 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture Synthesis Guided Deep Hashing for Texture Image Retrieval
Nov 04, 2018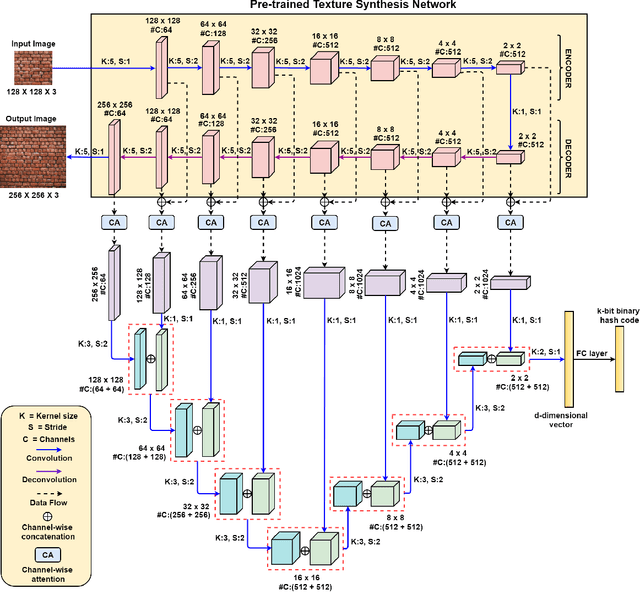
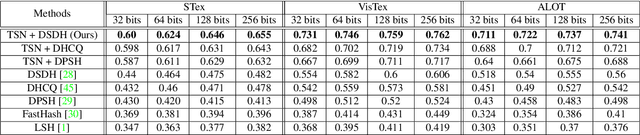

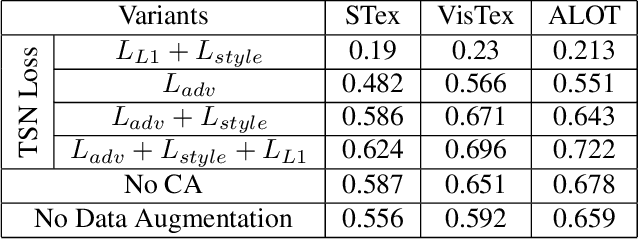
With the large-scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works uses hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN's intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over current state-of-the-art methods.
Handwriting Recognition in Low-resource Scripts using Adversarial Learning
Nov 04, 2018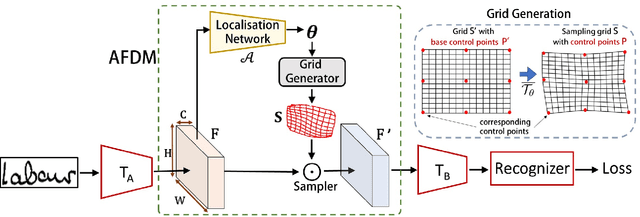
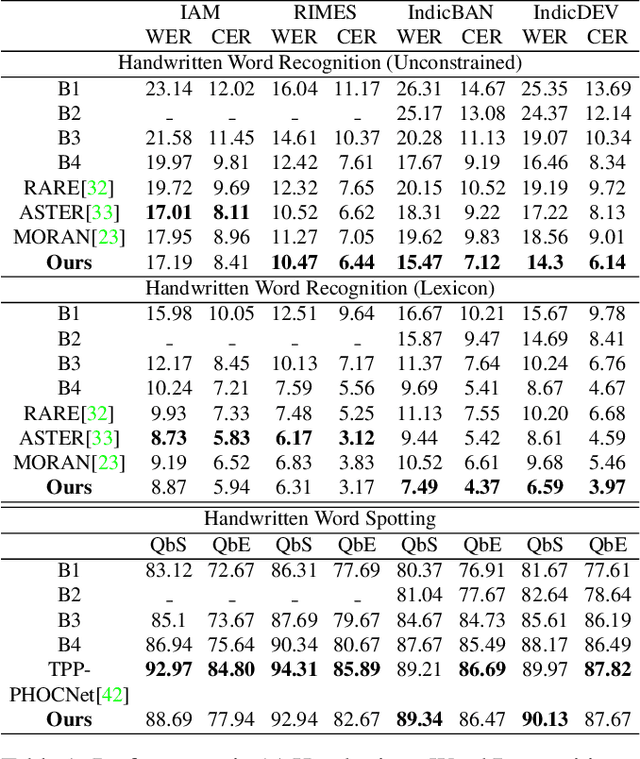
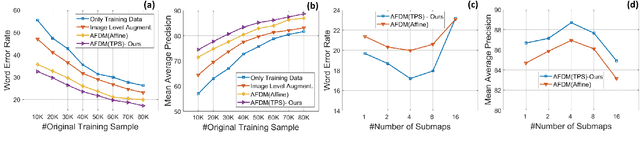

Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten text possessing irregular and complex shapes. Designing models using deep neural networks makes it necessary to extend datasets in order to introduce variances and increase the number of training samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the existing literature use preprocessing strategies which are seldom sufficient to cover all possible variations. We propose the Adversarial Feature Deformation Module that learns ways to elastically warp extracted features in a scalable manner. It is inserted between intermediate layers and trained alternatively with the original framework, boosting its capability to better learn highly informative features rather than trivial ones. We test our meta-framework which is built on top of popular spotting and recognition frameworks and enhanced by the AFDM not only on extensive Latin word datasets, but on sparser Indic scripts too. We record results for varying training data sizes, and observe that our enhanced network generalizes much better in the low-data regime; the overall word-error rates and mAP scores are observed to improve as well.
