 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-based Point Cloud Classification via Point Cloud to Image Translation
Aug 07, 2024



Point cloud understanding is an inherently challenging problem because of the sparse and unordered structure of the point cloud in the 3D space. Recently, Contrastive Vision-Language Pre-training (CLIP) based point cloud classification model i.e. PointCLIP has added a new direction in the point cloud classification research domain. In this method, at first multi-view depth maps are extracted from the point cloud and passed through the CLIP visual encoder. To transfer the 3D knowledge to the network, a small network called an adapter is fine-tuned on top of the CLIP visual encoder. PointCLIP has two limitations. Firstly, the point cloud depth maps lack image information which is essential for tasks like classification and recognition. Secondly, the adapter only relies on the global representation of the multi-view features. Motivated by this observation, we propose a Pretrained Point Cloud to Image Translation Network (PPCITNet) that produces generalized colored images along with additional salient visual cues to the point cloud depth maps so that it can achieve promising performance on point cloud classification and understanding. In addition, we propose a novel viewpoint adapter that combines the view feature processed by each viewpoint as well as the global intertwined knowledge that exists across the multi-view features. The experimental results demonstrate the superior performance of the proposed model over existing state-of-the-art CLIP-based models on ModelNet10, ModelNet40, and ScanobjectNN datasets.
Meta Episodic learning with Dynamic Task Sampling for CLIP-based Point Cloud Classification
Apr 01, 2024



Point cloud classification refers to the process of assigning semantic labels or categories to individual points within a point cloud data structure. Recent works have explored the extension of pre-trained CLIP to 3D recognition. In this direction, CLIP-based point cloud models like PointCLIP, CLIP2Point have become state-of-the-art methods in the few-shot setup. Although these methods show promising