial Networks (GANs) or Auto Encoder that anyone can utilize. Recently, with the increase of Deepfake videos, some classifiers consisting of the convolutional neural network that can distinguish fake videos as well as deepfake datasets have been actively created. However, the previous studies based on the CNN structure have the problem of not only overfitting, but also considerable misjudging fake video as real ones. In this paper, we propose a Vision Transformer model with distillation methodology for detecting fake videos. We design that a CNN features and patch-based positioning model learns to interact with all positions to find the artifact region for solving false negative problem. Through comparative analysis on Deepfake Detection (DFDC) Dataset, we verify that the proposed scheme with patch embedding as input outperforms the state-of-the-art using the combined CNN features. Without ensemble technique, our model obtains 0.978 of AUC and 91.9 of f1 score, while previous SOTA model yields 0.972 of AUC and 90.6 of f1 score on the same condition.