 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Framework for Unsupervised Pose Estimation of Occluded Pedestrians
Feb 15, 2020
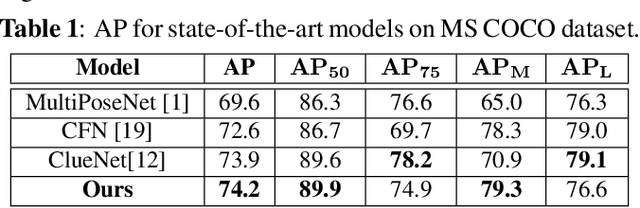
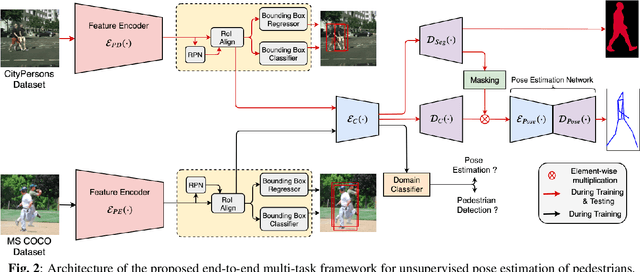

Pose estimation in the wild is a challenging problem, particularly in situations of (i) occlusions of varying degrees and (ii) crowded outdoor scenes. Most of the existing studies of pose estimation did not report the performance in similar situations. Moreover, pose annotations for occluded parts of human figures have not been provided in any of the relevant standard datasets which in turn creates further difficulties to the required studies for pose estimation of the entire figure of occluded humans. Well known pedestrian detection datasets such as CityPersons contains samples of outdoor scenes but it does not include pose annotations. Here, we propose a novel multi-task framework for end-to-end training towards the entire pose estimation of pedestrians including in situations of any kind of occlusion. To tackle this problem for training the network, we make use of a pose estimation dataset, MS-COCO, and employ unsupervised adversarial instance-level domain adaptation for estimating the entire pose of occluded pedestrians. The experimental studies show that the proposed framework outperforms the SOTA results for pose estimation, instance segmentation and pedestrian detection in cases of heavy occlusions (HO) and reasonable + heavy occlusions (R + HO) on the two benchmark datasets.
Texture Synthesis Guided Deep Hashing for Texture Image Retrieval
Nov 04, 2018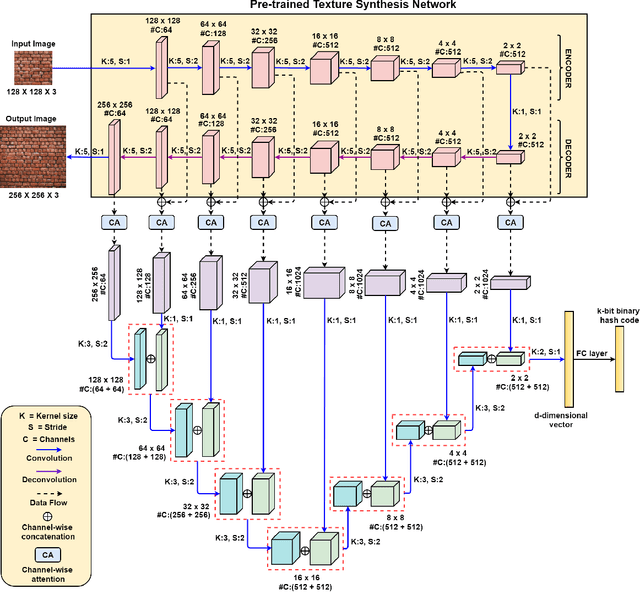
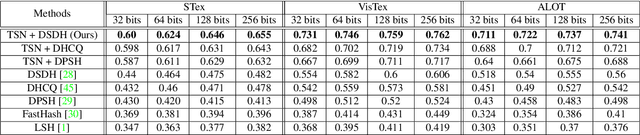