performance for some classes like airplanes, desks, guitars, etc, the performance for some classes like the cup, flower pot, sink, nightstand, etc is still far from satisfactory. This is due to the fact that the adapter of CLIP-based models is trained using randomly sampled N-way K-shot data in the standard supervised learning setup. In this paper, we propose a novel meta-episodic learning framework for CLIP-based point cloud classification, addressing the challenges of limited training examples and sampling unknown classes. Additionally, we introduce dynamic task sampling within the episode based on performance memory. This sampling strategy effectively addresses the challenge of sampling unknown classes, ensuring that the model learns from a diverse range of classes and promotes the exploration of underrepresented categories. By dynamically updating the performance memory, we adaptively prioritize the sampling of classes based on their performance, enhancing the model's ability to handle challenging and real-world scenarios. Experiments show an average performance gain of 3-6\% on ModelNet40 and ScanobjectNN datasets in a few-shot setup.
Joint Visual Semantic Reasoning: Multi-Stage Decoder for Text Recognition
Jul 27, 2021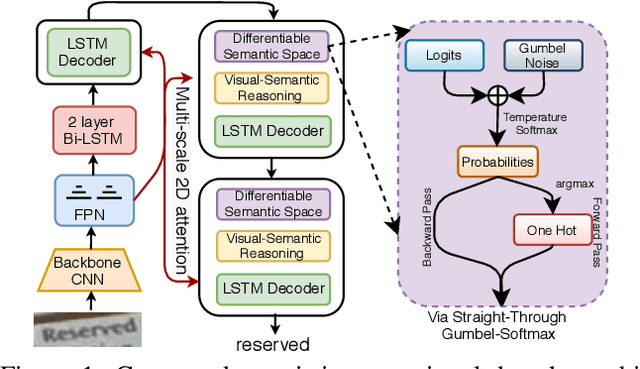
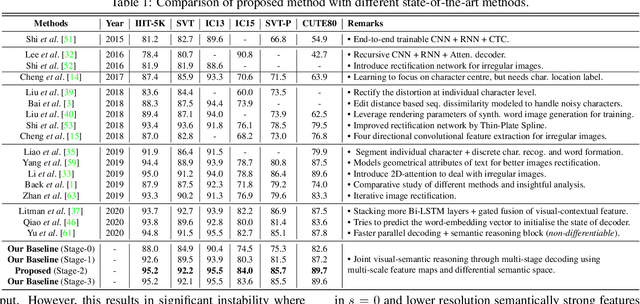
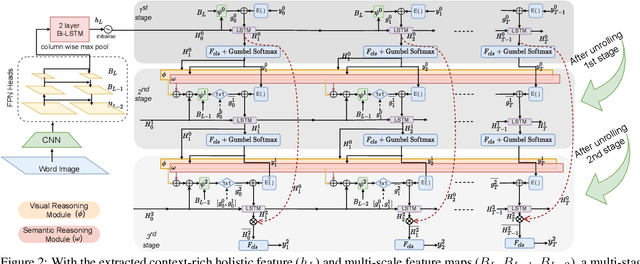
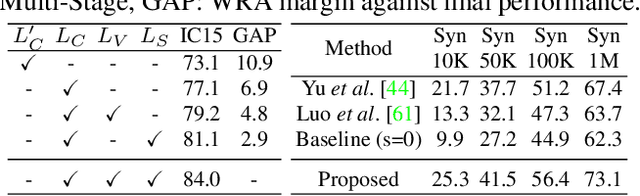
Although text recognition has significantly evolved over the years, state-of-the-art (SOTA) models still struggle in the wild scenarios due to complex backgrounds, varying fonts, uncontrolled illuminations, distortions and other artefacts. This is because such models solely depend on visual information for text recognition, thus lacking semantic reasoning capabilities. In this paper, we argue that semantic information offers a complementary role in addition to visual only. More specifically, we additionally utilize semantic information by proposing a multi-stage multi-scale attentional decoder that performs joint visual-semantic reasoning. Our novelty lies in the intuition that for text recognition, the prediction should be refined in a stage-wise manner. Therefore