 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Slowness in Central Vision Drives Semantic Object Learning
Feb 04, 2026Humans acquire semantic object representations from egocentric visual streams with minimal supervision. Importantly, the visual system processes with high resolution only the center of its field of view and learns similar representations for visual inputs occurring close in time. This emphasizes slowly changing information around gaze locations. This study investigates the role of central vision and slowness learning in the formation of semantic object representations from human-like visual experience. We simulate five months of human-like visual experience using the Ego4D dataset and generate gaze coordinates with a state-of-the-art gaze prediction model. Using these predictions, we extract crops that mimic central vision and train a time-contrastive Self-Supervised Learning model on them. Our results show that combining temporal slowness and central vision improves the encoding of different semantic facets of object representations. Specifically, focusing on central vision strengthens the extraction of foreground object features, while considering temporal slowness, especially during fixational eye movements, allows the model to encode broader semantic information about objects. These findings provide new insights into the mechanisms by which humans may develop semantic object representations from natural visual experience.
Re-assessing the evidence for mental rotation abilities in children using computational models
Dec 19, 2025There is strong and diverse evidence for mental rotation (MR) abilities in adults. However, current evidence for MR in children rests on just a few behavioral paradigms adapted from the adult literature. Here, we leverage recent computational models of the development of children's object recognition abilities to re-assess the evidence for MR in children. The computational models simulate infants' acquisition of object representations during embodied interactions with objects. We consider two different object recognition strategies, different from MRs, and assess their ability to replicate results from three classical MR tasks assigned to children between the ages of 6 months and 5 years. Our results show that MR may play no role in producing the results obtained from children younger than 5 years. In fact, we find that a simple recognition strategy that reflects a pixel-wise comparison of stimuli is sufficient to model children's behavior in the most used MR task. Thus, our study reopens the debate on how and when children develop genuine MR abilities.
Simulated Cortical Magnification Supports Self-Supervised Object Learning
Sep 19, 2025Recent self-supervised learning models simulate the development of semantic object representations by training on visual experience similar to that of toddlers. However, these models ignore the foveated nature of human vision with high/low resolution in the center/periphery of the visual field. Here, we investigate the role of this varying resolution in the development of object representations. We leverage two datasets of egocentric videos that capture the visual experience of humans during interactions with objects. We apply models of human foveation and cortical magnification to modify these inputs, such that the visual content becomes less distinct towards the periphery. The resulting sequences are used to train two bio-inspired self-supervised learning models that implement a time-based learning objective. Our results show that modeling aspects of foveated vision improves the quality of the learned object representations in this setting. Our analysis suggests that this improvement comes from making objects appear bigger and inducing a better trade-off between central and peripheral visual information. Overall, this work takes a step towards making models of humans' learning of visual representations more realistic and performant.
Hierarchical Residuals Exploit Brain-Inspired Compositionality
Feb 21, 2025We present Hierarchical Residual Networks (HiResNets), deep convolutional neural networks with long-range residual connections between layers at different hierarchical levels. HiResNets draw inspiration on the organization of the mammalian brain by replicating the direct connections from subcortical areas to the entire cortical hierarchy. We show that the inclusion of hierarchical residuals in several architectures, including ResNets, results in a boost in accuracy and faster learning. A detailed analysis of our models reveals that they perform hierarchical compositionality by learning feature maps relative to the compressed representations provided by the skip connections.
