 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Contacts with Soft Gradients: Refining Differentiable Simulators for Learning and Control
Jun 17, 2025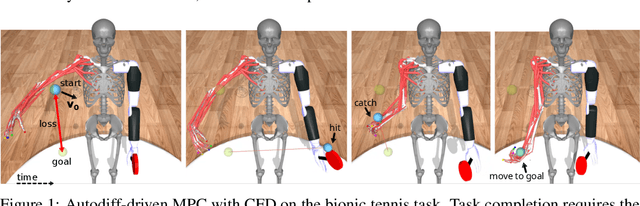
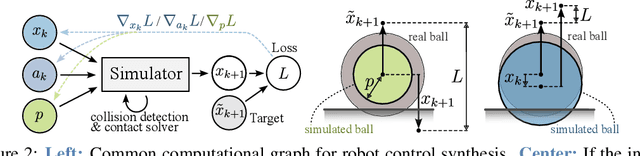
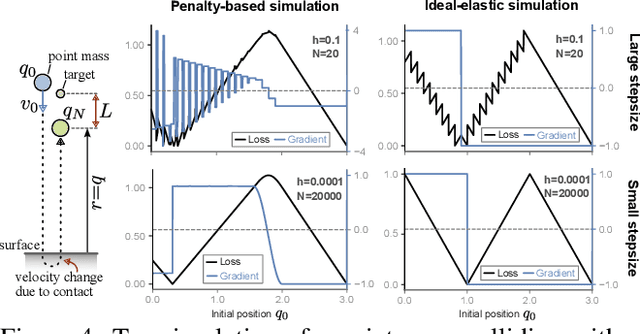
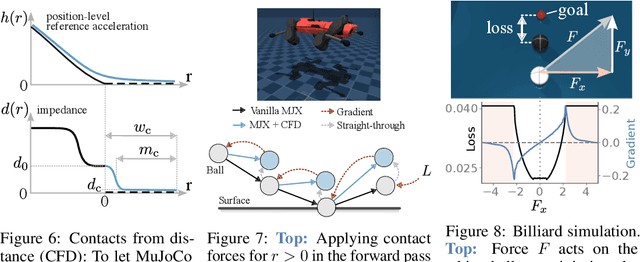
Contact forces pose a major challenge for gradient-based optimization of robot dynamics as they introduce jumps in the system's velocities. Penalty-based simulators, such as MuJoCo, simplify gradient computation by softening the contact forces. However, realistically simulating hard contacts requires very stiff contact settings, which leads to incorrect gradients when using automatic differentiation. On the other hand, using non-stiff settings strongly increases the sim-to-real gap. We analyze the contact computation of penalty-based simulators to identify the causes of gradient errors. Then, we propose DiffMJX, which combines adaptive integration with MuJoCo XLA, to notably improve gradient quality in the presence of hard contacts. Finally, we address a key limitation of contact gradients: they vanish when objects do not touch. To overcome this, we introduce Contacts From Distance (CFD), a mechanism that enables the simulator to generate informative contact gradients even before objects are in contact. To preserve physical realism, we apply CFD only in the backward pass using a straight-through trick, allowing us to compute useful gradients without modifying the forward simulation.
Generating Realistic Arm Movements in Reinforcement Learning: A Quantitative Comparison of Reward Terms and Task Requirements
Feb 21, 2024



The mimicking of human-like arm movement characteristics involves the consideration of three factors during control policy synthesis: (a) chosen task requirements, (b) inclusion of noise during movement execution and (c) chosen optimality principles. Previous studies showed that when considering these factors (a-c) individually, it is possible to synthesize arm movements that either kinematically match the experimental data or reproduce the stereotypical triphasic muscle activation pattern. However, to date no quantitative comparison has been made on how realistic the arm movement generated by each factor is; as well as whether a partial or total combination of all factors results in arm movements with human-like kinematic characteristics and a triphasic muscle pattern. To investigate this, we used reinforcement learning to learn a control policy for a musculoskeletal arm model, aiming to discern which combination of factors (a-c) results in realistic arm movements according to four frequently reported stereotypical characteristics. Our findings indicate that incorporating velocity and acceleration requirements into the reaching task, employing reward terms that encourage minimization of mechanical work, hand jerk, and control effort, along with the inclusion of noise during movement, leads to the emergence of realistic human arm movements in reinforcement learning. We expect that the gained insights will help in the future to better predict desired arm movements and corrective forces in wearable assistive devices.
