 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Multiplane Neural Radiance for 3D-Aware Image Generation
Apr 03, 2023
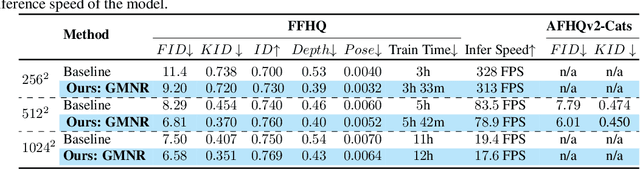


We present a method to efficiently generate 3D-aware high-resolution images that are view-consistent across multiple target views. The proposed multiplane neural radiance model, named GMNR, consists of a novel {\alpha}-guided view-dependent representation ({\alpha}-VdR) module for learning view-dependent information. The {\alpha}-VdR module, faciliated by an {\alpha}-guided pixel sampling technique, computes the view-dependent representation efficiently by learning viewing direction and position coefficients. Moreover, we propose a view-consistency loss to enforce photometric similarity across multiple views. The GMNR model can generate 3D-aware high-resolution images that are viewconsistent across multiple camera poses, while maintaining the computational efficiency in terms of both training and inference time. Experiments on three datasets demonstrate the effectiveness of the proposed modules, leading to favorable results in terms of both generation quality and inference time, compared to existing approaches. Our GMNR model generates 3D-aware images of 1024 X 1024 pixels with 17.6 FPS on a single V100. Code : https://github.com/VIROBO-15/GMNR
Person Image Synthesis via Denoising Diffusion Model
Nov 22, 2022The pose-guided person image generation task requires synthesizing photorealistic images of humans in arbitrary poses. The existing approaches use generative adversarial networks that do not necessarily maintain realistic textures or need dense correspondences that struggle to handle complex deformations and severe occlusions. In this work, we show how denoising diffusion models can be applied for high-fidelity person image synthesis with strong sample diversity and enhanced mode coverage of the learnt data distribution. Our proposed Person Image Diffusion Model (PIDM) disintegrates the complex transfer problem into a series of simpler forward-backward denoising steps. This helps in learning plausible source-to-target transformation trajectories that result in faithful textures and undistorted appearance details. We introduce a 'texture diffusion module' based on cross-attention to accurately model the correspondences between appearance and pose information available in source and target images. Further, we propose 'disentangled classifier-free guidance' to ensure close resemblance between the conditional inputs and the synthesized output in terms of both pose and appearance information. Our extensive results on two large-scale benchmarks and a user study demonstrate the photorealism of our proposed approach under challenging scenarios. We also show how our generated images can help in downstream tasks. Our code and models will be publicly released.
DoodleFormer: Creative Sketch Drawing with Transformers
Dec 06, 2021
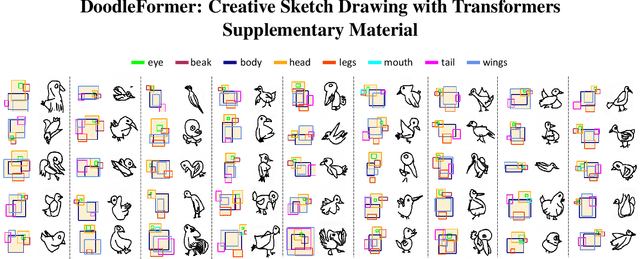
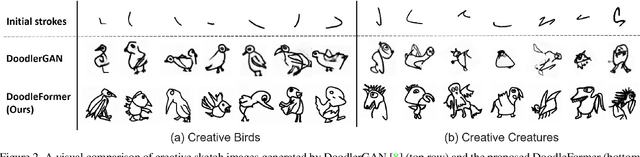

Creative sketching or doodling is an expressive activity, where imaginative and previously unseen depictions of everyday visual objects are drawn. Creative sketch image generation is a challenging vision problem, where the task is to generate diverse, yet realistic creative sketches possessing the unseen composition of the visual-world objects. Here, we propose a novel coarse-to-fine two-stage framework, DoodleFormer, that decomposes the creative sketch generation problem into the creation of coarse sketch composition followed by the incorporation of fine-details in the sketch. We introduce graph-aware transformer encoders that effectively capture global dynamic as well as local static structural relations among different body parts. To ensure diversity of the generated creative sketches, we introduce a probabilistic coarse sketch decoder that explicitly models the variations of each sketch body part to be drawn. Experiments are performed on two creative sketch datasets: Creative Birds and Creative Creatures. Our qualitative, quantitative and human-based evaluations show that DoodleFormer outperforms the state-of-the-art on both datasets, yielding realistic and diverse creative sketches. On Creative Creatures, DoodleFormer achieves an absolute gain of 25 in terms of Fr`echet inception distance (FID) over the state-of-the-art. We also demonstrate the effectiveness of DoodleFormer for related applications of text to creative sketch generation and sketch completion.
