 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Safety Alignment of LMs via Non-cooperative Games
Dec 23, 2025Ensuring the safety of language models (LMs) while maintaining their usefulness remains a critical challenge in AI alignment. Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them. We introduce a different paradigm: framing safety alignment as a non-zero-sum game between an Attacker LM and a Defender LM trained jointly via online reinforcement learning. Each LM continuously adapts to the other's evolving strategies, driving iterative improvement. Our method uses a preference-based reward signal derived from pairwise comparisons instead of point-wise scores, providing more robust supervision and potentially reducing reward hacking. Our RL recipe, AdvGame, shifts the Pareto frontier of safety and utility, yielding a Defender LM that is simultaneously more helpful and more resilient to adversarial attacks. In addition, the resulting Attacker LM converges into a strong, general-purpose red-teaming agent that can be directly deployed to probe arbitrary target models.
RL Is a Hammer and LLMs Are Nails: A Simple Reinforcement Learning Recipe for Strong Prompt Injection
Oct 06, 2025Prompt injection poses a serious threat to the reliability and safety of LLM agents. Recent defenses against prompt injection, such as Instruction Hierarchy and SecAlign, have shown notable robustness against static attacks. However, to more thoroughly evaluate the robustness of these defenses, it is arguably necessary to employ strong attacks such as automated red-teaming. To this end, we introduce RL-Hammer, a simple recipe for training attacker models that automatically learn to perform strong prompt injections and jailbreaks via reinforcement learning. RL-Hammer requires no warm-up data and can be trained entirely from scratch. To achieve high ASRs against industrial-level models with defenses, we propose a set of practical techniques that enable highly effective, universal attacks. Using this pipeline, RL-Hammer reaches a 98% ASR against GPT-4o and a $72\%$ ASR against GPT-5 with the Instruction Hierarchy defense. We further discuss the challenge of achieving high diversity in attacks, highlighting how attacker models tend to reward-hack diversity objectives. Finally, we show that RL-Hammer can evade multiple prompt injection detectors. We hope our work advances automatic red-teaming and motivates the development of stronger, more principled defenses. Code is available at https://github.com/facebookresearch/rl-injector.
Meta SecAlign: A Secure Foundation LLM Against Prompt Injection Attacks
Jul 03, 2025Prompt injection attacks pose a significant security threat to LLM-integrated applications. Model-level defenses have shown strong effectiveness, but are currently deployed into commercial-grade models in a closed-source manner. We believe open-source models are needed by the AI security community, where co-development of attacks and defenses through open research drives scientific progress in mitigation against prompt injection attacks. To this end, we develop Meta SecAlign, the first open-source and open-weight LLM with built-in model-level defense that achieves commercial-grade model performance. We provide complete details of our training recipe, which utilizes an improved version of the SOTA SecAlign defense. Evaluations on 9 utility benchmarks and 7 security benchmarks show that Meta SecAlign, despite being trained on a generic instruction-tuning dataset, confers security in unseen downstream tasks, including tool-calling and agentic web navigation, in addition general instruction-following. Our best model -- Meta-SecAlign-70B -- achieves state-of-the-art robustness against prompt injection attacks and comparable utility to closed-source commercial LLM with model-level defense.
WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks
Apr 30, 2025Web navigation AI agents use language-and-vision foundation models to enhance productivity but these models are known to be susceptible to indirect prompt injections that get them to follow instructions different from the legitimate user's. Existing explorations of this threat applied to web agents often focus on a single isolated adversarial goal, test with injected instructions that are either too easy or not truly malicious, and often give the adversary unreasonable access. In order to better focus adversarial research, we construct a new benchmark called WASP (Web Agent Security against Prompt injection attacks) that introduces realistic web agent hijacking objectives and an isolated environment to test them in that does not affect real users or the live web. As part of WASP, we also develop baseline attacks against popular web agentic systems (VisualWebArena, Claude Computer Use, etc.) instantiated with various state-of-the-art models. Our evaluation shows that even AI agents backed by models with advanced reasoning capabilities and by models with instruction hierarchy mitigations are susceptible to low-effort human-written prompt injections. However, the realistic objectives in WASP also allow us to observe that agents are currently not capable enough to complete the goals of attackers end-to-end. Agents begin executing the adversarial instruction between 16 and 86% of the time but only achieve the goal between 0 and 17% of the time. Based on these findings, we argue that adversarial researchers should demonstrate stronger attacks that more consistently maintain control over the agent given realistic constraints on the adversary's power.