Learning to Control Emulated Muscles in Real Robots: Towards Exploiting Bio-Inspired Actuator Morphology
Feb 08, 2024Recent studies have demonstrated the immense potential of exploiting muscle actuator morphology for natural and robust movement -- in simulation. A validation on real robotic hardware is yet missing. In this study, we emulate muscle actuator properties on hardware in real-time, taking advantage of modern and affordable electric motors. We demonstrate that our setup can emulate a simplified muscle model on a real robot while being controlled by a learned policy. We improve upon an existing muscle model by deriving a damping rule that ensures that the model is not only performant and stable but also tuneable for the real hardware. Our policies are trained by reinforcement learning entirely in simulation, where we show that previously reported benefits of muscles extend to the case of quadruped locomotion and hopping: the learned policies are more robust and exhibit more regular gaits. Finally, we confirm that the learned policies can be executed on real hardware and show that sim-to-real transfer with real-time emulated muscles on a quadruped robot is possible. These results show that artificial muscles can be highly beneficial actuators for future generations of robust legged robots.
Identifying Policy Gradient Subspaces
Jan 15, 2024Policy gradient methods hold great potential for solving complex continuous control tasks. Still, their training efficiency can be improved by exploiting structure within the optimization problem. Recent work indicates that supervised learning can be accelerated by leveraging the fact that gradients lie in a low-dimensional and slowly-changing subspace. In this paper, we conduct a thorough evaluation of this phenomenon for two popular deep policy gradient methods on various simulated benchmark tasks. Our results demonstrate the existence of such gradient subspaces despite the continuously changing data distribution inherent to reinforcement learning. These findings reveal promising directions for future work on more efficient reinforcement learning, e.g., through improving parameter-space exploration or enabling second-order optimization.
MIMo: A Multi-Modal Infant Model for Studying Cognitive Development
Dec 07, 2023Human intelligence and human consciousness emerge gradually during the process of cognitive development. Understanding this development is an essential aspect of understanding the human mind and may facilitate the construction of artificial minds with similar properties. Importantly, human cognitive development relies on embodied interactions with the physical and social environment, which is perceived via complementary sensory modalities. These interactions allow the developing mind to probe the causal structure of the world. This is in stark contrast to common machine learning approaches, e.g., for large language models, which are merely passively ``digesting'' large amounts of training data, but are not in control of their sensory inputs. However, computational modeling of the kind of self-determined embodied interactions that lead to human intelligence and consciousness is a formidable challenge. Here we present MIMo, an open-source multi-modal infant model for studying early cognitive development through computer simulations. MIMo's body is modeled after an 18-month-old child with detailed five-fingered hands. MIMo perceives its surroundings via binocular vision, a vestibular system, proprioception, and touch perception through a full-body virtual skin, while two different actuation models allow control of his body. We describe the design and interfaces of MIMo and provide examples illustrating its use. All code is available at https://github.com/trieschlab/MIMo .