Handwriting Transformers
Apr 08, 2021



We propose a novel transformer-based styled handwritten text image generation approach, HWT, that strives to learn both style-content entanglement as well as global and local writing style patterns. The proposed HWT captures the long and short range relationships within the style examples through a self-attention mechanism, thereby encoding both global and local style patterns. Further, the proposed transformer-based HWT comprises an encoder-decoder attention that enables style-content entanglement by gathering the style representation of each query character. To the best of our knowledge, we are the first to introduce a transformer-based generative network for styled handwritten text generation. Our proposed HWT generates realistic styled handwritten text images and significantly outperforms the state-of-the-art demonstrated through extensive qualitative, quantitative and human-based evaluations. The proposed HWT can handle arbitrary length of text and any desired writing style in a few-shot setting. Further, our HWT generalizes well to the challenging scenario where both words and writing style are unseen during training, generating realistic styled handwritten text images.
Query-based Logo Segmentation
Nov 04, 2018
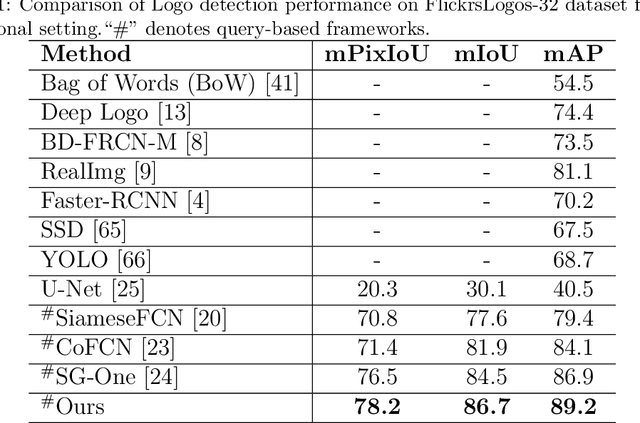
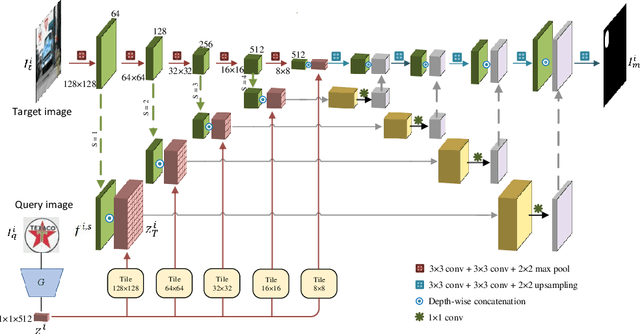
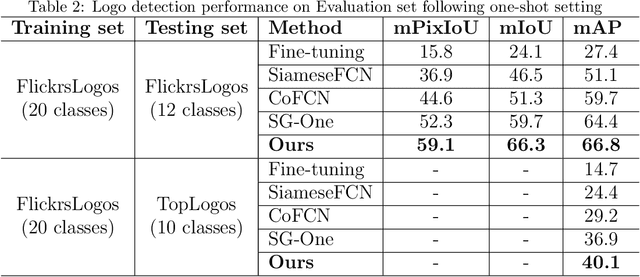
Logo detection in real-world scene images is an important problem with useful applications in advertisement and marketing. Existing general-purpose object detection methods require large training data with bounding box annotations for every logo class. These methods do not satisfy the incremental demand of logo classes necessary for practical deployment as it is practically impossible to have such paired data for every new unseen logo. In this work, we propose a query-based logo search and detection system by employing a one-shot learning technique. Given an image of a query logo, the model searches for it within a given target image and predicts the possible location of the logo by estimating a corresponding binary mask. The proposed model consists of a conditional branch and a segmentation branch. The former gives a conditional representation of a given query logo which is combined with the feature maps at multiple scales of the segmentation branch. The multi-scale conditioning allows our model to obtain a scale-invariant solution. Experimental results reveal that our model can be successfully adapted for any logo classes without separately training the whole network. Also, our query-based logo retrieval framework achieved superior performance in FlickrLogos-32 and TopLogos-10 dataset over existing baselines.