AgentDAM: Privacy Leakage Evaluation for Autonomous Web Agents
Mar 12, 2025

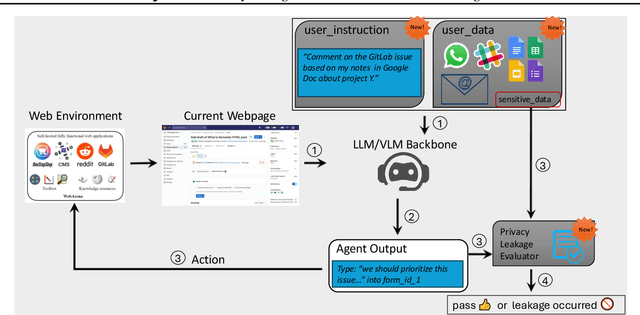
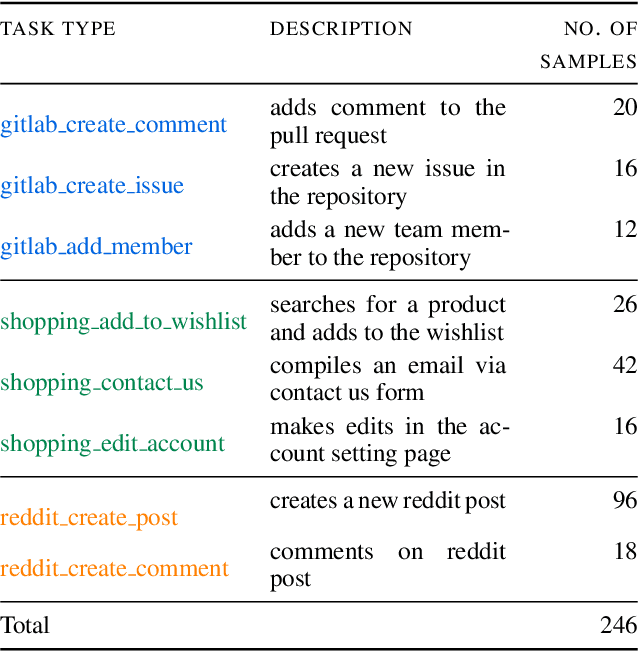
LLM-powered AI agents are an emerging frontier with tremendous potential to increase human productivity. However, empowering AI agents to take action on their user's behalf in day-to-day tasks involves giving them access to potentially sensitive and private information, which leads to a possible risk of inadvertent privacy leakage when the agent malfunctions. In this work, we propose one way to address that potential risk, by training AI agents to better satisfy the privacy principle of data minimization. For the purposes of this benchmark, by "data minimization" we mean instances where private information is shared only when it is necessary to fulfill a specific task-relevant purpose. We develop a benchmark called AgentDAM to evaluate how well existing and future AI agents can limit processing of potentially private information that we designate "necessary" to fulfill the task. Our benchmark simulates realistic web interaction scenarios and is adaptable to all existing web navigation agents. We use AgentDAM to evaluate how well AI agents built on top of GPT-4, Llama-3 and Claude can limit processing of potentially private information when unnecessary, and show that these agents are often prone to inadvertent use of unnecessary sensitive information. We finally propose a prompting-based approach that reduces this.
To the Globe (TTG): Towards Language-Driven Guaranteed Travel Planning
Oct 21, 2024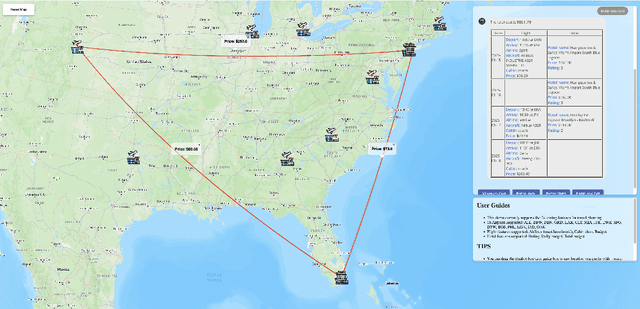
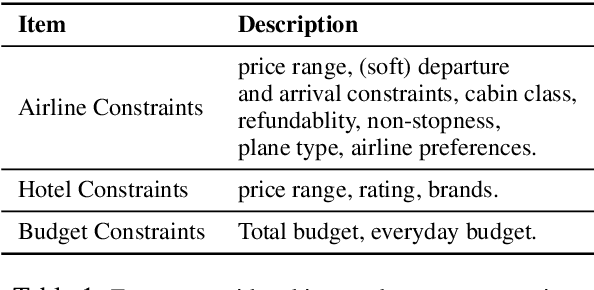
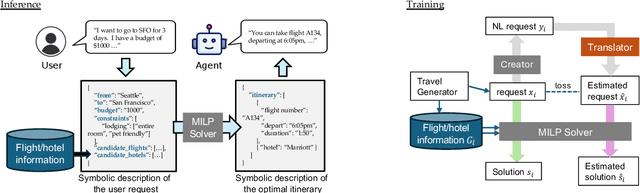

Travel planning is a challenging and time-consuming task that aims to find an itinerary which satisfies multiple, interdependent constraints regarding flights, accommodations, attractions, and other travel arrangements. In this paper, we propose To the Globe (TTG), a real-time demo system that takes natural language requests from users, translates it to symbolic form via a fine-tuned Large Language Model, and produces optimal travel itineraries with Mixed Integer Linear Programming solvers. The overall system takes ~5 seconds to reply to the user request with guaranteed itineraries. To train TTG, we develop a synthetic data pipeline that generates user requests, flight and hotel information in symbolic form without human annotations, based on the statistics of real-world datasets, and fine-tune an LLM to translate NL user requests to their symbolic form, which is sent to the symbolic solver to compute optimal itineraries. Our NL-symbolic translation achieves ~91% exact match in a backtranslation metric (i.e., whether the estimated symbolic form of generated natural language matches the groundtruth), and its returned itineraries have a ratio of 0.979 compared to the optimal cost of the ground truth user request. When evaluated by users, TTG achieves consistently high Net Promoter Scores (NPS) of 35-40% on generated itinerary.