our key contribution is in designing a stage-wise unrolling attentional decoder where non-differentiability, invoked by discretely predicted character labels, needs to be bypassed for end-to-end training. While the first stage predicts using visual features, subsequent stages refine on top of it using joint visual-semantic information. Additionally, we introduce multi-scale 2D attention along with dense and residual connections between different stages to deal with varying scales of character sizes, for better performance and faster convergence during training. Experimental results show our approach to outperform existing SOTA methods by a considerable margin.
Word-level Sign Language Recognition with Multi-stream Neural Networks Focusing on Local Regions
Jun 30, 2021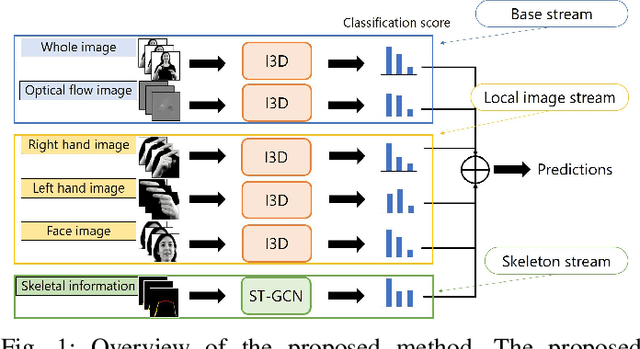
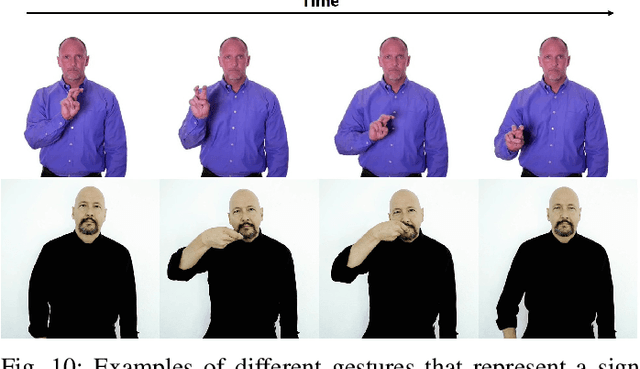
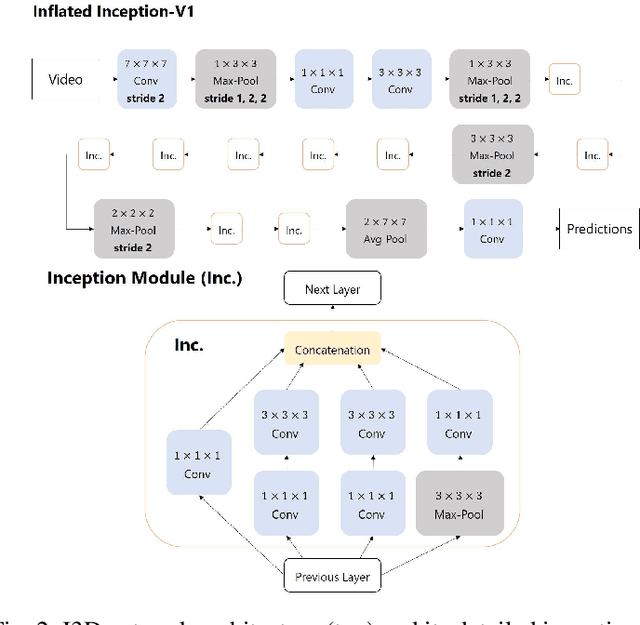
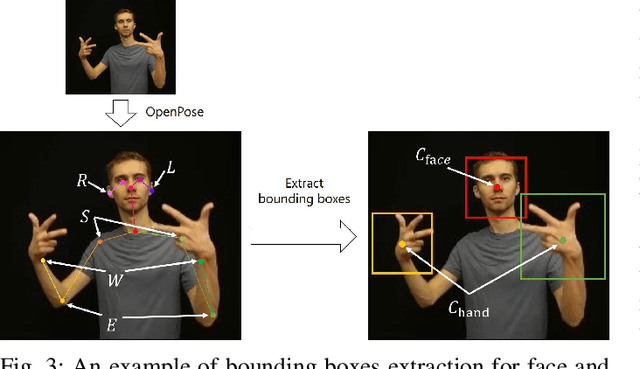
In recent years, Word-level Sign Language Recognition (WSLR) research has gained popularity in the computer vision community, and thus various approaches have been proposed. Among these approaches, the method using I3D network achieves the highest recognition accuracy on large public datasets for WSLR. However, the method with I3D only utilizes appearance information of the upper body of the signers to recognize sign language words. On the other hand, in WSLR, the information of local regions, such as the hand shape and facial expression, and the positional relationship among the body and both hands are important. Thus in this work, we utilized local region images of both hands and face, along with skeletal information to capture local information and the positions of both hands relative to the body, respectively. In other words, we propose a novel multi-stream WSLR framework, in which a stream with local region images and a stream with skeletal information are introduced by extending I3D network to improve the recognition accuracy of WSLR. From the experimental results on WLASL dataset, it is evident that the proposed method has achieved about 15% improvement in the Top-1 accuracy than the existing conventional methods.