Improving Document Binarization via Adversarial Noise-Texture Augmentation
Oct 25, 2018
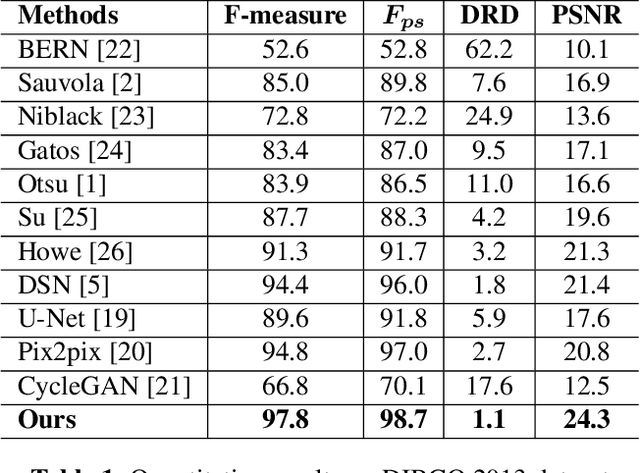


Binarization of degraded document images is an elementary step in most of the problems in document image analysis domain. The paper re-visits the binarization problem by introducing an adversarial learning approach. We construct a Texture Augmentation Network that transfers the texture element of a degraded reference document image to a clean binary image. In this way, the network creates multiple versions of the same textual content with various noisy textures, thus enlarging the available document binarization datasets. At last, the newly generated images are passed through a Binarization network to get back the clean version. By jointly training the two networks we can increase the adversarial robustness of our system. Also, it is noteworthy that our model can learn from unpaired data. Experimental results suggest that the proposed method achieves superior performance over widely used DIBCO datasets.
Script Identification in Natural Scene Image and Video Frame using Attention based Convolutional-LSTM Network
Aug 07, 2018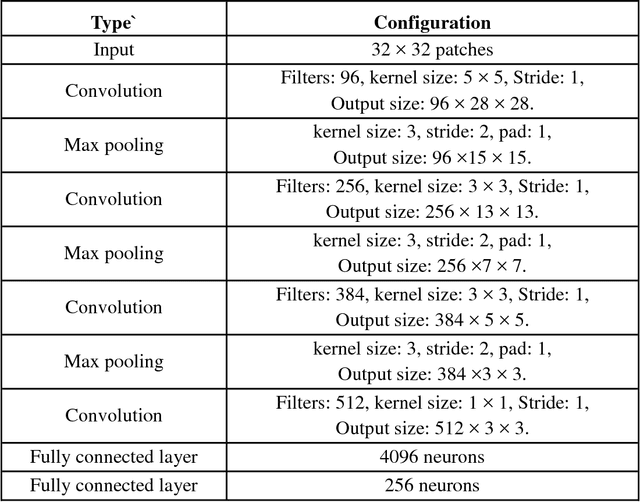



Script identification plays a significant role in analysing documents and videos. In this paper, we focus on the problem of script identification in scene text images and video scripts. Because of low image quality, complex background and similar layout of characters shared by some scripts like Greek, Latin, etc., text recognition in those cases become challenging. In this paper, we propose a novel method that involves extraction of local and global features using CNN-LSTM framework and weighting them dynamically for script identification. First, we convert the images into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these weights with corresponding CNN to yield local features. Global features are also extracted from last cell state of LSTM. We employ a fusion technique which dynamically weights the local and global features for an individual patch. Experiments have been done in four public script identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework achieves superior results in comparison to conventional methods.