Investigating the Impact of Action Representations in Policy Gradient Algorithms
Sep 13, 2023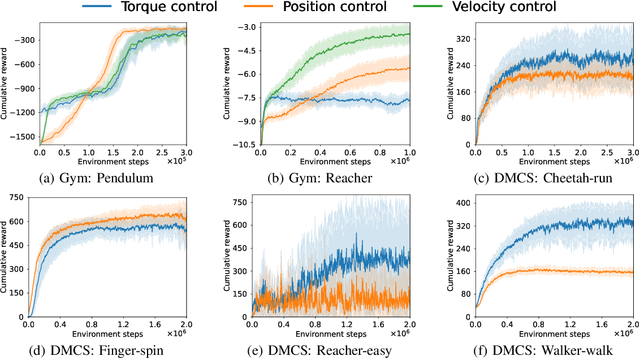
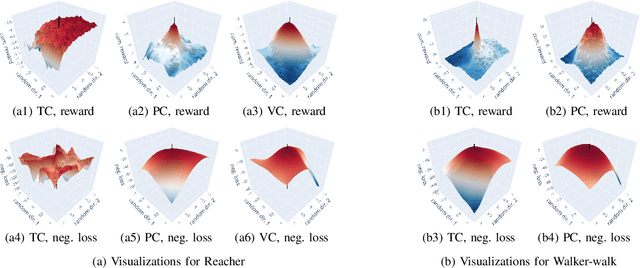
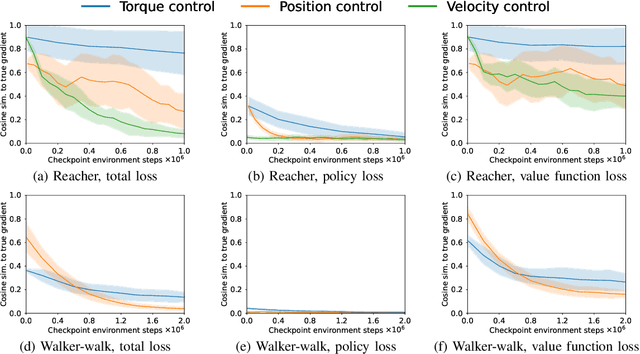
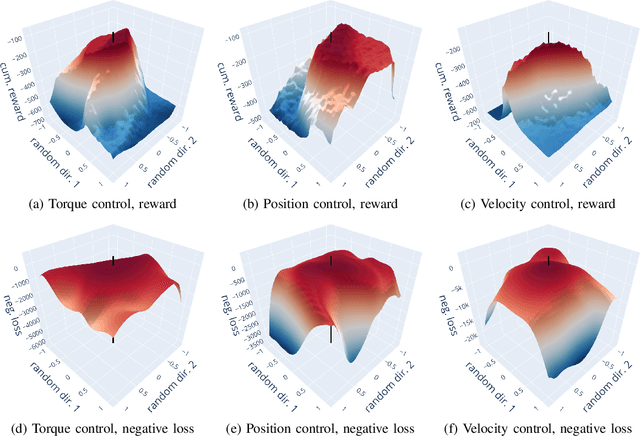
Reinforcement learning~(RL) is a versatile framework for learning to solve complex real-world tasks. However, influences on the learning performance of RL algorithms are often poorly understood in practice. We discuss different analysis techniques and assess their effectiveness for investigating the impact of action representations in RL. Our experiments demonstrate that the action representation can significantly influence the learning performance on popular RL benchmark tasks. The analysis results indicate that some of the performance differences can be attributed to changes in the complexity of the optimization landscape. Finally, we discuss open challenges of analysis techniques for RL algorithms.
