 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing SAM with Efficient Prompting and Preference Optimization for Semi-supervised Medical Image Segmentation
Mar 06, 2025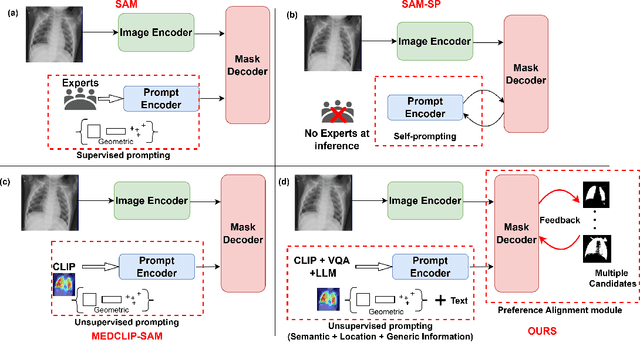
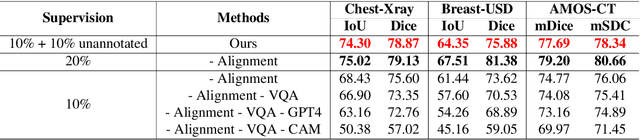
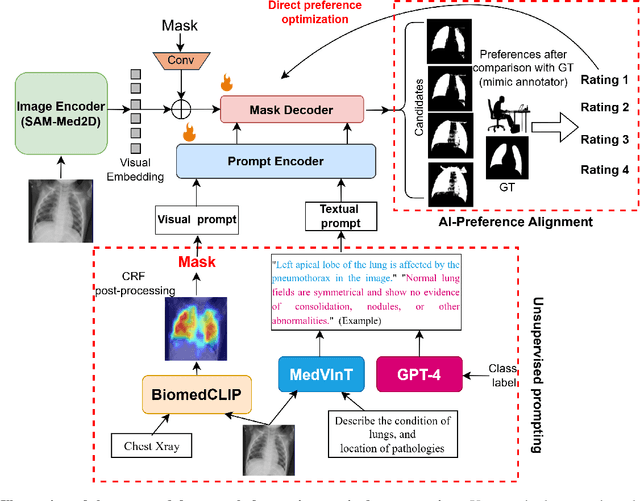
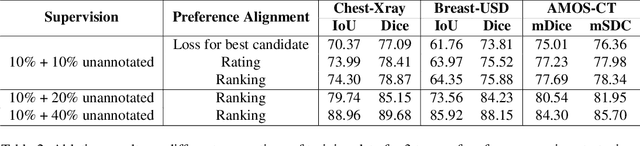
Foundational models such as the Segment Anything Model (SAM) are gaining traction in medical imaging segmentation, supporting multiple downstream tasks. However, such models are supervised in nature, still relying on large annotated datasets or prompts supplied by experts. Conventional techniques such as active learning to alleviate such limitations are limited in scope and still necessitate continuous human involvement and complex domain knowledge for label refinement or establishing reward ground truth. To address these challenges, we propose an enhanced Segment Anything Model (SAM) framework that utilizes annotation-efficient prompts generated in a fully unsupervised fashion, while still capturing essential semantic, location, and shape information through contrastive language-image pretraining and visual question answering. We adopt the direct preference optimization technique to design an optimal policy that enables the model to generate high-fidelity segmentations with simple ratings or rankings provided by a virtual annotator simulating the human annotation process. State-of-the-art performance of our framework in tasks such as lung segmentation, breast tumor segmentation, and organ segmentation across various modalities, including X-ray, ultrasound, and abdominal CT, justifies its effectiveness in low-annotation data scenarios.
Enhancing Modality-Agnostic Representations via Meta-Learning for Brain Tumor Segmentation
Feb 08, 2023



In the medical vision domain, different imaging modalities provide complementary information. However, in practice, not all modalities may be available during inference. Previous approaches, e.g., knowledge distillation or image synthesis, often assume the availability of full modalities for all patients during training; this is unrealistic and impractical owing to the variability in data collection across sites. We propose a novel approach to learn enhanced modality-agnostic representations by employing a novel meta-learning strategy in training, even when only a fraction of full modality patients are available. Meta-learning enhances partial modality representations to full modality representations by meta-training on partial modality data and meta-testing on limited full modality samples. Additionally, we co-supervise this feature enrichment by introducing an auxiliary adversarial learning branch. More specifically, a missing modality detector is used as a discriminator to mimic the full modality setting. Our segmentation framework significantly outperforms state-of-the-art brain tumor segmentation techniques in missing modality scenarios, as demonstrated on two brain tumor MRI datasets.