Staff line Removal using Generative Adversarial Networks
Jun 05, 2018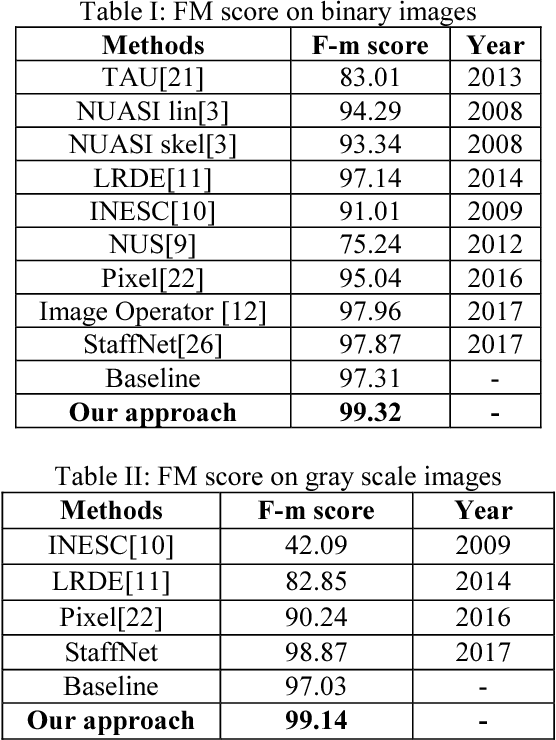

Staff line removal is a crucial pre-processing step in Optical Music Recognition. It is a challenging task to simultaneously reduce the noise and also retain the quality of music symbol context in ancient degraded music score images. In this paper we propose a novel approach for staff line removal, based on Generative Adversarial Networks. We convert staff line images into patches and feed them into a U-Net, used as Generator. The Generator intends to produce staff-less images at the output. Then the Discriminator does binary classification and differentiates between the generated fake staff-less image and real ground truth staff less image. For training, we use a Loss function which is a weighted combination of L2 loss and Adversarial loss. L2 loss minimizes the difference between real and fake staff-less image. Adversarial loss helps to retrieve more high quality textures in generated images. Thus our architecture supports solutions which are closer to ground truth and it reflects in our results. For evaluation we consider the ICDAR/GREC 2013 staff removal database. Our method achieves superior performance in comparison to other conventional approaches.