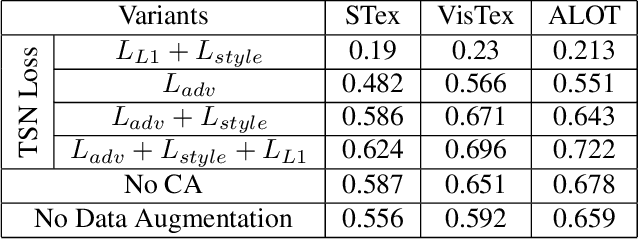
With the large-scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works uses hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN's intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over current state-of-the-art methods.
Handwriting Recognition in Low-resource Scripts using Adversarial Learning
Nov 04, 2018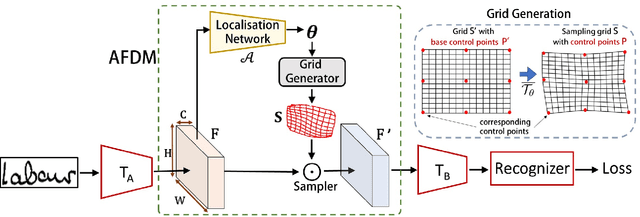
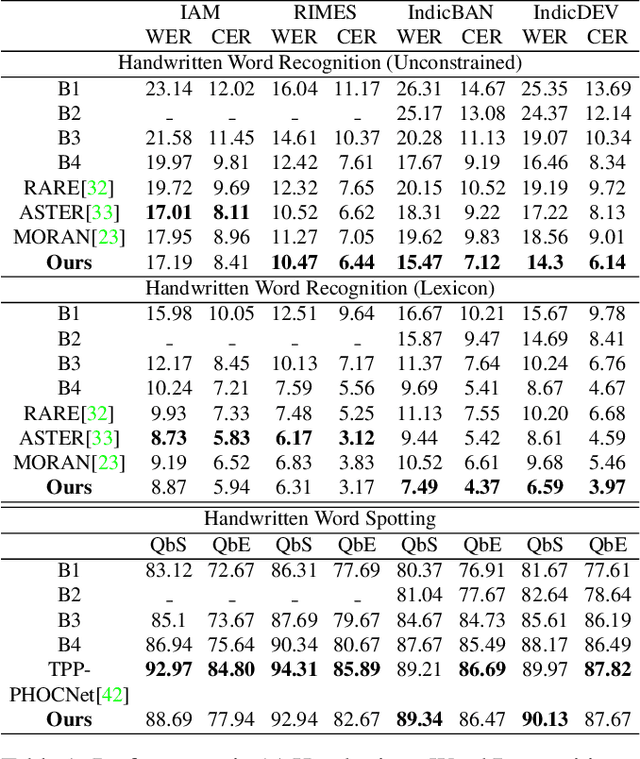
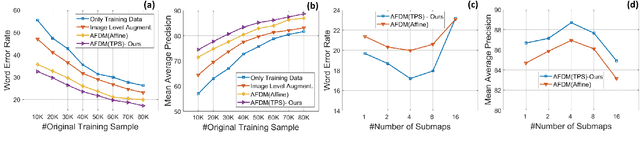

Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten text possessing irregular and complex shapes. Designing models using deep neural networks makes it necessary to extend datasets in order to introduce variances and increase the number of training samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the existing literature use preprocessing strategies which are seldom sufficient to cover all possible variations. We propose the Adversarial Feature Deformation Module that learns ways to elastically warp extracted features in a scalable manner. It is inserted between intermediate layers and trained alternatively with the original framework, boosting its capability to better learn highly informative features rather than trivial ones. We test our meta-framework which is built on top of popular spotting and recognition frameworks and enhanced by the AFDM not only on extensive Latin word datasets, but on sparser Indic scripts too. We record results for varying training data sizes, and observe that our enhanced network generalizes much better in the low-data regime; the overall word-error rates and mAP scores are observed to improve as well.
User Constrained Thumbnail Generation using Adaptive Convolutions
Nov 01, 2018
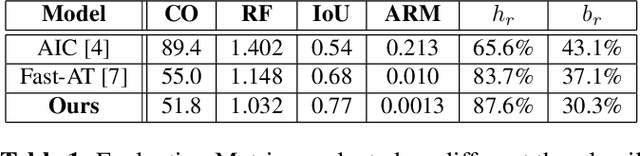
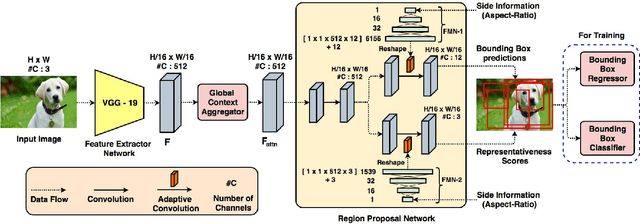

Thumbnails are widely used all over the world as a preview for digital images. In this work we propose a deep neural framework to generate thumbnails of any size and aspect ratio, even for unseen values during training, with high accuracy and precision. We use Global Context Aggregation (GCA) and a modified Region Proposal Network (RPN) with adaptive convolutions to generate thumbnails in real time. GCA is used to selectively attend and aggregate the global context information from the entire image while the RPN is used to predict candidate bounding boxes for the thumbnail image. Adaptive convolution eliminates the problem of generating thumbnails of various aspect ratios by using filter weights dynamically generated from the aspect ratio information. The experimental results indicate the superior performance of the proposed model over existing state-of-the-art techniques.