Natural and Robust Walking using Reinforcement Learning without Demonstrations in High-Dimensional Musculoskeletal Models
Sep 07, 2023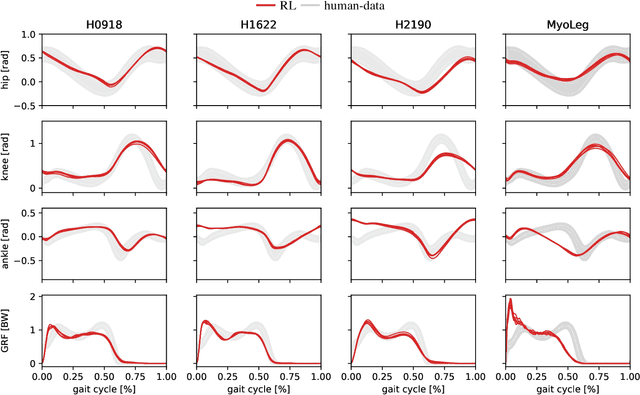
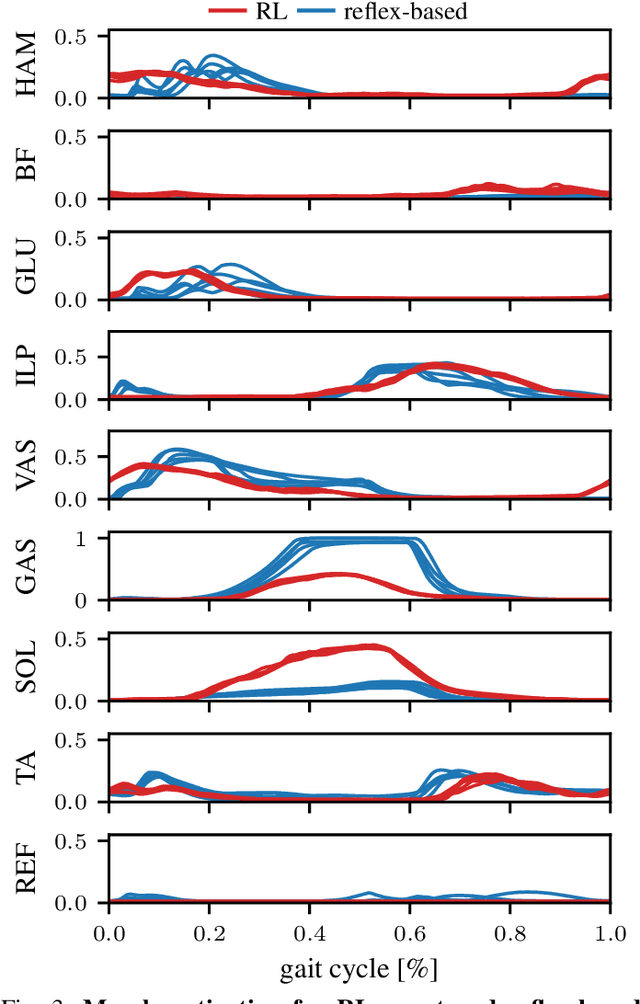
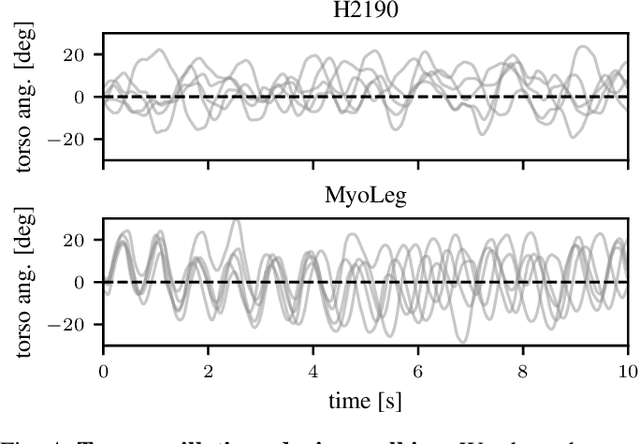

Humans excel at robust bipedal walking in complex natural environments. In each step, they adequately tune the interaction of biomechanical muscle dynamics and neuronal signals to be robust against uncertainties in ground conditions. However, it is still not fully understood how the nervous system resolves the musculoskeletal redundancy to solve the multi-objective control problem considering stability, robustness, and energy efficiency. In computer simulations, energy minimization has been shown to be a successful optimization target, reproducing natural walking with trajectory optimization or reflex-based control methods. However, these methods focus on particular motions at a time and the resulting controllers are limited when compensating for perturbations. In robotics, reinforcement learning~(RL) methods recently achieved highly stable (and efficient) locomotion on quadruped systems, but the generation of human-like walking with bipedal biomechanical models has required extensive use of expert data sets. This strong reliance on demonstrations often results in brittle policies and limits the application to new behaviors, especially considering the potential variety of movements for high-dimensional musculoskeletal models in 3D. Achieving natural locomotion with RL without sacrificing its incredible robustness might pave the way for a novel approach to studying human walking in complex natural environments. Videos: https://sites.google.com/view/naturalwalkingrl
Learning with Muscles: Benefits for Data-Efficiency and Robustness in Anthropomorphic Tasks