Seeing the Whole in the Parts in Self-Supervised Representation Learning
Jan 06, 2025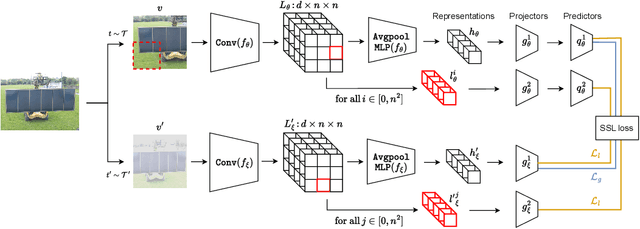
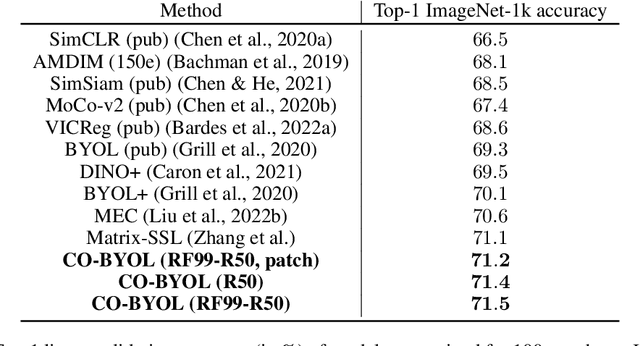
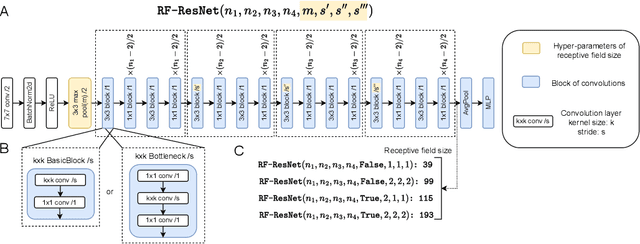

Recent successes in self-supervised learning (SSL) model spatial co-occurrences of visual features either by masking portions of an image or by aggressively cropping it. Here, we propose a new way to model spatial co-occurrences by aligning local representations (before pooling) with a global image representation. We present CO-SSL, a family of instance discrimination methods and show that it outperforms previous methods on several datasets, including ImageNet-1K where it achieves 71.5% of Top-1 accuracy with 100 pre-training epochs. CO-SSL is also more robust to noise corruption, internal corruption, small adversarial attacks, and large training crop sizes. Our analysis further indicates that CO-SSL learns highly redundant local representations, which offers an explanation for its robustness. Overall, our work suggests that aligning local and global representations may be a powerful principle of unsupervised category learning.
Human Gaze Boosts Object-Centered Representation Learning
Jan 06, 2025Recent self-supervised learning (SSL) models trained on human-like egocentric visual inputs substantially underperform on image recognition tasks compared to humans. These models train on raw, uniform visual inputs collected from head-mounted cameras. This is different from humans, as the anatomical structure of the retina and visual cortex relatively amplifies the central visual information, i.e. around humans' gaze location. This selective amplification in humans likely aids in forming object-centered visual representations. Here, we investigate whether focusing on central visual information boosts egocentric visual object learning. We simulate 5-months of egocentric visual experience using the large-scale Ego4D dataset and generate gaze locations with a human gaze prediction model. To account for the importance of central vision in humans, we crop the visual area around the gaze location. Finally, we train a time-based SSL model on these modified inputs. Our experiments demonstrate that focusing on central vision leads to better object-centered representations. Our analysis shows that the SSL model leverages the temporal dynamics of the gaze movements to build stronger visual representations. Overall, our work marks a significant step toward bio-inspired learning of visual representations.
Active Gaze Behavior Boosts Self-Supervised Object Learning
Nov 04, 2024Due to significant variations in the projection of the same object from different viewpoints, machine learning algorithms struggle to recognize the same object across various perspectives. In contrast, toddlers quickly learn to recognize objects from different viewpoints with almost no supervision. Recent works argue that toddlers develop this ability by mapping close-in-time visual inputs to similar representations while interacting with objects. High acuity vision is only available in the central visual field, which may explain why toddlers (much like adults) constantly move their gaze around during such interactions. It is unclear whether/how much toddlers curate their visual experience through these eye movements to support learning object representations. In this work, we explore whether a bio inspired visual learning model can harness toddlers' gaze behavior during a play session to develop view-invariant object recognition. Exploiting head-mounted eye tracking during dyadic play, we simulate toddlers' central visual field experience by cropping image regions centered on the gaze location. This visual stream feeds a time-based self-supervised learning algorithm. Our experiments demonstrate that toddlers' gaze strategy supports the learning of invariant object representations. Our analysis also reveals that the limited size of the central visual field where acuity is high is crucial for this. We further find that toddlers' visual experience elicits more robust representations compared to adults' mostly because toddlers look at objects they hold themselves for longer bouts. Overall, our work reveals how toddlers' gaze behavior supports self-supervised learning of view-invariant object recognition.
