 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots that redesign themselves through kinematic self-destruction
Mar 12, 2026Every robot built to date was predesigned by an external process, prior to deployment. Here we show a robot that actively participates in its own design during its lifetime. Starting from a randomly assembled body, and using only proprioceptive feedback, the robot dynamically ``sculpts'' itself into a new design through kinematic self-destruction: identifying redundant links within its body that inhibit its locomotion, and then thrashing those links against the surface until they break at the joint and fall off the body. It does so using a single autoregressive sequence model, a universal controller that learns in simulation when and how to simplify a robot's body through self-destruction and then adaptively controls the reduced morphology. The optimized policy successfully transfers to reality and generalizes to previously unseen kinematic trees, generating forward locomotion that is more effective than otherwise equivalent policies that randomly remove links or cannot remove any. This suggests that self-designing robots may be more successful than predesigned robots in some cases, and that kinematic self-destruction, though reductive and irreversible, could provide a general adaptive strategy for a wide range of robots.
Simulated Cortical Magnification Supports Self-Supervised Object Learning
Sep 19, 2025Recent self-supervised learning models simulate the development of semantic object representations by training on visual experience similar to that of toddlers. However, these models ignore the foveated nature of human vision with high/low resolution in the center/periphery of the visual field. Here, we investigate the role of this varying resolution in the development of object representations. We leverage two datasets of egocentric videos that capture the visual experience of humans during interactions with objects. We apply models of human foveation and cortical magnification to modify these inputs, such that the visual content becomes less distinct towards the periphery. The resulting sequences are used to train two bio-inspired self-supervised learning models that implement a time-based learning objective. Our results show that modeling aspects of foveated vision improves the quality of the learned object representations in this setting. Our analysis suggests that this improvement comes from making objects appear bigger and inducing a better trade-off between central and peripheral visual information. Overall, this work takes a step towards making models of humans' learning of visual representations more realistic and performant.
