 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Algorithms for Smoothly Differentiable and Efficiently Vectorizable Contact Manifold Construction
Apr 19, 2026Generating intelligent robot behavior in contact-rich settings is a research problem where zeroth-order methods currently prevail. Developing methods that make use of first/second order information about the dynamics holds great promise in terms of increasing the solution speed and computational efficiency. The main bottleneck in this research direction is the difficulty in obtaining useful gradients and Hessians, due to pathologies in all three steps of a common simulation pipeline: i) collision detection, ii) contact dynamics, iii) time integration. This abstract proposes a method that can address the collision detection part of the puzzle in a manner that is smoothly differentiable and massively vectorizable. This is achieved via two contributions: i) a highly expressive class of analytical SDF primitives that can efficiently represent complex 3D surfaces, ii) a novel contact manifold generation routine that makes use of this geometry representation.
SoftJAX & SoftTorch: Empowering Automatic Differentiation Libraries with Informative Gradients
Mar 09, 2026Automatic differentiation (AD) frameworks such as JAX and PyTorch have enabled gradient-based optimization for a wide range of scientific fields. Yet, many "hard" primitives in these libraries such as thresholding, Boolean logic, discrete indexing, and sorting operations yield zero or undefined gradients that are not useful for optimization. While numerous "soft" relaxations have been proposed that provide informative gradients, the respective implementations are fragmented across projects, making them difficult to combine and compare. This work introduces SoftJAX and SoftTorch, open-source, feature-complete libraries for soft differentiable programming. These libraries provide a variety of soft functions as drop-in replacements for their hard JAX and PyTorch counterparts. This includes (i) elementwise operators such as clip or abs, (ii) utility methods for manipulating Booleans and indices via fuzzy logic, (iii) axiswise operators such as sort or rank -- based on optimal transport or permutahedron projections, and (iv) offer full support for straight-through gradient estimation. Overall, SoftJAX and SoftTorch make the toolbox of soft relaxations easily accessible to differentiable programming, as demonstrated through benchmarking and a practical case study. Code is available at github.com/a-paulus/softjax and github.com/a-paulus/softtorch.
Smoothly Differentiable and Efficiently Vectorizable Contact Manifold Generation
Feb 23, 2026Simulating rigid-body dynamics with contact in a fast, massively vectorizable, and smoothly differentiable manner is highly desirable in robotics. An important bottleneck faced by existing differentiable simulation frameworks is contact manifold generation: representing the volume of intersection between two colliding geometries via a discrete set of properly distributed contact points. A major factor contributing to this bottleneck is that the related routines of commonly used robotics simulators were not designed with vectorization and differentiability as a primary concern, and thus rely on logic and control flow that hinder these goals. We instead propose a framework designed from the ground up with these goals in mind, by trying to strike a middle ground between: i) convex primitive based approaches used by common robotics simulators (efficient but not differentiable), and ii) mollified vertex-face and edge-edge unsigned distance-based approaches used by barrier methods (differentiable but inefficient). Concretely, we propose: i) a representative set of smooth analytical signed distance primitives to implement vertex-face collisions, and ii) a novel differentiable edge-edge collision routine that can provide signed distances and signed contact normals. The proposed framework is evaluated via a set of didactic experiments and benchmarked against the collision detection routine of the well-established Mujoco XLA framework, where we observe a significant speedup. Supplementary videos can be found at https://github.com/bekeronur/contax, where a reference implementation in JAX will also be made available at the conclusion of the review process.
Safety Alignment of LMs via Non-cooperative Games
Dec 23, 2025Ensuring the safety of language models (LMs) while maintaining their usefulness remains a critical challenge in AI alignment. Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them. We introduce a different paradigm: framing safety alignment as a non-zero-sum game between an Attacker LM and a Defender LM trained jointly via online reinforcement learning. Each LM continuously adapts to the other's evolving strategies, driving iterative improvement. Our method uses a preference-based reward signal derived from pairwise comparisons instead of point-wise scores, providing more robust supervision and potentially reducing reward hacking. Our RL recipe, AdvGame, shifts the Pareto frontier of safety and utility, yielding a Defender LM that is simultaneously more helpful and more resilient to adversarial attacks. In addition, the resulting Attacker LM converges into a strong, general-purpose red-teaming agent that can be directly deployed to probe arbitrary target models.