Jul 08, 2022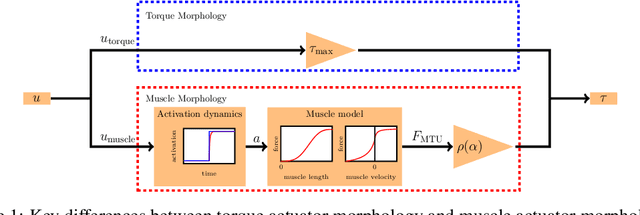
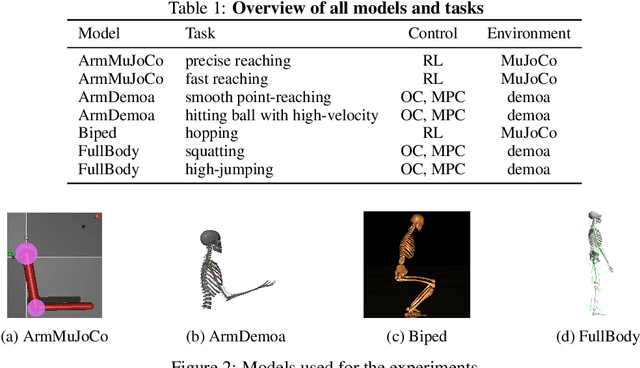

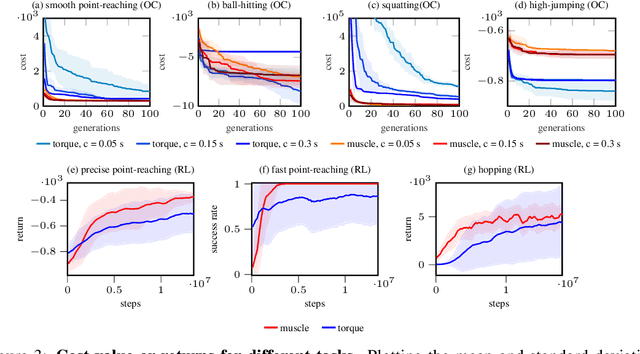
Humans are able to outperform robots in terms of robustness, versatility, and learning of new tasks in a wide variety of movements. We hypothesize that highly nonlinear muscle dynamics play a large role in providing inherent stability, which is favorable to learning. While recent advances have been made in applying modern learning techniques to muscle-actuated systems both in simulation as well as in robotics, so far, no detailed analysis has been performed to show the benefits of muscles in this setting. Our study closes this gap by investigating core robotics challenges and comparing the performance of different actuator morphologies in terms of data-efficiency, hyperparameter sensitivity, and robustness.
DEP-RL: Embodied Exploration for Reinforcement Learning in Overactuated and Musculoskeletal Systems
May 30, 2022



Muscle-actuated organisms are capable of learning an unparalleled diversity of dexterous movements despite their vast amount of muscles. Reinforcement learning (RL) on large musculoskeletal models, however, has not been able to show similar performance. We conjecture that ineffective exploration in large overactuated action spaces is a key problem. This is supported by the finding that common exploration noise strategies are inadequate in synthetic examples of overactuated systems. We identify differential extrinsic plasticity (DEP), a method from the domain of self-organization, as being able to induce state-space covering exploration within seconds of interaction. By integrating DEP into RL, we achieve fast learning of reaching and locomotion in musculoskeletal systems, outperforming current approaches in all considered tasks in sample efficiency and robustness.