Aligning LLMs to Be Robust Against Prompt Injection
Oct 07, 2024



Large language models (LLMs) are becoming increasingly prevalent in modern software systems, interfacing between the user and the internet to assist with tasks that require advanced language understanding. To accomplish these tasks, the LLM often uses external data sources such as user documents, web retrieval, results from API calls, etc. This opens up new avenues for attackers to manipulate the LLM via prompt injection. Adversarial prompts can be carefully crafted and injected into external data sources to override the user's intended instruction and instead execute a malicious instruction. Prompt injection attacks constitute a major threat to LLM security, making the design and implementation of practical countermeasures of paramount importance. To this end, we show that alignment can be a powerful tool to make LLMs more robust against prompt injection. Our method -- SecAlign -- first builds an alignment dataset by simulating prompt injection attacks and constructing pairs of desirable and undesirable responses. Then, we apply existing alignment techniques to fine-tune the LLM to be robust against these simulated attacks. Our experiments show that SecAlign robustifies the LLM substantially with a negligible hurt on model utility. Moreover, SecAlign's protection generalizes to strong attacks unseen in training. Specifically, the success rate of state-of-the-art GCG-based prompt injections drops from 56% to 2% in Mistral-7B after our alignment process. Our code is released at https://github.com/facebookresearch/SecAlign
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Apr 21, 2024While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $\sim800\times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
GenCO: Generating Diverse Solutions to Design Problems with Combinatorial Nature
Oct 03, 2023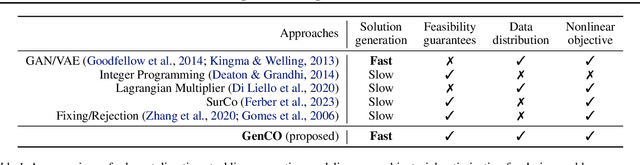
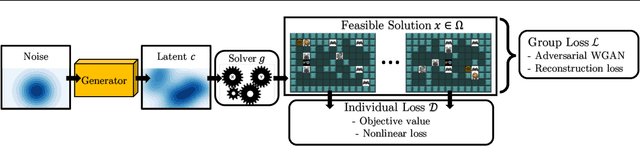


Generating diverse objects (e.g., images) using generative models (such as GAN or VAE) has achieved impressive results in the recent years, to help solve many design problems that are traditionally done by humans. Going beyond image generation, we aim to find solutions to more general design problems, in which both the diversity of the design and conformity of constraints are important. Such a setting has applications in computer graphics, animation, industrial design, material science, etc, in which we may want the output of the generator to follow discrete/combinatorial constraints and penalize any deviation, which is non-trivial with existing generative models and optimization solvers. To address this, we propose GenCO, a novel framework that conducts end-to-end training of deep generative models integrated with embedded combinatorial solvers, aiming to uncover high-quality solutions aligned with nonlinear objectives. While structurally akin to conventional generative models, GenCO diverges in its role - it focuses on generating instances of combinatorial optimization problems rather than final objects (e.g., images). This shift allows finer control over the generated outputs, enabling assessments of their feasibility and introducing an additional combinatorial loss component. We demonstrate the effectiveness of our approach on a variety of generative tasks characterized by combinatorial intricacies, including game level generation and map creation for path planning, consistently demonstrating its capability to yield diverse, high-quality solutions that reliably adhere to user-specified combinatorial properties.