From Questions to Clinical Recommendations: Large Language Models Driving Evidence-Based Clinical Decision Making
May 15, 2025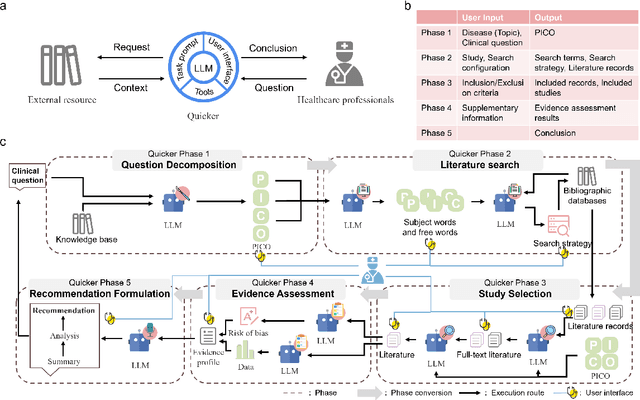
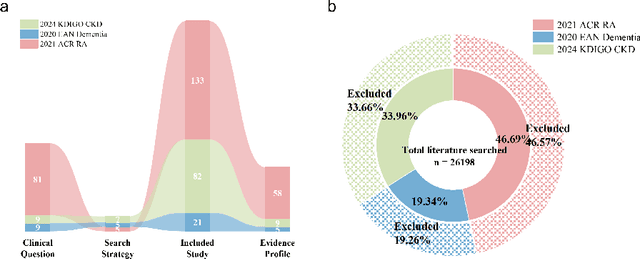
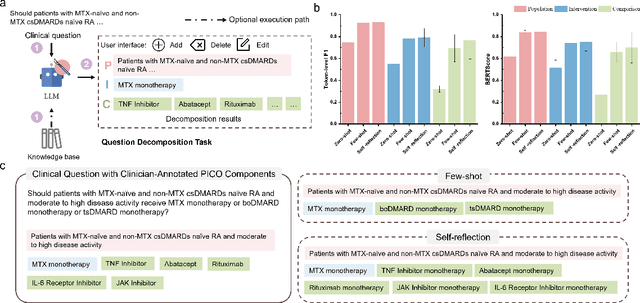
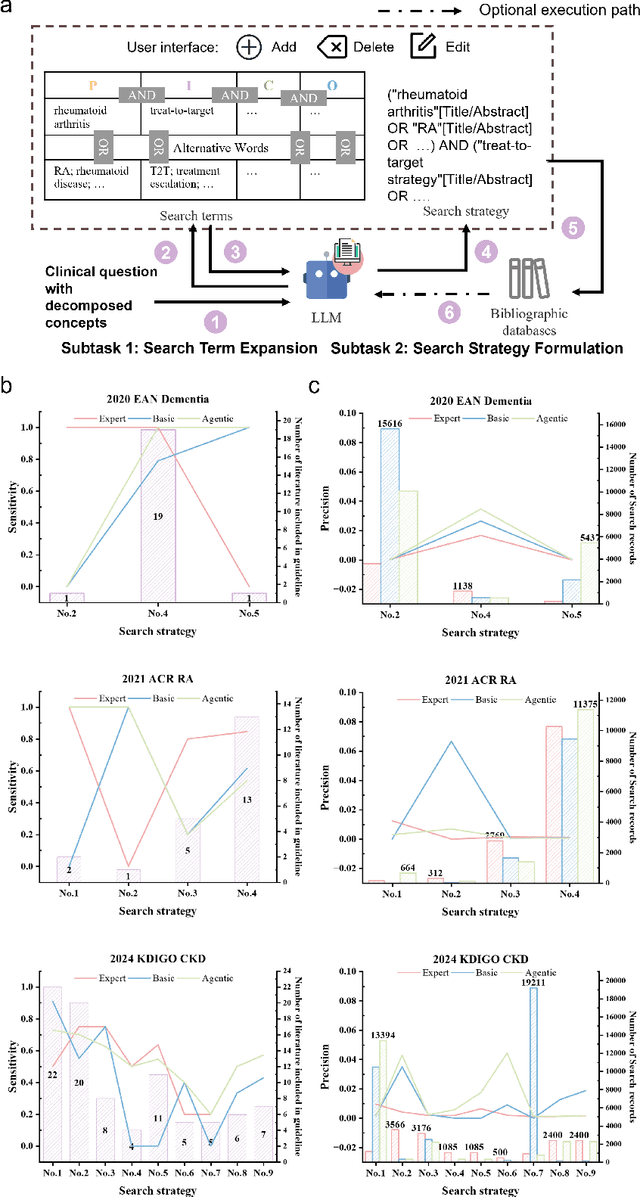
Clinical evidence, derived from rigorous research and data analysis, provides healthcare professionals with reliable scientific foundations for informed decision-making. Integrating clinical evidence into real-time practice is challenging due to the enormous workload, complex professional processes, and time constraints. This highlights the need for tools that automate evidence synthesis to support more efficient and accurate decision making in clinical settings. This study introduces Quicker, an evidence-based clinical decision support system powered by large language models (LLMs), designed to automate evidence synthesis and generate clinical recommendations modeled after standard clinical guideline development processes. Quicker implements a fully automated chain that covers all phases, from questions to clinical recommendations, and further enables customized decision-making through integrated tools and interactive user interfaces. To evaluate Quicker's capabilities, we developed the Q2CRBench-3 benchmark dataset, based on clinical guideline development records for three different diseases. Experimental results highlighted Quicker's strong performance, with fine-grained question decomposition tailored to user preferences, retrieval sensitivities comparable to human experts, and literature screening performance approaching comprehensive inclusion of relevant studies. In addition, Quicker-assisted evidence assessment effectively supported human reviewers, while Quicker's recommendations were more comprehensive and logically coherent than those of clinicians. In system-level testing, collaboration between a single reviewer and Quicker reduced the time required for recommendation development to 20-40 minutes. In general, our findings affirm the potential of Quicker to help physicians make quicker and more reliable evidence-based clinical decisions.