Hard Contacts with Soft Gradients: Refining Differentiable Simulators for Learning and Control
Jun 17, 2025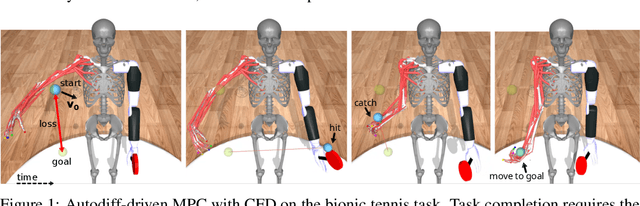
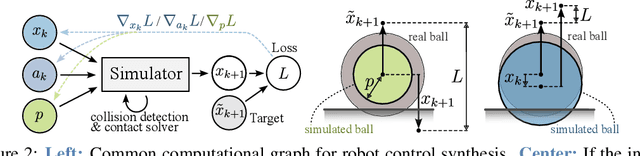
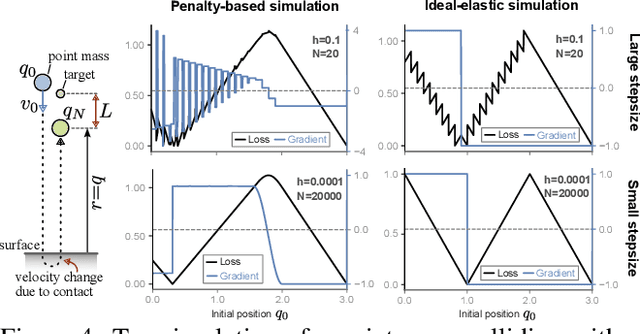
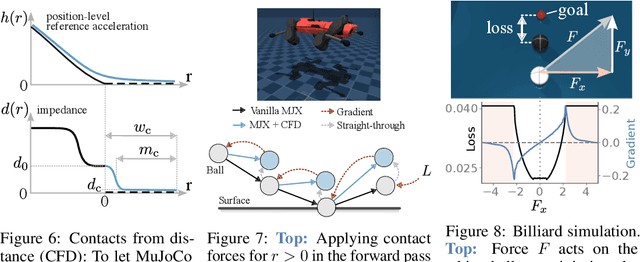
Contact forces pose a major challenge for gradient-based optimization of robot dynamics as they introduce jumps in the system's velocities. Penalty-based simulators, such as MuJoCo, simplify gradient computation by softening the contact forces. However, realistically simulating hard contacts requires very stiff contact settings, which leads to incorrect gradients when using automatic differentiation. On the other hand, using non-stiff settings strongly increases the sim-to-real gap. We analyze the contact computation of penalty-based simulators to identify the causes of gradient errors. Then, we propose DiffMJX, which combines adaptive integration with MuJoCo XLA, to notably improve gradient quality in the presence of hard contacts. Finally, we address a key limitation of contact gradients: they vanish when objects do not touch. To overcome this, we introduce Contacts From Distance (CFD), a mechanism that enables the simulator to generate informative contact gradients even before objects are in contact. To preserve physical realism, we apply CFD only in the backward pass using a straight-through trick, allowing us to compute useful gradients without modifying the forward simulation.
LPGD: A General Framework for Backpropagation through Embedded Optimization Layers
Jul 08, 2024Embedding parameterized optimization problems as layers into machine learning architectures serves as a powerful inductive bias. Training such architectures with stochastic gradient descent requires care, as degenerate derivatives of the embedded optimization problem often render the gradients uninformative. We propose Lagrangian Proximal Gradient Descent (LPGD) a flexible framework for training architectures with embedded optimization layers that seamlessly integrates into automatic differentiation libraries. LPGD efficiently computes meaningful replacements of the degenerate optimization layer derivatives by re-running the forward solver oracle on a perturbed input. LPGD captures various previously proposed methods as special cases, while fostering deep links to traditional optimization methods. We theoretically analyze our method and demonstrate on historical and synthetic data that LPGD converges faster than gradient descent even in a differentiable setup.