Handwriting Trajectory Recovery using End-to-End Deep Encoder-Decoder Network
Jun 03, 2018
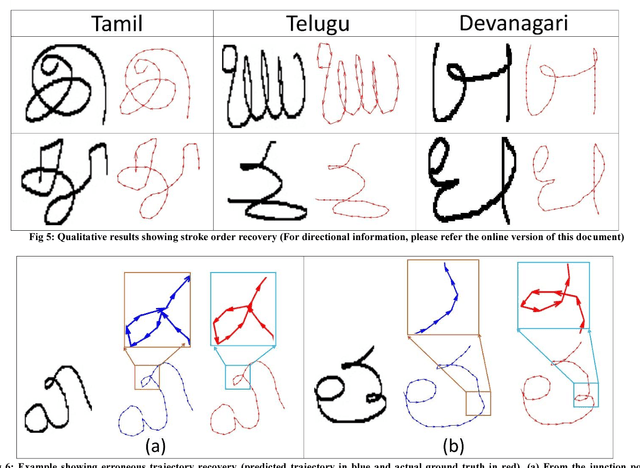

In this paper, we introduce a novel technique to recover the pen trajectory of offline characters which is a crucial step for handwritten character recognition. Generally, online acquisition approach has more advantage than its offline counterpart as the online technique keeps track of the pen movement. Hence, pen tip trajectory retrieval from offline text can bridge the gap between online and offline methods. Our proposed framework employs sequence to sequence model which consists of an encoder-decoder LSTM module. Our encoder module consists of Convolutional LSTM network, which takes an offline character image as the input and encodes the feature sequence to a hidden representation. The output of the encoder is fed to a decoder LSTM and we get the successive coordinate points from every time step of the decoder LSTM. Although the sequence to sequence model is a popular paradigm in various computer vision and language translation tasks, the main contribution of our work lies in designing an end-to-end network for a decade old popular problem in Document Image Analysis community. Tamil, Telugu and Devanagari characters of LIPI Toolkit dataset are used for our experiments. Our proposed method has achieved superior performance compared to the other conventional approaches.
Word Level Font-to-Font Image Translation using Convolutional Recurrent Generative Adversarial Networks
May 24, 2018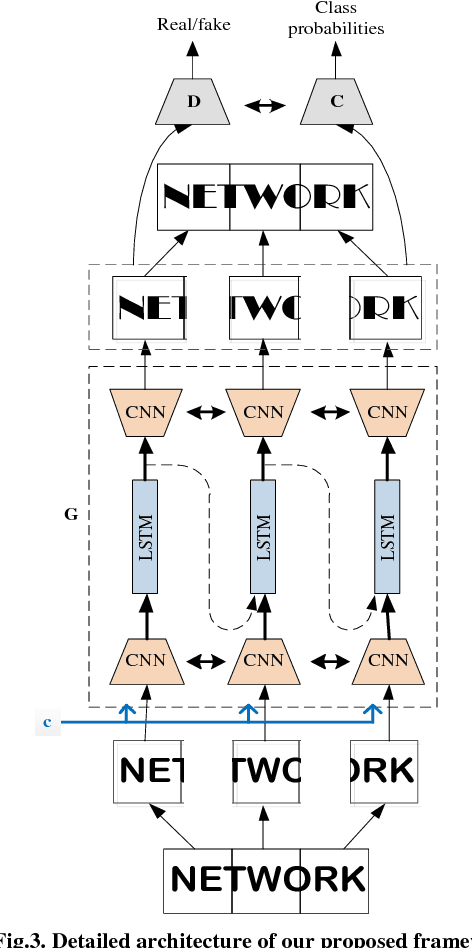
Conversion of one font to another font is very useful in real life applications. In this paper, we propose a Convolutional Recurrent Generative model to solve the word level font transfer problem. Our network is able to convert the font style of any printed text images from its current font to the required font. The network is trained end-to-end for the complete word images. Thus it eliminates the necessary pre-processing steps, like character segmentations. We extend our model to conditional setting that helps to learn one-to-many mapping function. We employ a novel convolutional recurrent model architecture in the Generator that efficiently deals with the word images of arbitrary width. It also helps to maintain the consistency of the final images after concatenating the generated image patches of target font. Besides, the Generator and the Discriminator network, we employ a Classification network to classify the generated word images of converted font style to their subsequent font categories. Most of the earlier works related to image translation are performed on square images. Our proposed architecture is the first work which can handle images of varying widths. Word images generally have varying width depending on the number of characters present. Hence, we test our model on a synthetically generated font dataset. We compare our method with some of the state-of-the-art methods for image translation. The superior performance of our network on the same dataset proves the ability of our model to learn the font distributions.