Reconfigurable legged metamachines that run on autonomous modular legs
May 01, 2025
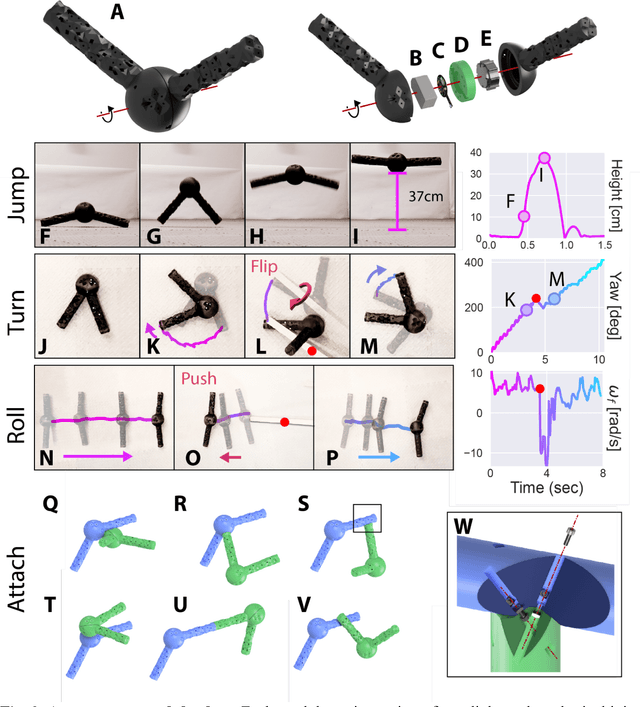
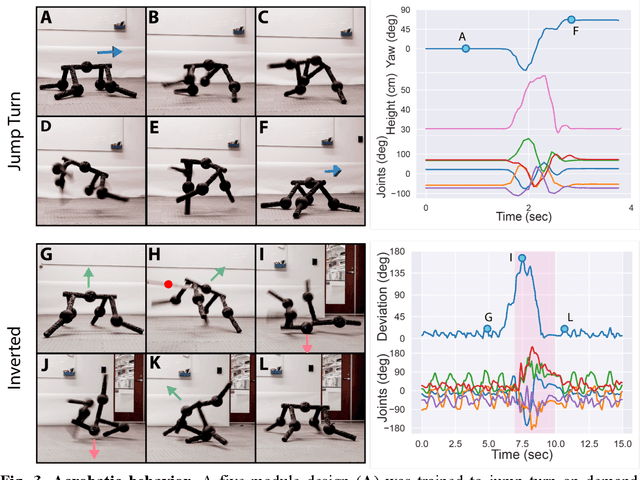
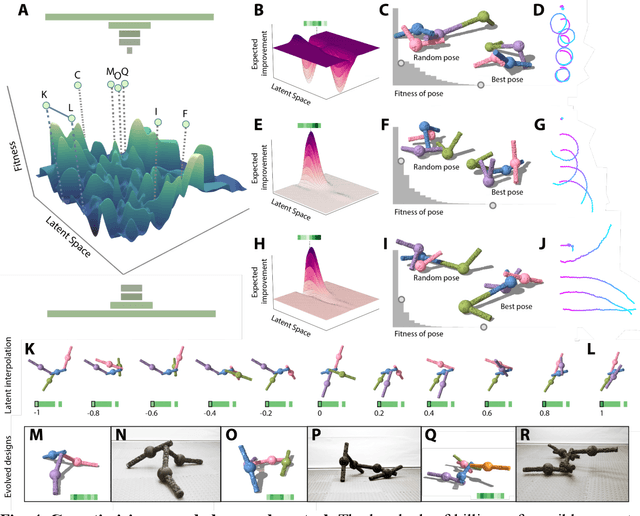
Legged machines are becoming increasingly agile and adaptive but they have so far lacked the basic reconfigurability of legged animals, which have been rearranged and reshaped to fill millions of niches. Unlike their biological counterparts, legged machines have largely converged over the past decade to canonical quadrupedal and bipedal architectures that cannot be easily reconfigured to meet new tasks or recover from injury. Here we introduce autonomous modular legs: agile yet minimal, single-degree-of-freedom jointed links that can learn complex dynamic behaviors and may be freely attached to form legged metamachines at the meter scale. This enables rapid repair, redesign, and recombination of highly-dynamic modular agents that move quickly and acrobatically (non-quasistatically) through unstructured environments. Because each module is itself a complete agent, legged metamachines are able to sustain deep structural damage that would completely disable other legged robots. We also show how to encode the vast space of possible body configurations into a compact latent design genome that can be efficiently explored, revealing a wide diversity of novel legged forms.