Temporal Context Matters: Enhancing Single Image Prediction with Disease Progression Representations
Mar 31, 2022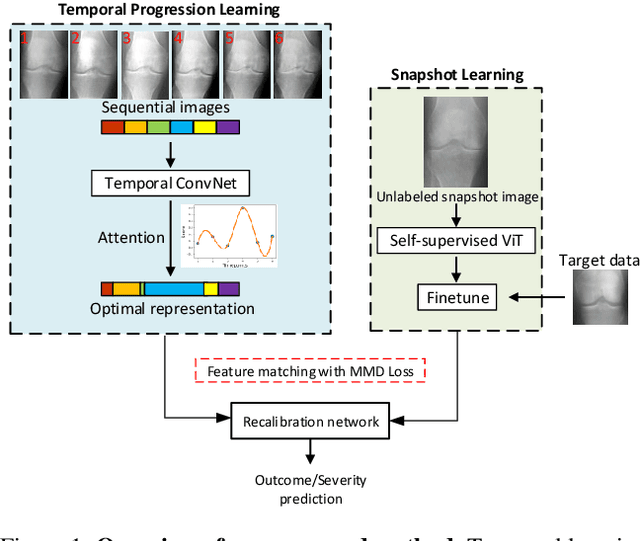

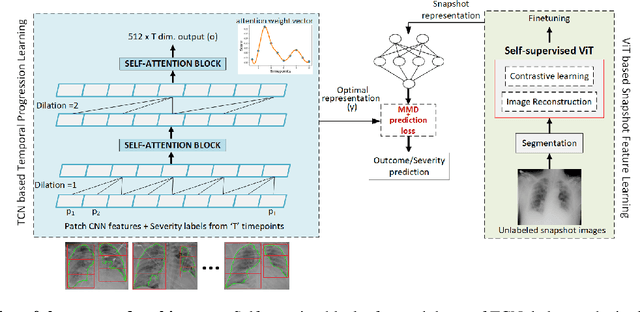
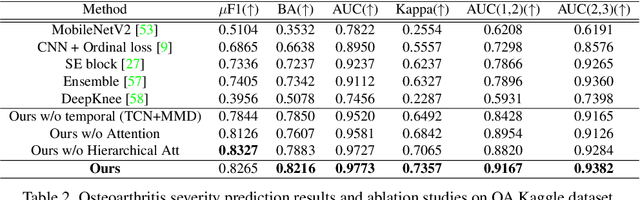
Clinical outcome or severity prediction from medical images has largely focused on learning representations from single-timepoint or snapshot scans. It has been shown that disease progression can be better characterized by temporal imaging. We therefore hypothesized that outcome predictions can be improved by utilizing the disease progression information from sequential images. We present a deep learning approach that leverages temporal progression information to improve clinical outcome predictions from single-timepoint images. In our method, a self-attention based Temporal Convolutional Network (TCN) is used to learn a representation that is most reflective of the disease trajectory. Meanwhile, a Vision Transformer is pretrained in a self-supervised fashion to extract features from single-timepoint images. The key contribution is to design a recalibration module that employs maximum mean discrepancy loss (MMD) to align distributions of the above two contextual representations. We train our system to predict clinical outcomes and severity grades from single-timepoint images. Experiments on chest and osteoarthritis radiography datasets demonstrate that our approach outperforms other state-of-the-art techniques.