MetaHTR: Towards Writer-Adaptive Handwritten Text Recognition
Apr 05, 2021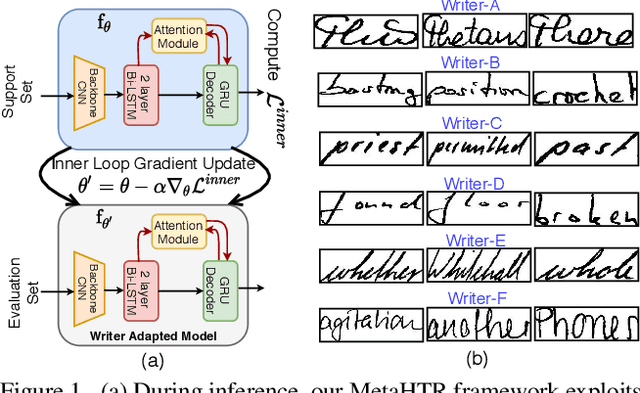

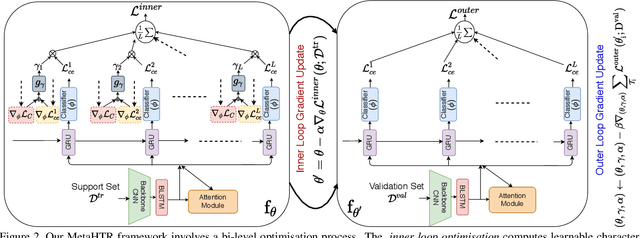
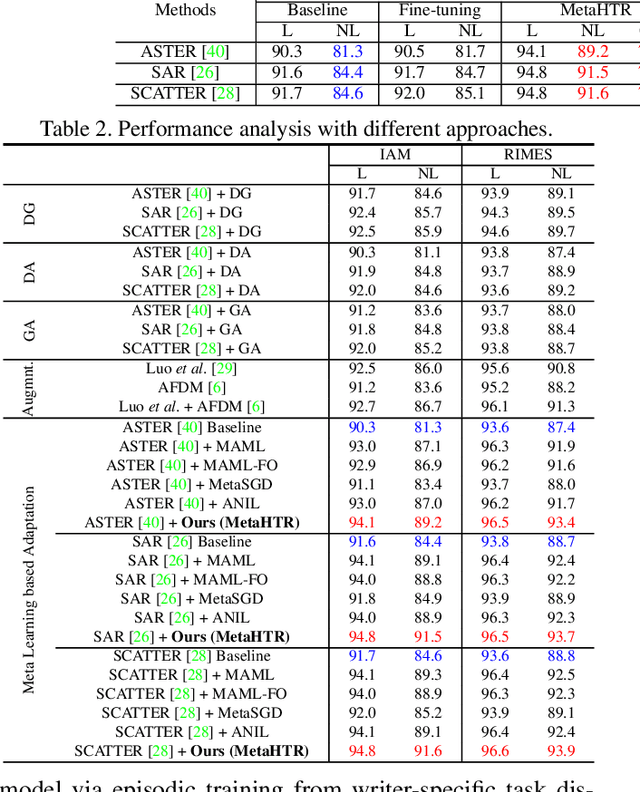
Handwritten Text Recognition (HTR) remains a challenging problem to date, largely due to the varying writing styles that exist amongst us. Prior works however generally operate with the assumption that there is a limited number of styles, most of which have already been captured by existing datasets. In this paper, we take a completely different perspective -- we work on the assumption that there is always a new style that is drastically different, and that we will only have very limited data during testing to perform adaptation. This results in a commercially viable solution -- the model has the best shot at adaptation being exposed to the new style, and the few samples nature makes it practical to implement. We achieve this via a novel meta-learning framework which exploits additional new-writer data through a support set, and outputs a writer-adapted model via single gradient step update, all during inference. We discover and leverage on the important insight that there exists few key characters per writer that exhibit relatively larger style discrepancies. For that, we additionally propose to meta-learn instance specific weights for a character-wise cross-entropy loss, which is specifically designed to work with the sequential nature of text data. Our writer-adaptive MetaHTR framework can be easily implemented on the top of most state-of-the-art HTR models. Experiments show an average performance gain of 5-7% can be obtained by observing very few new style data. We further demonstrate via a set of ablative studies the advantage of our meta design when compared with alternative adaption mechanisms.