Active Gaze Behavior Boosts Self-Supervised Object Learning
Nov 04, 2024Due to significant variations in the projection of the same object from different viewpoints, machine learning algorithms struggle to recognize the same object across various perspectives. In contrast, toddlers quickly learn to recognize objects from different viewpoints with almost no supervision. Recent works argue that toddlers develop this ability by mapping close-in-time visual inputs to similar representations while interacting with objects. High acuity vision is only available in the central visual field, which may explain why toddlers (much like adults) constantly move their gaze around during such interactions. It is unclear whether/how much toddlers curate their visual experience through these eye movements to support learning object representations. In this work, we explore whether a bio inspired visual learning model can harness toddlers' gaze behavior during a play session to develop view-invariant object recognition. Exploiting head-mounted eye tracking during dyadic play, we simulate toddlers' central visual field experience by cropping image regions centered on the gaze location. This visual stream feeds a time-based self-supervised learning algorithm. Our experiments demonstrate that toddlers' gaze strategy supports the learning of invariant object representations. Our analysis also reveals that the limited size of the central visual field where acuity is high is crucial for this. We further find that toddlers' visual experience elicits more robust representations compared to adults' mostly because toddlers look at objects they hold themselves for longer bouts. Overall, our work reveals how toddlers' gaze behavior supports self-supervised learning of view-invariant object recognition.
State Estimation Transformers for Agile Legged Locomotion
Oct 17, 2024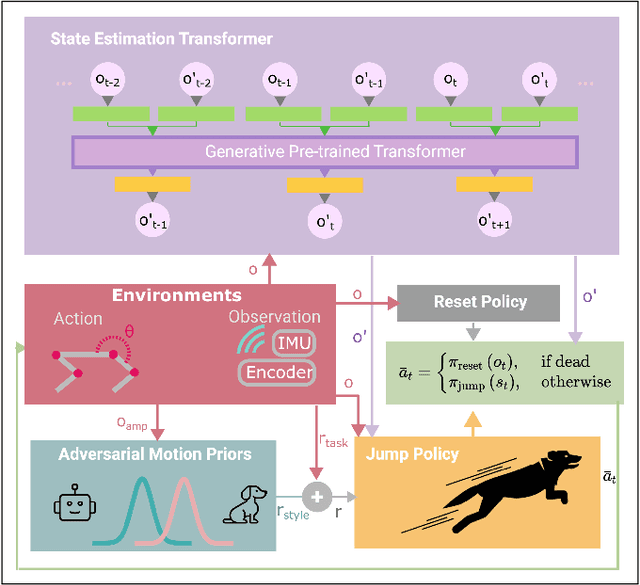
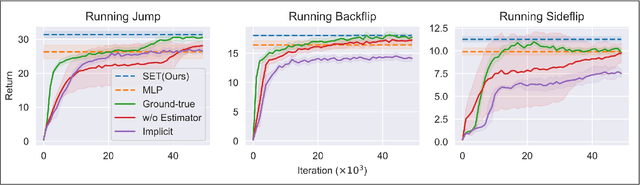

We propose a state estimation method that can accurately predict the robot's privileged states to push the limits of quadruped robots in executing advanced skills such as jumping in the wild. In particular, we present the State Estimation Transformers (SET), an architecture that casts the state estimation problem as conditional sequence modeling. SET outputs the robot states that are hard to obtain directly in the real world, such as the body height and velocities, by leveraging a causally masked Transformer. By conditioning an autoregressive model on the robot's past states, our SET model can predict these privileged observations accurately even in highly dynamic locomotions. We evaluate our methods on three tasks -- running jumping, running backflipping, and running sideslipping -- on a low-cost quadruped robot, Cyberdog2. Results show that SET can outperform other methods in estimation accuracy and transferability in the simulation as well as success rates of jumping and triggering a recovery controller in the real world, suggesting the superiority of such a Transformer-based explicit state estimator in highly dynamic locomotion tasks.
