 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture Synthesis Guided Deep Hashing for Texture Image Retrieval
Nov 04, 2018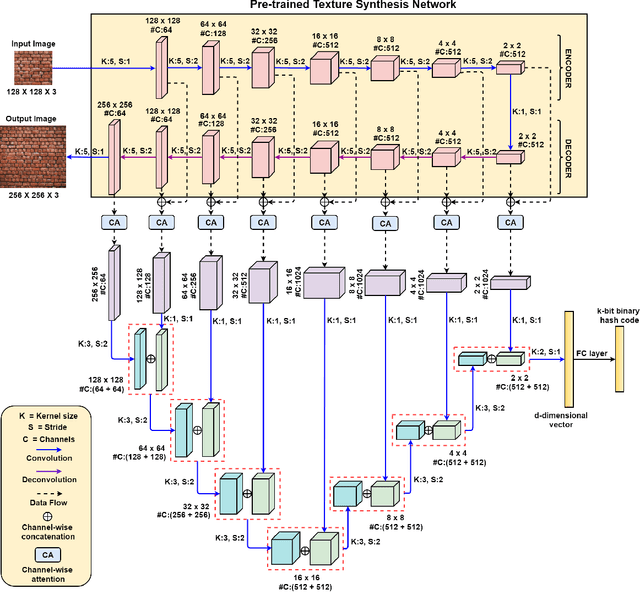
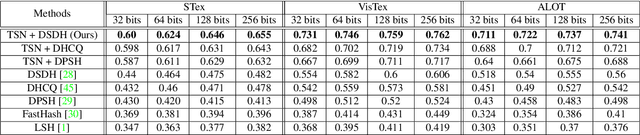

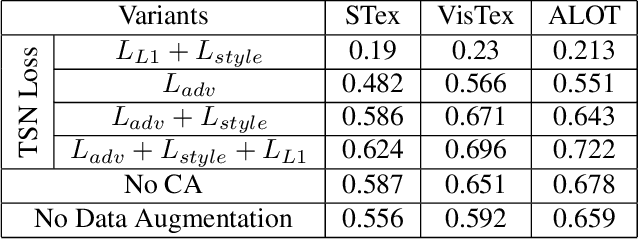
With the large-scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works uses hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN's intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over current state-of-the-art methods.
Cogni-Net: Cognitive Feature Learning through Deep Visual Perception
Nov 01, 2018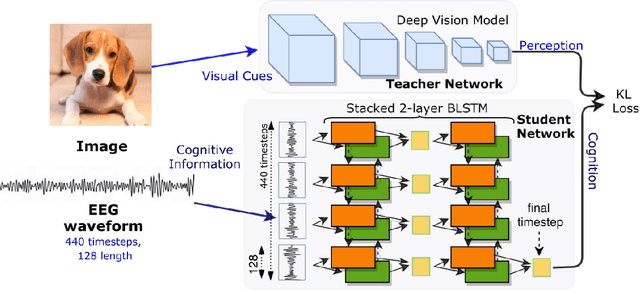

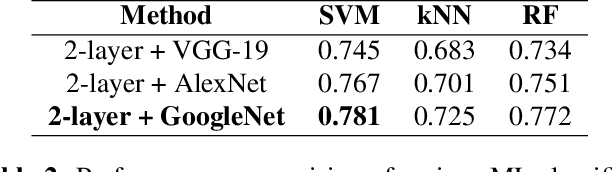
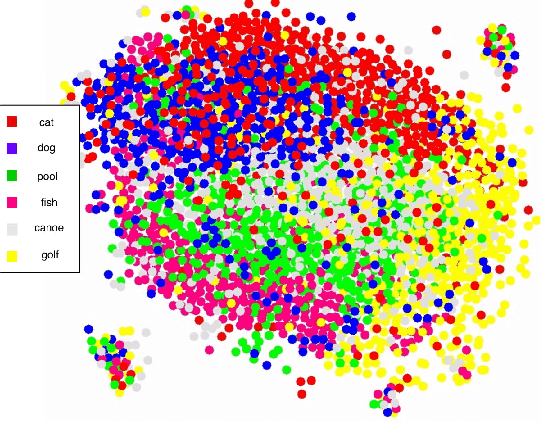
Can we ask computers to recognize what we see from brain signals alone? Our paper seeks to utilize the knowledge learnt in the visual domain by popular pre-trained vision models and use it to teach a recurrent model being trained on brain signals to learn a discriminative manifold of the human brain's cognition of different visual object categories in response to perceived visual cues. For this we make use of brain EEG signals triggered from visual stimuli like images and leverage the natural synchronization between images and their corresponding brain signals to learn a novel representation of the cognitive feature space. The concept of knowledge distillation has been used here for training the deep cognition model, CogniNet\footnote{The source code of the proposed system is publicly available at {https://www.github.com/53X/CogniNET}}, by employing a student-teacher learning technique in order to bridge the process of inter-modal knowledge transfer. The proposed novel architecture obtains state-of-the-art results, significantly surpassing other existing models. The experiments performed by us also suggest that if visual stimuli information like brain EEG signals can be gathered on a large scale, then that would help to obtain a better understanding of the largely unexplored domain of human brain cognition.