Attention-based Multi-scale Gated Recurrent Encoder with Novel Correlation Loss for COVID-19 Progression Prediction
Jul 18, 2021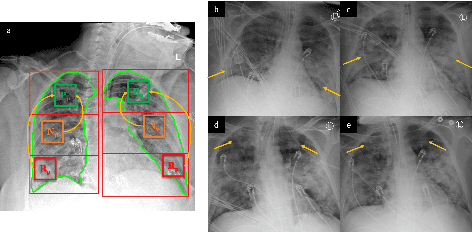


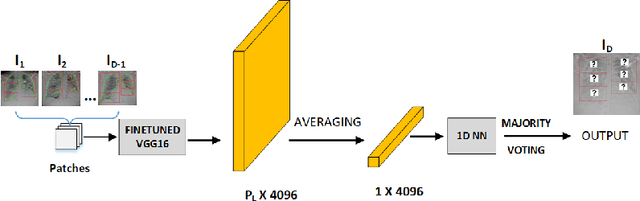
COVID-19 image analysis has mostly focused on diagnostic tasks using single timepoint scans acquired upon disease presentation or admission. We present a deep learning-based approach to predict lung infiltrate progression from serial chest radiographs (CXRs) of COVID-19 patients. Our method first utilizes convolutional neural networks (CNNs) for feature extraction from patches within the concerned lung zone, and also from neighboring and remote boundary regions. The framework further incorporates a multi-scale Gated Recurrent Unit (GRU) with a correlation module for effective predictions. The GRU accepts CNN feature vectors from three different areas as input and generates a fused representation. The correlation module attempts to minimize the correlation loss between hidden representations of concerned and neighboring area feature vectors, while maximizing the loss between the same from concerned and remote regions. Further, we employ an attention module over the output hidden states of each encoder timepoint to generate a context vector. This vector is used as an input to a decoder module to predict patch severity grades at a future timepoint. Finally, we ensemble the patch classification scores to calculate patient-wise grades. Specifically, our framework predicts zone-wise disease severity for a patient on a given day by learning representations from the previous temporal CXRs. Our novel multi-institutional dataset comprises sequential CXR scans from N=93 patients. Our approach outperforms transfer learning and radiomic feature-based baseline approaches on this dataset.
Facial Micro-Expression Spotting and Recognition using Time Contrasted Feature with Visual Memory
Feb 09, 2019
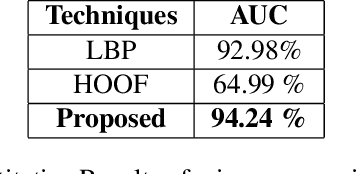


Facial micro-expressions are sudden involuntary minute muscle movements which reveal true emotions that people try to conceal. Spotting a micro-expression and recognizing it is a major challenge owing to its short duration and intensity. Many works pursued traditional and deep learning based approaches to solve this issue but compromised on learning low-level features and higher accuracy due to unavailability of datasets. This motivated us to propose a novel joint architecture of spatial and temporal network which extracts time-contrasted features from the feature maps to contrast out micro-expression from rapid muscle movements. The usage of time contrasted features greatly improved the spotting of micro-expression from inconspicuous facial movements. Also, we include a memory module to predict the class and intensity of the micro-expression across the temporal frames of the micro-expression clip. Our method achieves superior performance in comparison to other conventional approaches on CASMEII dataset.
Script Identification in Natural Scene Image and Video Frame using Attention based Convolutional-LSTM Network
Aug 07, 2018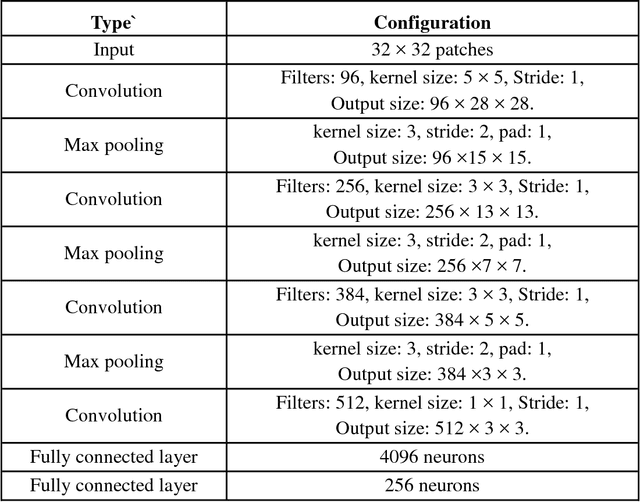



Script identification plays a significant role in analysing documents and videos. In this paper, we focus on the problem of script identification in scene text images and video scripts. Because of low image quality, complex background and similar layout of characters shared by some scripts like Greek, Latin, etc., text recognition in those cases become challenging. In this paper, we propose a novel method that involves extraction of local and global features using CNN-LSTM framework and weighting them dynamically for script identification. First, we convert the images into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these weights with corresponding CNN to yield local features. Global features are also extracted from last cell state of LSTM. We employ a fusion technique which dynamically weights the local and global features for an individual patch. Experiments have been done in four public script identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework achieves superior results in comparison to conventional methods.
