 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure and Explainable Fraud Detection in Finance via Hierarchical Multi-source Dataset Distillation
Dec 26, 2025We propose an explainable, privacy-preserving dataset distillation framework for collaborative financial fraud detection. A trained random forest is converted into transparent, axis-aligned rule regions (leaf hyperrectangles), and synthetic transactions are generated by uniformly sampling within each region. This produces a compact, auditable surrogate dataset that preserves local feature interactions without exposing sensitive original records. The rule regions also support explainability: aggregated rule statistics (for example, support and lift) describe global patterns, while assigning each case to its generating region gives concise human-readable rationales and calibrated uncertainty based on tree-vote disagreement. On the IEEE-CIS fraud dataset (590k transactions across three institution-like clusters), distilled datasets reduce data volume by 85% to 93% (often under 15% of the original) while maintaining competitive precision and micro-F1, with only a modest AUC drop. Sharing and augmenting with synthesized data across institutions improves cross-cluster precision, recall, and AUC. Real vs. synthesized structure remains highly similar (over 93% by nearest-neighbor cosine analysis). Membership-inference attacks perform at chance level (about 0.50) when distinguishing training from hold-out records, suggesting low memorization risk. Removing high-uncertainty synthetic points using disagreement scores further boosts AUC (up to 0.687) and improves calibration. Sensitivity tests show weak dependence on the distillation ratio (AUC about 0.641 to 0.645 from 6% to 60%). Overall, tree-region distillation enables trustworthy, deployable fraud analytics with interpretable global rules, per-case rationales with quantified uncertainty, and strong privacy properties suitable for multi-institution settings and regulatory audit.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


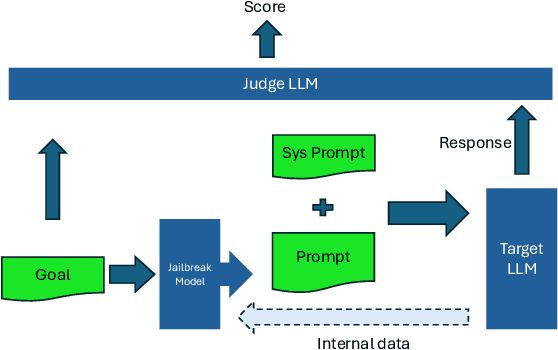
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
CLIP-based Point Cloud Classification via Point Cloud to Image Translation
Aug 07, 2024



Point cloud understanding is an inherently challenging problem because of the sparse and unordered structure of the point cloud in the 3D space. Recently, Contrastive Vision-Language Pre-training (CLIP) based point cloud classification model i.e. PointCLIP has added a new direction in the point cloud classification research domain. In this method, at first multi-view depth maps are extracted from the point cloud and passed through the CLIP visual encoder. To transfer the 3D knowledge to the network, a small network called an adapter is fine-tuned on top of the CLIP visual encoder. PointCLIP has two limitations. Firstly, the point cloud depth maps lack image information which is essential for tasks like classification and recognition. Secondly, the adapter only relies on the global representation of the multi-view features. Motivated by this observation, we propose a Pretrained Point Cloud to Image Translation Network (PPCITNet) that produces generalized colored images along with additional salient visual cues to the point cloud depth maps so that it can achieve promising performance on point cloud classification and understanding. In addition, we propose a novel viewpoint adapter that combines the view feature processed by each viewpoint as well as the global intertwined knowledge that exists across the multi-view features. The experimental results demonstrate the superior performance of the proposed model over existing state-of-the-art CLIP-based models on ModelNet10, ModelNet40, and ScanobjectNN datasets.
DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models
Aug 06, 2024



