 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwriting Recognition in Low-resource Scripts using Adversarial Learning
Paper and Code
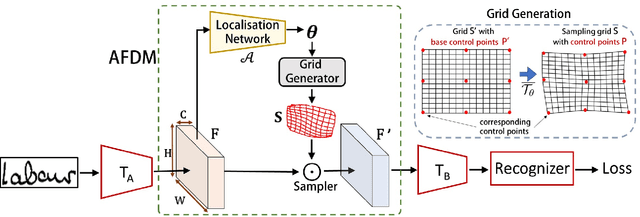
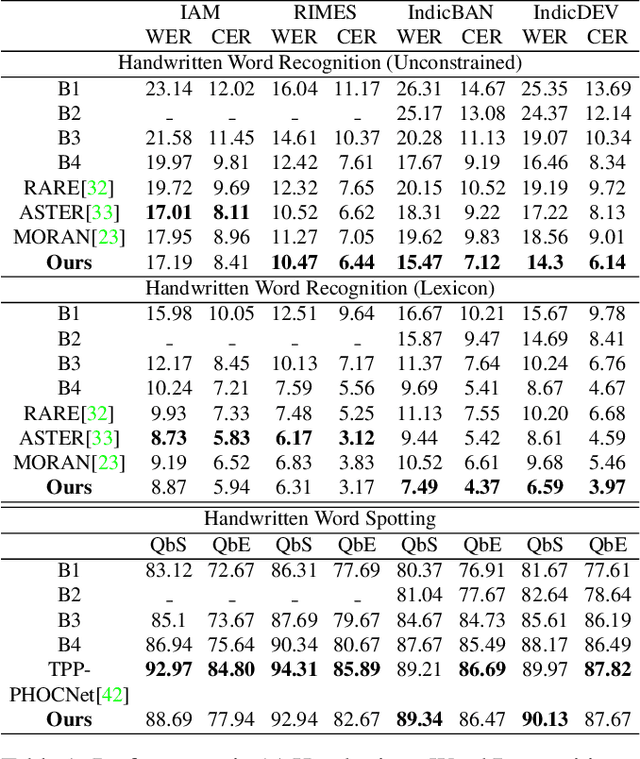
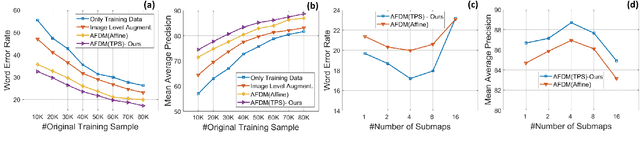

Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten text possessing irregular and complex shapes. Designing models using deep neural networks makes it necessary to extend datasets in order to introduce variances and increase the number of training samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the existing literature use preprocessing strategies which are seldom sufficient to cover all possible variations. We propose the Adversarial Feature Deformation Module that learns ways to elastically warp extracted features in a scalable manner. It is inserted between intermediate layers and trained alternatively with the original framework, boosting its capability to better learn highly informative features rather than trivial ones. We test our meta-framework which is built on top of popular spotting and recognition frameworks and enhanced by the AFDM not only on extensive Latin word datasets, but on sparser Indic scripts too. We record results for varying training data sizes, and observe that our enhanced network generalizes much better in the low-data regime; the overall word-error rates and mAP scores are observed to improve as well.