Staff line Removal using Generative Adversarial Networks
Jun 05, 2018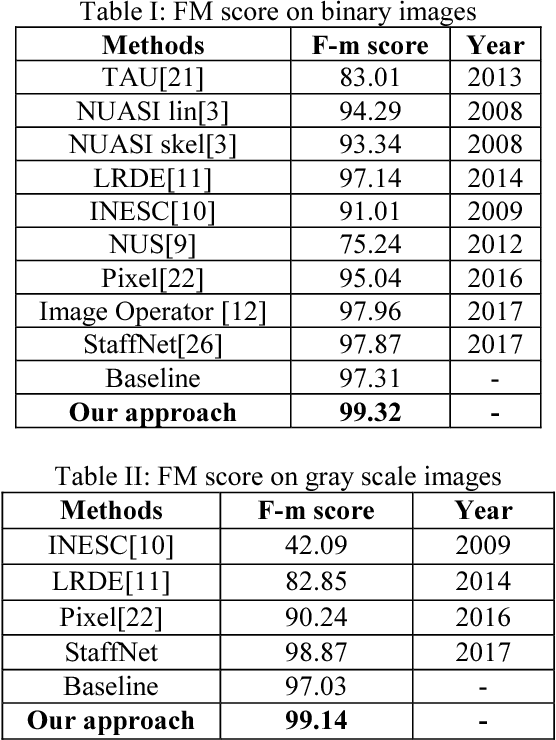

Staff line removal is a crucial pre-processing step in Optical Music Recognition. It is a challenging task to simultaneously reduce the noise and also retain the quality of music symbol context in ancient degraded music score images. In this paper we propose a novel approach for staff line removal, based on Generative Adversarial Networks. We convert staff line images into patches and feed them into a U-Net, used as Generator. The Generator intends to produce staff-less images at the output. Then the Discriminator does binary classification and differentiates between the generated fake staff-less image and real ground truth staff less image. For training, we use a Loss function which is a weighted combination of L2 loss and Adversarial loss. L2 loss minimizes the difference between real and fake staff-less image. Adversarial loss helps to retrieve more high quality textures in generated images. Thus our architecture supports solutions which are closer to ground truth and it reflects in our results. For evaluation we consider the ICDAR/GREC 2013 staff removal database. Our method achieves superior performance in comparison to other conventional approaches.
Handwriting Trajectory Recovery using End-to-End Deep Encoder-Decoder Network
Jun 03, 2018
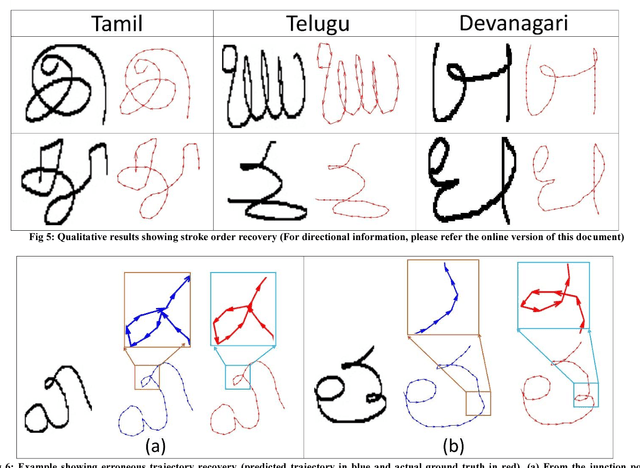
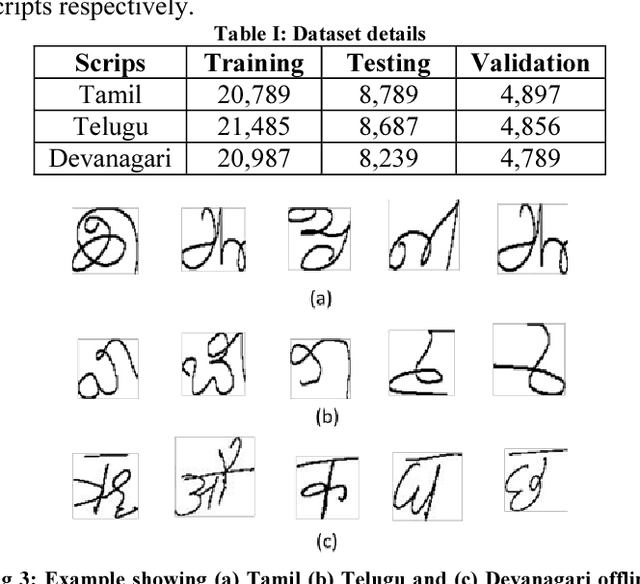

In this paper, we introduce a novel technique to recover the pen trajectory of offline characters which is a crucial step for handwritten character recognition. Generally, online acquisition approach has more advantage than its offline counterpart as the online technique keeps track of the pen movement. Hence, pen tip trajectory retrieval from offline text can bridge the gap between online and offline methods. Our proposed framework employs sequence to sequence model which consists of an encoder-decoder LSTM module. Our encoder module consists of Convolutional LSTM network, which takes an offline character image as the input and encodes the feature sequence to a hidden representation. The output of the encoder is fed to a decoder LSTM and we get the successive