Query-based Logo Segmentation
Nov 04, 2018
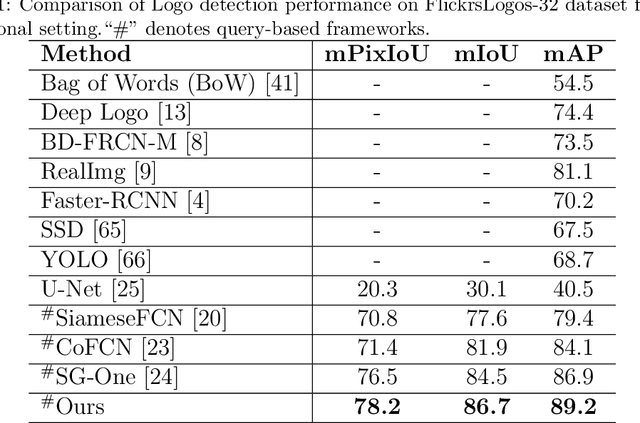
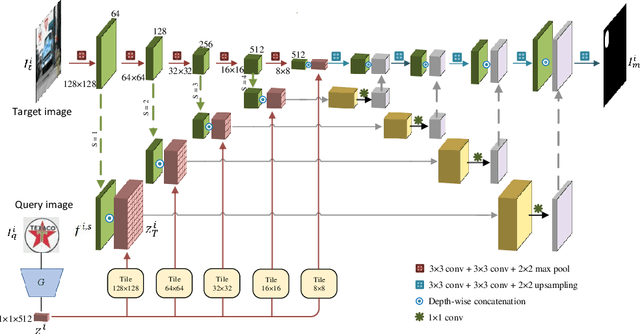
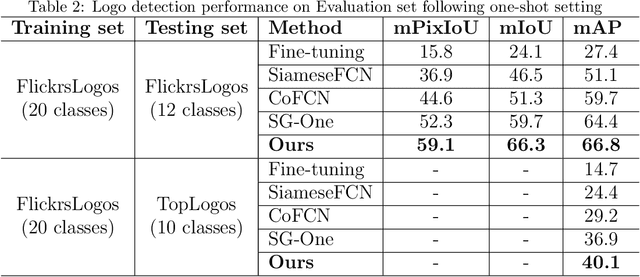
Logo detection in real-world scene images is an important problem with useful applications in advertisement and marketing. Existing general-purpose object detection methods require large training data with bounding box annotations for every logo class. These methods do not satisfy the incremental demand of logo classes necessary for practical deployment as it is practically impossible to have such paired data for every new unseen logo. In this work, we propose a query-based logo search and detection system by employing a one-shot learning technique. Given an image of a query logo, the model searches for it within a given target image and predicts the possible location of the logo by estimating a corresponding binary mask. The proposed model consists of a conditional branch and a segmentation branch. The former gives a conditional representation of a given query logo which is combined with the feature maps at multiple scales of the segmentation branch. The multi-scale conditioning allows our model to obtain a scale-invariant solution. Experimental results reveal that our model can be successfully adapted for any logo classes without separately training the whole network. Also, our query-based logo retrieval framework achieved superior performance in FlickrLogos-32 and TopLogos-10 dataset over existing baselines.