An Attention-Based Algorithm for Gravity Adaptation Zone Calibration
Oct 06, 2024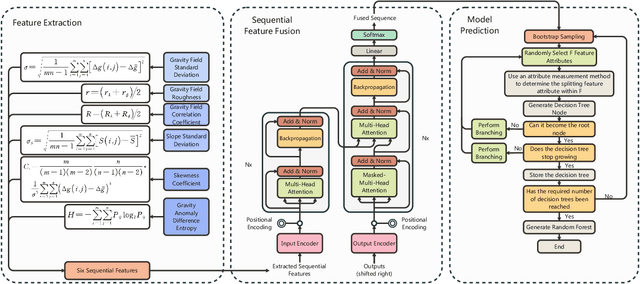
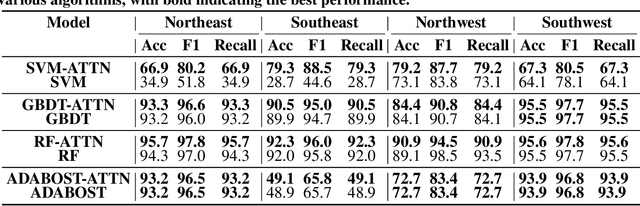
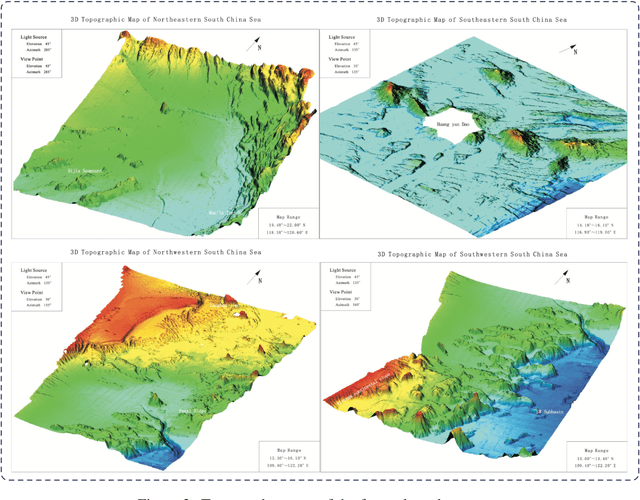
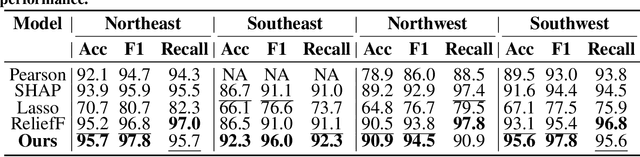
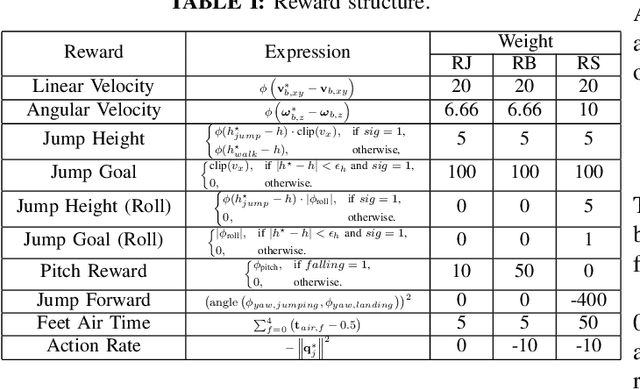
Accurate calibration of gravity adaptation zones is of great significance in fields such as underwater navigation, geophysical exploration, and marine engineering. With the increasing application of gravity field data in these areas, traditional calibration methods based on single features are becoming inadequate for capturing the complex characteristics of gravity fields and addressing the intricate interrelationships among multidimensional data. This paper proposes an attention-enhanced algorithm for gravity adaptation zone calibration. By introducing an attention mechanism, the algorithm adaptively fuses multidimensional gravity field features and dynamically assigns feature weights, effectively solving the problems of multicollinearity and redundancy inherent in traditional feature selection methods, significantly improving calibration accuracy and robustness.In addition, a large-scale gravity field dataset with over 10,000 sampling points was constructed, and Kriging interpolation was used to enhance the spatial resolution of the data, providing a reliable data foundation for model training and evaluation. We conducted both qualitative and quantitative experiments on several classical machine learning models (such as SVM, GBDT, and RF), and the results demonstrate that the proposed algorithm significantly improves performance across these models, outperforming other traditional feature selection methods. The method proposed in this paper provides a new solution for gravity adaptation zone calibration, showing strong generalization ability and potential for application in complex environments. The code is available at \href{this link} {https://github.com/hulnifox/RF-ATTN}.
