 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Multiplane Neural Radiance for 3D-Aware Image Generation
Paper and Code

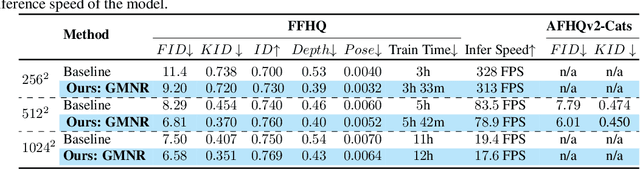


We present a method to efficiently generate 3D-aware high-resolution images that are view-consistent across multiple target views. The proposed multiplane neural radiance model, named GMNR, consists of a novel {\alpha}-guided view-dependent representation ({\alpha}-VdR) module for learning view-dependent information. The {\alpha}-VdR module, faciliated by an {\alpha}-guided pixel sampling technique, computes the view-dependent representation efficiently by learning viewing direction and position coefficients. Moreover, we propose a view-consistency loss to enforce photometric similarity across multiple views. The GMNR model can generate 3D-aware high-resolution images that are viewconsistent across multiple camera poses, while maintaining the computational efficiency in terms of both training and inference time. Experiments on three datasets demonstrate the effectiveness of the proposed modules, leading to favorable results in terms of both generation quality and inference time, compared to existing approaches. Our GMNR model generates 3D-aware images of 1024 X 1024 pixels with 17.6 FPS on a single V100. Code : https://github.com/VIROBO-15/GMNR