UDBNET: Unsupervised Document Binarization Network via Adversarial Game
Jul 14, 2020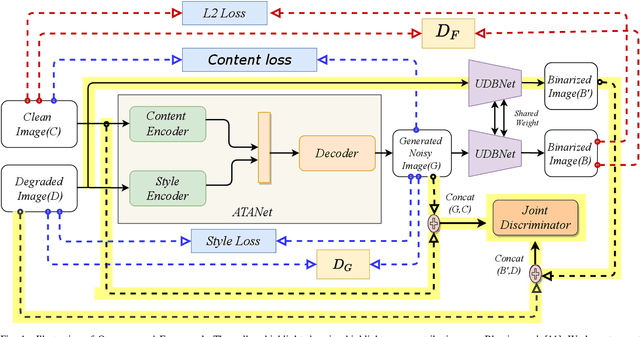



Degraded document image binarization is one of the most challenging tasks in the domain of document image analysis. In this paper, we present a novel approach towards document image binarization by introducing three-player min-max adversarial game. We train the network in an unsupervised setup by assuming that we do not have any paired-training data. In our approach, an Adversarial Texture Augmentation Network (ATANet) first superimposes the texture of a degraded reference image over a clean image. Later, the clean image along with its generated degraded version constitute the pseudo paired-data which is used to train the Unsupervised Document Binarization Network (UDBNet). Following this approach, we have enlarged the document binarization datasets as it generates multiple images having same content feature but different textual feature. These generated noisy images are then fed into the UDBNet to get back the clean version. The joint discriminator which is the third-player of our three-player min-max adversarial game tries to couple both the ATANet and UDBNet. The three-player min-max adversarial game stops, when the distributions modelled by the ATANet and the UDBNet align to the same joint distribution over time. Thus, the joint discriminator enforces the UDBNet to perform better on real degraded image. The experimental results indicate the superior performance of the proposed model over existing state-of-the-art algorithm on widely used DIBCO datasets. The source code of the proposed system is publicly available at https://github.com/VIROBO-15/UDBNET.
Modeling Extent-of-Texture Information for Ground Terrain Recognition
Apr 17, 2020
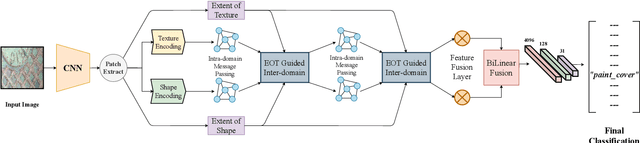
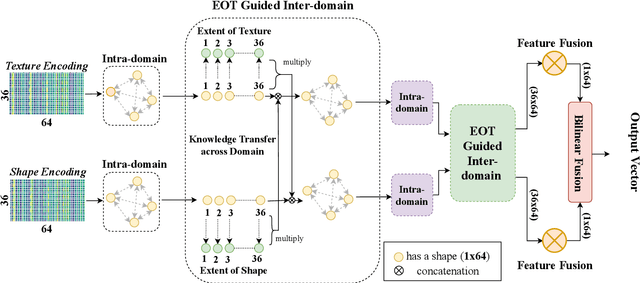
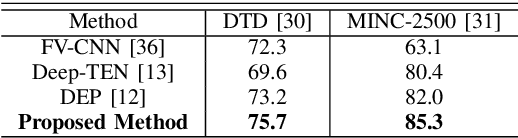
Ground Terrain Recognition is a difficult task as the context information varies significantly over the regions of a ground terrain image. In this paper, we propose a novel approach towards ground-terrain recognition via modeling the Extent-of-Texture information to establish a balance between the order-less texture component and ordered-spatial information locally. At first, the proposed method uses a CNN backbone feature extractor network to capture meaningful information of a ground terrain image, and model the extent of texture and shape information locally. Then, the order-less texture information and ordered shape information are encoded in a patch-wise manner, which is utilized by intra-domain message passing module to make every patch aware of each other for rich feature learning. Next, the Extent-of-Texture (EoT) Guided Inter-domain Message Passing module combines the extent of texture and shape information with the encoded texture and shape information in a patch-wise fashion for sharing knowledge to balance out the order-less texture information with ordered shape information. Further, Bilinear model generates a pairwise correlation between the order-less texture information and ordered shape information. Finally, the ground-terrain image classification is performed by a fully connected layer. The experimental results indicate superior performance of the proposed model over existing state-of-the-art techniques on publicly available datasets like DTD, MINC and GTOS-mobile.