Large language models (LLMs) have recently showcased remarkable capabilities, spanning a wide range of tasks and applications, including those in the medical domain. Models like GPT-4 excel in medical question answering but may face challenges in the lack of interpretability when handling complex tasks in real clinical settings. We thus introduce the diagnostic reasoning dataset for clinical notes (DiReCT), aiming at evaluating the reasoning ability and interpretability of LLMs compared to human doctors. It contains 511 clinical notes, each meticulously annotated by physicians, detailing the diagnostic reasoning process from observations in a clinical note to the final diagnosis. Additionally, a diagnostic knowledge graph is provided to offer essential knowledge for reasoning, which may not be covered in the training data of existing LLMs. Evaluations of leading LLMs on DiReCT bring out a significant gap between their reasoning ability and that of human doctors, highlighting the critical need for models that can reason effectively in real-world clinical scenarios.
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Apr 12, 2024


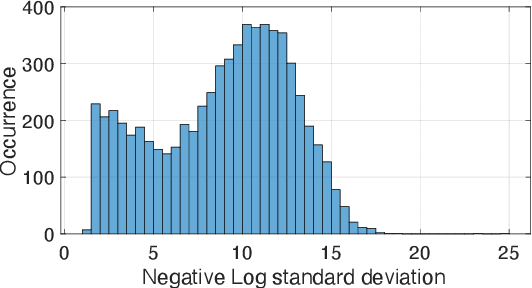
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
DPA-Net: Structured 3D Abstraction from Sparse Views via Differentiable Primitive Assembly
Apr 02, 2024
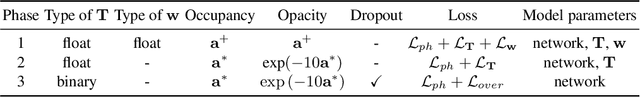

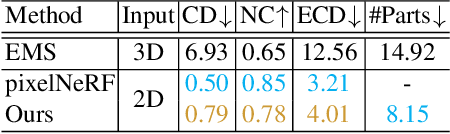
We present a differentiable rendering framework to learn structured 3D abstractions in the form of primitive assemblies from sparse RGB images capturing a 3D object. By leveraging differentiable volume rendering, our method does not require 3D supervision. Architecturally, our network follows the general pipeline of an image-conditioned neural radiance field (NeRF) exemplified by pixelNeRF for color prediction. As our core contribution, we introduce differential primitive assembly (DPA) into NeRF to output a 3D occupancy field in place of density prediction, where the predicted occupancies serve as opacity values for volume rendering. Our network, coined DPA-Net, produces a union of convexes, each as an intersection of convex quadric primitives, to approximate the target 3D object, subject to an abstraction loss and a masking loss, both defined in the image space upon volume rendering. With test-time adaptation and additional sampling and loss designs aimed at improving the accuracy and compactness of the obtained assemblies, our method demonstrates superior performance over state-of-the-art alternatives for 3D primitive abstraction from sparse views.
SEER: Facilitating Structured Reasoning and Explanation via Reinforcement Learning
Jan 24, 2024Elucidating the reasoning process with structured explanations from question to answer is fundamentally crucial, as it significantly enhances the interpretability and trustworthiness of question-answering (QA) systems. However, structured explanations demand models to perform intricate structured reasoning, which poses great challenges. Most existing methods focus on single-step reasoning through supervised learning, ignoring logical dependencies between steps. Meanwhile, existing reinforcement learning (RL)-based methods overlook the structured relationships, impeding RL's potential in structured reasoning. In this paper, we propose SEER, a novel method that maximizes a structure-based return to facilitate structured reasoning and explanation. Our proposed structure-based return precisely describes the hierarchical and branching structure inherent in structured reasoning, effectively capturing the intricate relationships between states. We also introduce a fine-grained reward function to meticulously delineate diverse reasoning steps. Extensive experiments show that SEER significantly outperforms state-of-the-art methods, achieving an absolute improvement of 6.9% over RL-based methods on EntailmentBank, a 4.4% average improvement on STREET benchmark, and exhibiting outstanding efficiency and cross-dataset generalization performance.
MPrompt: Exploring Multi-level Prompt Tuning for Machine Reading Comprehension
Oct 27, 2023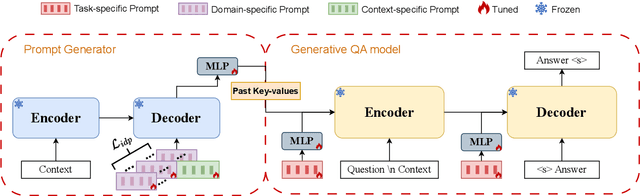