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Apr 12, 2024


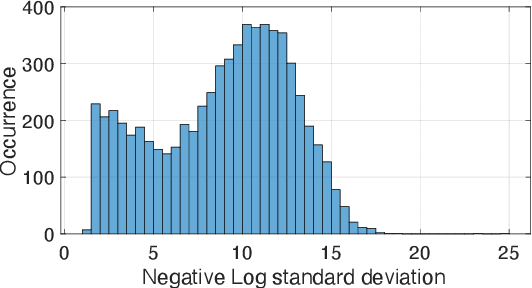
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
SoftMAC: Differentiable Soft Body Simulation with Forecast-based Contact Model and Two-way Coupling with Articulated Rigid Bodies and Clothes
Dec 06, 2023

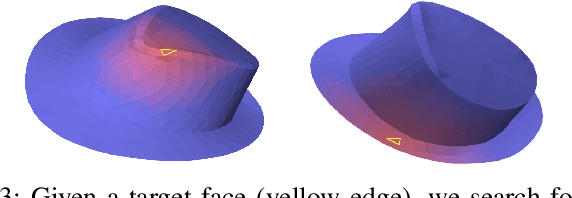
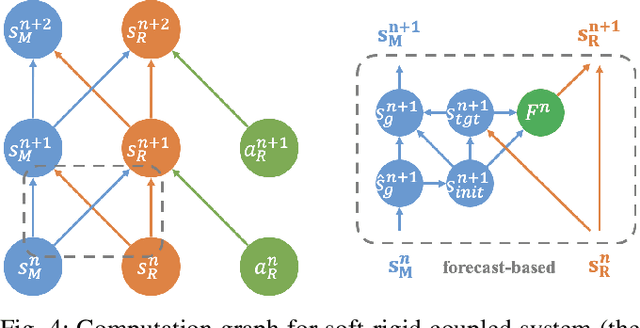
Differentiable physics simulation provides an avenue for tackling previously intractable challenges through gradient-based optimization, thereby greatly improving the efficiency of solving robotics-related problems. To apply differentiable simulation in diverse robotic manipulation scenarios, a key challenge is to integrate various materials in a unified framework. We present SoftMAC, a differentiable simulation framework coupling soft bodies with articulated rigid bodies and clothes. SoftMAC simulates soft bodies with the continuum-mechanics-based Material Point Method (MPM). We provide a forecast-based contact model for MPM, which greatly reduces artifacts like penetration and unnatural rebound. To couple MPM particles with deformable and non-volumetric clothes meshes, we also propose a penetration tracing algorithm that reconstructs the signed distance field in local area. Based on simulators for each modality and the contact model, we develop a differentiable coupling mechanism to simulate the interactions between soft bodies and the other two types of materials. Comprehensive experiments are conducted to validate the effectiveness and accuracy of the proposed differentiable pipeline in downstream robotic manipulation applications. Supplementary materials and videos are available on our project website at https://sites.google.com/view/softmac.
TSViT: A Time Series Vision Transformer for Fault Diagnosis
Nov 12, 2023Traditional fault diagnosis methods using Convolutional Neural Networks (CNNs) face limitations in capturing temporal features (i.e., the variation of vibration signals over time). To address this issue, this paper introduces a novel model, the Time Series Vision Transformer (TSViT), specifically designed for fault diagnosis. On one hand, TSViT model integrates a convolutional layer to segment vibration signals and capture local features. On the other hand, it employs a transformer encoder to learn long-term temporal information. The experimental results with other methods on two distinct datasets validate the effectiveness and generalizability of TSViT with a comparative analysis of its hyperparameters' impact on model performance, computational complexity, and overall parameter quantity. TSViT reaches average accuracies of 100% and 99.99% on two test sets, correspondingly.