Handwriting Recognition in Low-resource Scripts using Adversarial Learning
Nov 04, 2018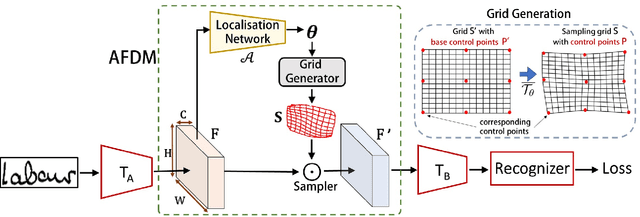
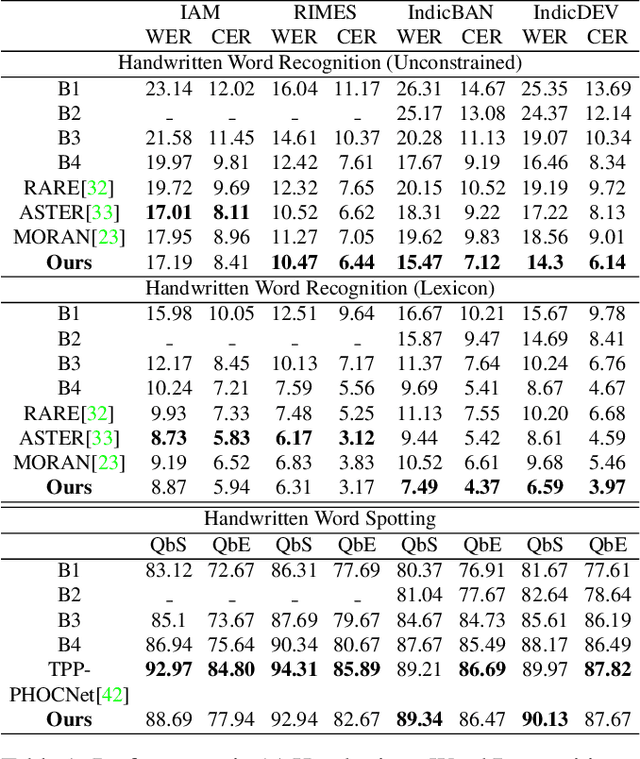
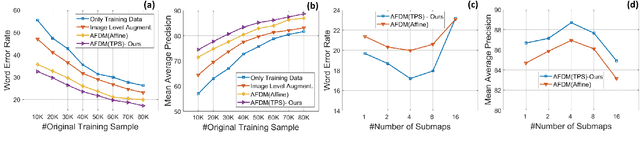

Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten text possessing irregular and complex shapes. Designing models using deep neural networks makes it necessary to extend datasets in order to introduce variances and increase the number of training samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the existing literature use preprocessing strategies which are seldom sufficient to cover all possible variations. We propose the Adversarial Feature Deformation Module that learns ways to elastically warp extracted features in a scalable manner. It is inserted between intermediate layers and trained alternatively with the original framework, boosting its capability to better learn highly informative features rather than trivial ones. We test our meta-framework which is built on top of popular spotting and recognition frameworks and enhanced by the AFDM not only on extensive Latin word datasets, but on sparser Indic scripts too. We record results for varying training data sizes, and observe that our enhanced network generalizes much better in the low-data regime; the overall word-error rates and mAP scores are observed to improve as well.