Cogni-Net: Cognitive Feature Learning through Deep Visual Perception
Nov 01, 2018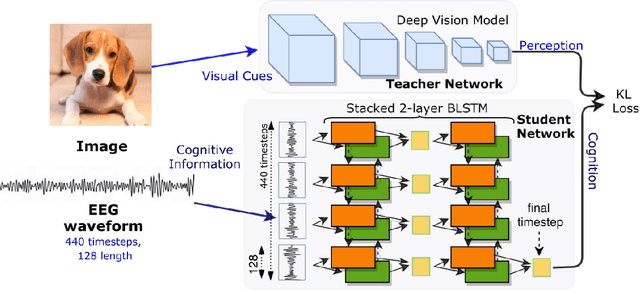

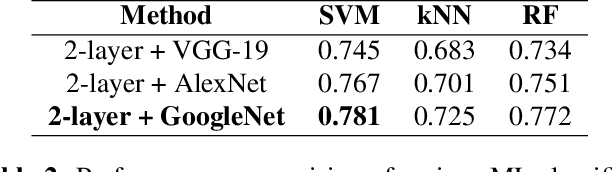
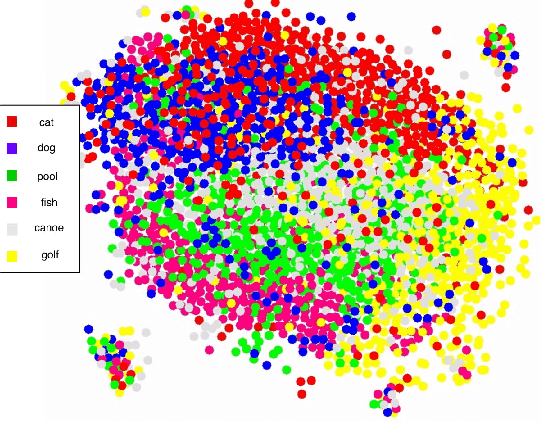
Can we ask computers to recognize what we see from brain signals alone? Our paper seeks to utilize the knowledge learnt in the visual domain by popular pre-trained vision models and use it to teach a recurrent model being trained on brain signals to learn a discriminative manifold of the human brain's cognition of different visual object categories in response to perceived visual cues. For this we make use of brain EEG signals triggered from visual stimuli like images and leverage the natural synchronization between images and their corresponding brain signals to learn a novel representation of the cognitive feature space. The concept of knowledge distillation has been used here for training the deep cognition model, CogniNet\footnote{The source code of the proposed system is publicly available at {https://www.github.com/53X/CogniNET}}, by employing a student-teacher learning technique in order to bridge the process of inter-modal knowledge transfer. The proposed novel architecture obtains state-of-the-art results, significantly surpassing other existing models. The experiments performed by us also suggest that if visual stimuli information like brain EEG signals can be gathered on a large scale, then that would help to obtain a better understanding of the largely unexplored domain of human brain cognition.