coordinate points from every time step of the decoder LSTM. Although the sequence to sequence model is a popular paradigm in various computer vision and language translation tasks, the main contribution of our work lies in designing an end-to-end network for a decade old popular problem in Document Image Analysis community. Tamil, Telugu and Devanagari characters of LIPI Toolkit dataset are used for our experiments. Our proposed method has achieved superior performance compared to the other conventional approaches.
Word Level Font-to-Font Image Translation using Convolutional Recurrent Generative Adversarial Networks
May 24, 2018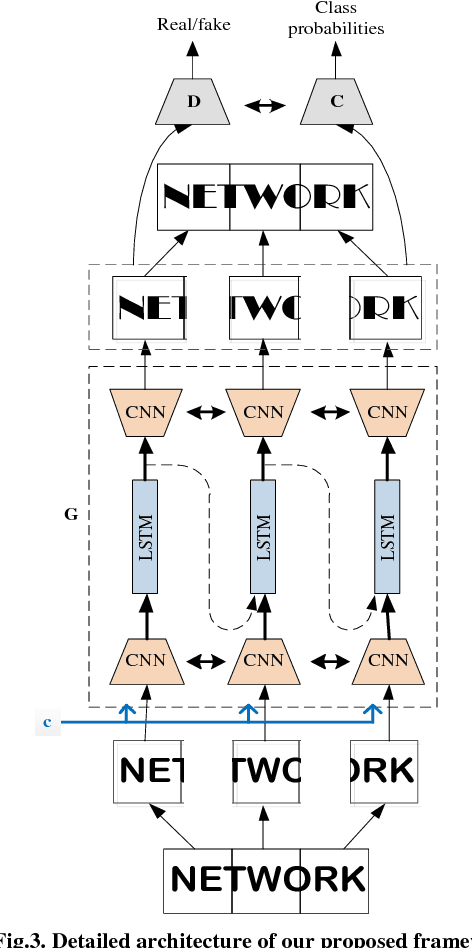
Conversion of one font to another font is very useful in real life applications. In this paper, we propose a Convolutional Recurrent Generative model to solve the word level font transfer problem. Our network is able to convert the font style of any printed text images from its current font to the required font. The network is trained end-to-end for the complete word images. Thus it eliminates the necessary pre-processing steps, like character segmentations. We extend our model to conditional setting that helps to learn one-to-many mapping function. We employ a novel convolutional recurrent model architecture in the Generator that efficiently deals with the word images of arbitrary width. It also helps to maintain the consistency of the final images after concatenating the generated image patches of target font. Besides, the Generator and the Discriminator network, we employ a Classification network to classify the generated word images of converted font style to their subsequent font categories. Most of the earlier works related to image translation are performed on square images. Our proposed architecture is the first work which can handle images of varying widths. Word images generally have varying width depending on the number of characters present. Hence, we test our model on a synthetically generated font dataset. We compare our method with some of the state-of-the-art methods for image translation. The superior performance of our network on the same dataset proves the ability of our model to learn the font distributions.