Self-supervised visual learning from interactions with objects
Jul 09, 2024



Self-supervised learning (SSL) has revolutionized visual representation learning, but has not achieved the robustness of human vision. A reason for this could be that SSL does not leverage all the data available to humans during learning. When learning about an object, humans often purposefully turn or move around objects and research suggests that these interactions can substantially enhance their learning. Here we explore whether such object-related actions can boost SSL. For this, we extract the actions performed to change from one ego-centric view of an object to another in four video datasets. We then introduce a new loss function to learn visual and action embeddings by aligning the performed action with the representations of two images extracted from the same clip. This permits the performed actions to structure the latent visual representation. Our experiments show that our method consistently outperforms previous methods on downstream category recognition. In our analysis, we find that the observed improvement is associated with a better viewpoint-wise alignment of different objects from the same category. Overall, our work demonstrates that embodied interactions with objects can improve SSL of object categories.
Self-Supervised Learning of Color Constancy
Apr 11, 2024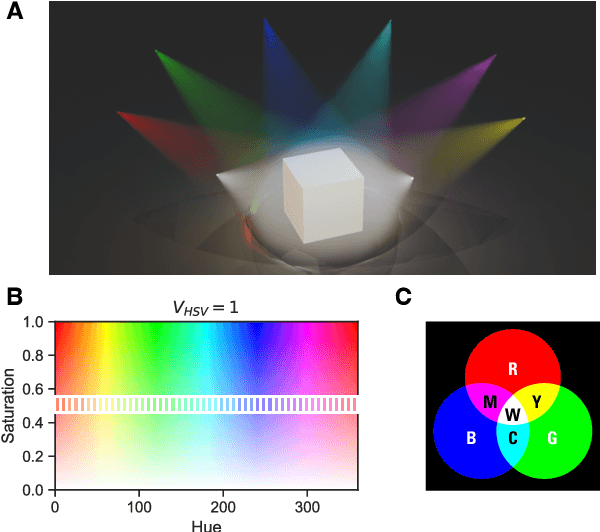

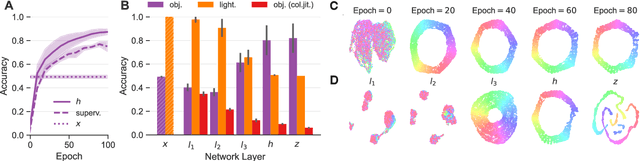
Color constancy (CC) describes the ability of the visual system to perceive an object as having a relatively constant color despite changes in lighting conditions. While CC and its limitations have been carefully characterized in humans, it is still unclear how the visual system acquires this ability during development. Here, we present a first study showing that CC develops in a neural network trained in a self-supervised manner through an invariance learning objective. During learning, objects are presented under changing illuminations, while the network aims to map subsequent views of the same object onto close-by latent representations. This gives rise to representations that are largely invariant to the illumination conditions, offering a plausible example of how CC could emerge during human cognitive development via a form of self-supervised learning.
MIMo: A Multi-Modal Infant Model for Studying Cognitive Development
Dec 07, 2023Human intelligence and human consciousness emerge gradually during the process of cognitive development. Understanding this development is an essential aspect of understanding the human mind and may facilitate the construction of artificial minds with similar properties. Importantly, human cognitive development relies on embodied interactions with the physical and social environment, which is perceived via complementary sensory modalities. These interactions allow the developing mind to probe the causal structure of the world. This is in stark contrast to common machine learning approaches, e.g., for large language models, which are merely passively ``digesting'' large amounts of training data, but are not in control of their sensory inputs. However, computational modeling of the kind of self-determined embodied interactions that lead to human intelligence and consciousness is a formidable challenge. Here we present MIMo, an open-source multi-modal infant model for studying early cognitive development through computer simulations. MIMo's body is modeled after an 18-month-old child with detailed five-fingered hands. MIMo perceives its surroundings via binocular vision, a vestibular system, proprioception, and touch perception through a full-body virtual skin, while two different actuation models allow control of his body. We describe the design and interfaces of MIMo and provide examples illustrating its use. All code is available at https://github.com/trieschlab/MIMo .