 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScript Identification in Natural Scene Image and Video Frame using Attention based Convolutional-LSTM Network
Paper and Code
Aug 07, 2018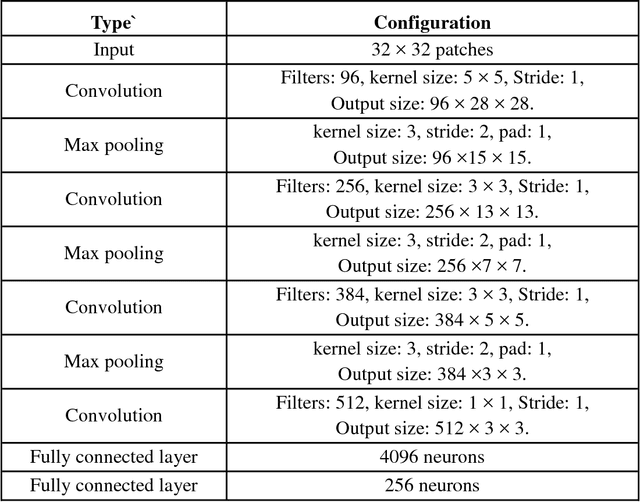



Script identification plays a significant role in analysing documents and videos. In this paper, we focus on the problem of script identification in scene text images and video scripts. Because of low image quality, complex background and similar layout of characters shared by some scripts like Greek, Latin, etc., text recognition in those cases become challenging. In this paper, we propose a novel method that involves extraction of local and global features using CNN-LSTM framework and weighting them dynamically for script identification. First, we convert the images into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these weights with corresponding CNN to yield local features. Global features are also extracted from last cell state of LSTM. We employ a fusion technique which dynamically weights the local and global features for an individual patch. Experiments have been done in four public script identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework achieves superior results in comparison to conventional methods.