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Apr 21, 2024While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $\sim800\times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
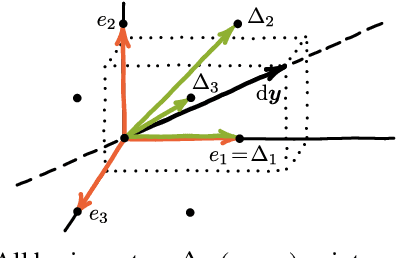
Gradient Backpropagation Through Combinatorial Algorithms: Identity with Projection Works
May 30, 2022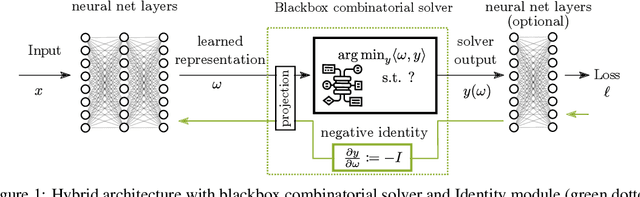
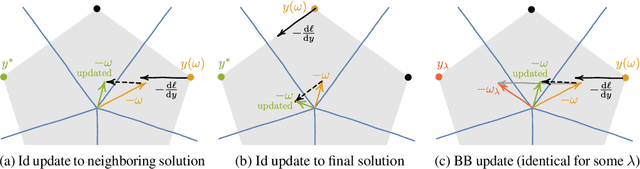
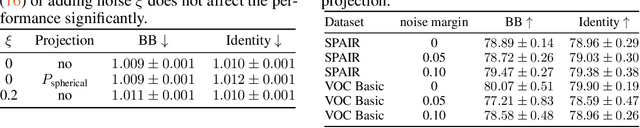
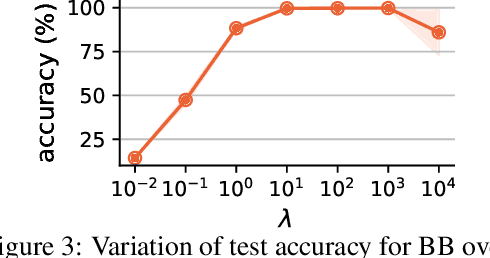
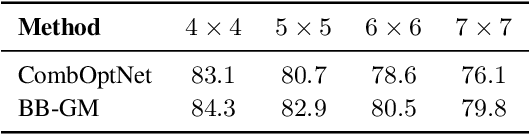
Embedding discrete solvers as differentiable layers has given modern deep learning architectures combinatorial expressivity and discrete reasoning capabilities. The derivative of these solvers is zero or undefined, therefore a meaningful replacement is crucial for effective gradient-based learning. Prior works rely on smoothing the solver with input perturbations, relaxing the solver to continuous problems, or interpolating the loss landscape with techniques that typically require additional solver calls, introduce extra hyper-parameters or compromise performance. We propose a principled approach to exploit the geometry of the discrete solution space to treat the solver as a negative identity on the backward pass and further provide a theoretical justification. Our experiments demonstrate that such a straightforward hyper-parameter-free approach is on-par with or outperforms previous more complex methods on numerous experiments such as Traveling Salesman Problem, Shortest Path, Deep Graph Matching, and backpropagating through discrete samplers. Furthermore, we substitute the previously proposed problem-specific and label-dependent margin by a generic regularization procedure that prevents cost collapse and increases robustness.
CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints
May 05, 2021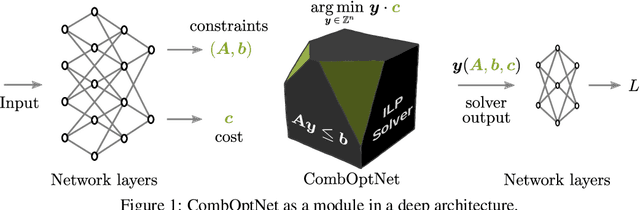

Bridging logical and algorithmic reasoning with modern machine learning techniques is a fundamental challenge with potentially transformative impact. On the algorithmic side, many NP-hard problems can be expressed as integer programs, in which the constraints play the role of their "combinatorial specification". In this work, we aim to integrate integer programming solvers into neural network architectures as layers capable of learning both the cost terms and the constraints. The resulting end-to-end trainable architectures jointly extract features from raw data and solve a suitable (learned) combinatorial problem with state-of-the-art integer programming solvers. We demonstrate the potential of such layers with an extensive performance analysis on synthetic data and with a demonstration on a competitive computer vision keypoint matching benchmark.
Deep Graph Matching via Blackbox Differentiation of Combinatorial Solvers
Mar 25, 2020

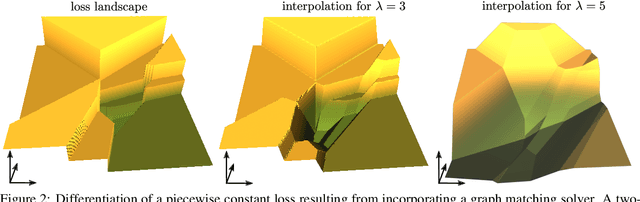
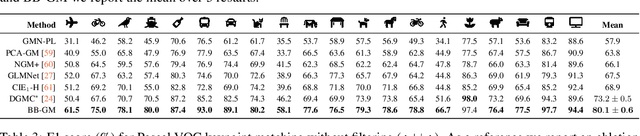
Building on recent progress at the intersection of combinatorial optimization and deep learning, we propose an end-to-end trainable architecture for deep graph matching that contains unmodified combinatorial solvers. Using the presence of heavily optimized combinatorial solvers together with some improvements in architecture design, we advance state-of-the-art on deep graph matching benchmarks for keypoint correspondence. In addition, we highlight the conceptual advantages of incorporating solvers into deep learning architectures, such as the possibility of post-processing with a strong multi-graph matching solver or the indifference to changes in the training setting. Finally, we propose two new challenging experimental setups.