The large language models have achieved superior performance on various natural language tasks. One major drawback of such approaches is they are resource-intensive in fine-tuning new datasets. Soft-prompt tuning presents a resource-efficient solution to fine-tune the pre-trained language models (PLMs) while keeping their weight frozen. Existing soft prompt methods mainly focus on designing the input-independent prompts that steer the model to fit the domain of the new dataset. Those methods often ignore the fine-grained information about the task and context of the text. In this paper, we propose a multi-level prompt tuning (MPrompt) method for machine reading comprehension. It utilizes prompts at task-specific, domain-specific, and context-specific levels to enhance the comprehension of input semantics at different granularities. We also propose an independence constraint to steer each domain-specific prompt to focus on information within its domain to avoid redundancy. Moreover, we present a prompt generator that incorporates context-related knowledge in the prompt generation to enhance contextual relevancy. We conducted extensive experiments on 12 benchmarks of various QA formats and achieved an average improvement of 1.94\% over the state-of-the-art methods.
TCRA-LLM: Token Compression Retrieval Augmented Large Language Model for Inference Cost Reduction
Oct 25, 2023Since ChatGPT released its API for public use, the number of applications built on top of commercial large language models (LLMs) increase exponentially. One popular usage of such models is leveraging its in-context learning ability and generating responses given user queries leveraging knowledge obtained by retrieval augmentation. One problem of deploying commercial retrieval-augmented LLMs is the cost due to the additionally retrieved context that largely increases the input token size of the LLMs. To mitigate this, we propose a token compression scheme that includes two methods: summarization compression and semantic compression. The first method applies a T5-based model that is fine-tuned by datasets generated using self-instruct containing samples with varying lengths and reduce token size by doing summarization. The second method further compresses the token size by removing words with lower impact on the semantic. In order to adequately evaluate the effectiveness of the proposed methods, we propose and utilize a dataset called Food-Recommendation DB (FRDB) focusing on food recommendation for women around pregnancy period or infants. Our summarization compression can reduce 65% of the retrieval token size with further 0.3% improvement on the accuracy; semantic compression provides a more flexible way to trade-off the token size with performance, for which we can reduce the token size by 20% with only 1.6% of accuracy drop.
Unsupervised Deep Cross-Language Entity Alignment
Sep 19, 2023Cross-lingual entity alignment is the task of finding the same semantic entities from different language knowledge graphs. In this paper, we propose a simple and novel unsupervised method for cross-language entity alignment. We utilize the deep learning multi-language encoder combined with a machine translator to encode knowledge graph text, which reduces the reliance on label data. Unlike traditional methods that only emphasize global or local alignment, our method simultaneously considers both alignment strategies. We first view the alignment task as a bipartite matching problem and then adopt the re-exchanging idea to accomplish alignment. Compared with the traditional bipartite matching algorithm that only gives one optimal solution, our algorithm generates ranked matching results which enabled many potentials downstream tasks. Additionally, our method can adapt two different types of optimization (minimal and maximal) in the bipartite matching process, which provides more flexibility. Our evaluation shows, we each scored 0.966, 0.990, and 0.996 Hits@1 rates on the DBP15K dataset in Chinese, Japanese, and French to English alignment tasks. We outperformed the state-of-the-art method in unsupervised and semi-supervised categories. Compared with the state-of-the-art supervised method, our method outperforms 2.6% and 0.4% in Ja-En and Fr-En alignment tasks while marginally lower by 0.2% in the Zh-En alignment task.