Query-based Logo Segmentation
Nov 04, 2018
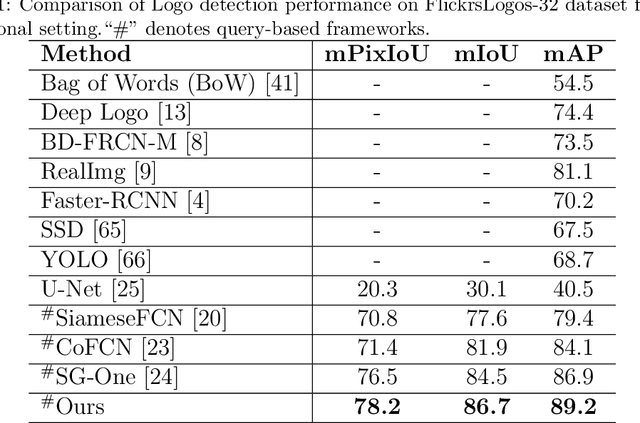
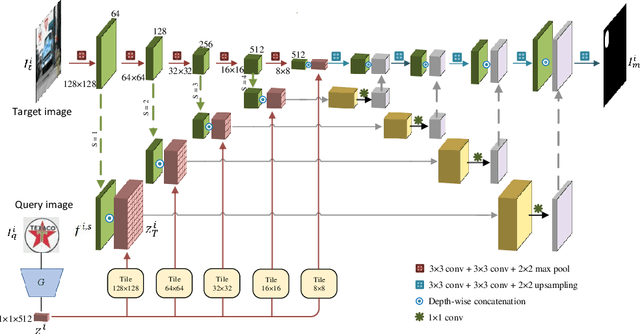
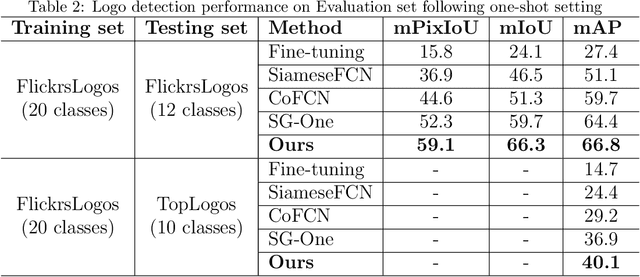
Logo detection in real-world scene images is an important problem with useful applications in advertisement and marketing. Existing general-purpose object detection methods require large training data with bounding box annotations for every logo class. These methods do not satisfy the incremental demand of logo classes necessary for practical deployment as it is practically impossible to have such paired data for every new unseen logo. In this work, we propose a query-based logo search and detection system by employing a one-shot learning technique. Given an image of a query logo, the model searches for it within a given target image and predicts the possible location of the logo by estimating a corresponding binary mask. The proposed model consists of a conditional branch and a segmentation branch. The former gives a conditional representation of a given query logo which is combined with the feature maps at multiple scales of the segmentation branch. The multi-scale conditioning allows our model to obtain a scale-invariant solution. Experimental results reveal that our model can be successfully adapted for any logo classes without separately training the whole network. Also, our query-based logo retrieval framework achieved superior performance in FlickrLogos-32 and TopLogos-10 dataset over existing baselines.
User Constrained Thumbnail Generation using Adaptive Convolutions
Nov 01, 2018
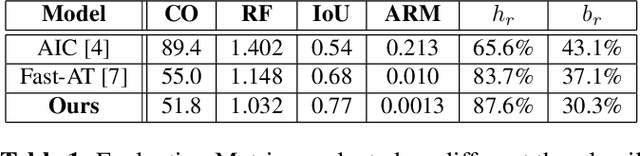
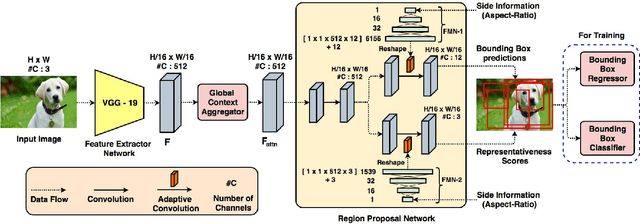

Thumbnails are widely used all over the world as a preview for digital images. In this work we propose a deep neural framework to generate thumbnails of any size and aspect ratio, even for unseen values during training, with high accuracy and precision. We use Global Context Aggregation (GCA) and a modified Region Proposal Network (RPN) with adaptive convolutions to generate thumbnails in real time. GCA is used to selectively attend and aggregate the global context information from the entire image while the RPN is used to predict candidate bounding boxes for the thumbnail image. Adaptive convolution eliminates the problem of generating thumbnails of various aspect ratios by using filter weights dynamically generated from the aspect ratio information. The experimental results indicate the superior performance of the proposed model over existing state-of-the-art techniques.