 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in 13 Parameters
Feb 04, 2026Recent research has shown that language models can learn to \textit{reason}, often via reinforcement learning. Some work even trains low-rank parameterizations for reasoning, but conventional LoRA cannot scale below the model dimension. We question whether even rank=1 LoRA is necessary for learning to reason and propose TinyLoRA, a method for scaling low-rank adapters to sizes as small as one parameter. Within our new parameterization, we are able to train the 8B parameter size of Qwen2.5 to 91\% accuracy on GSM8K with only 13 trained parameters in bf16 (26 total bytes). We find this trend holds in general: we are able to recover 90\% of performance improvements while training $1000x$ fewer parameters across a suite of more difficult learning-to-reason benchmarks such as AIME, AMC, and MATH500. Notably, we are only able to achieve such strong performance with RL: models trained using SFT require $100-1000x$ larger updates to reach the same performance.
Privacy Blur: Quantifying Privacy and Utility for Image Data Release
Dec 18, 2025
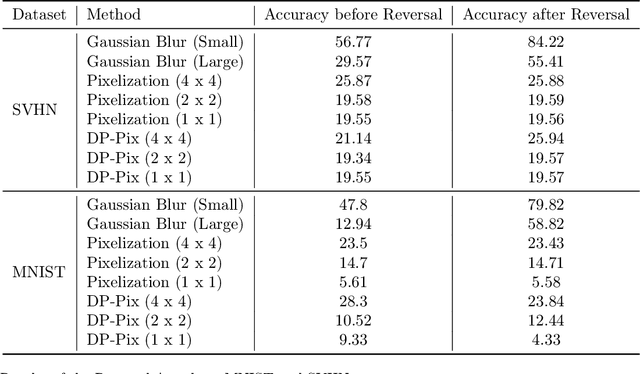

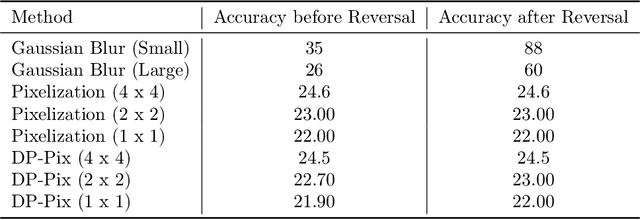
Image data collected in the wild often contains private information such as faces and license plates, and responsible data release must ensure that this information stays hidden. At the same time, released data should retain its usefulness for model-training. The standard method for private information obfuscation in images is Gaussian blurring. In this work, we show that practical implementations of Gaussian blurring are reversible enough to break privacy. We then take a closer look at the privacy-utility tradeoffs offered by three other obfuscation algorithms -- pixelization, pixelization and noise addition (DP-Pix), and cropping. Privacy is evaluated by reversal and discrimination attacks, while utility by the quality of the learnt representations when the model is trained on data with obfuscated faces. We show that the most popular industry-standard method, Gaussian blur is the least private of the four -- being susceptible to reversal attacks in its practical low-precision implementations. In contrast, pixelization and pixelization plus noise addition, when used at the right level of granularity, offer both privacy and utility for a number of computer vision tasks. We make our proposed methods together with suggested parameters available in a software package called Privacy Blur.
Observational Auditing of Label Privacy
Nov 18, 2025Differential privacy (DP) auditing is essential for evaluating privacy guarantees in machine learning systems. Existing auditing methods, however, pose a significant challenge for large-scale systems since they require modifying the training dataset -- for instance, by injecting out-of-distribution canaries or removing samples from training. Such interventions on the training data pipeline are resource-intensive and involve considerable engineering overhead. We introduce a novel observational auditing framework that leverages the inherent randomness of data distributions, enabling privacy evaluation without altering the original dataset. Our approach extends privacy auditing beyond traditional membership inference to protected attributes, with labels as a special case, addressing a key gap in existing techniques. We provide theoretical foundations for our method and perform experiments on Criteo and CIFAR-10 datasets that demonstrate its effectiveness in auditing label privacy guarantees. This work opens new avenues for practical privacy auditing in large-scale production environments.
Machine Learning with Privacy for Protected Attributes
Jun 24, 2025



Differential privacy (DP) has become the standard for private data analysis. Certain machine learning applications only require privacy protection for specific protected attributes. Using naive variants of differential privacy in such use cases can result in unnecessary degradation of utility. In this work, we refine the definition of DP to create a more general and flexible framework that we call feature differential privacy (FDP). Our definition is simulation-based and allows for both addition/removal and replacement variants of privacy, and can handle arbitrary and adaptive separation of protected and non-protected features. We prove the properties of FDP, such as adaptive composition, and demonstrate its implications for limiting attribute inference attacks. We also propose a modification of the standard DP-SGD algorithm that satisfies FDP while leveraging desirable properties such as amplification via sub-sampling. We apply our framework to various machine learning tasks and show that it can significantly improve the utility of DP-trained models when public features are available. For example, we train diffusion models on the AFHQ dataset of animal faces and observe a drastic improvement in FID compared to DP, from 286.7 to 101.9 at $\epsilon=8$, assuming that the blurred version of a training image is available as a public feature. Overall, our work provides a new approach to private data analysis that can help reduce the utility cost of DP while still providing strong privacy guarantees.
How much do language models memorize?
May 30, 2025We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point ``grokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from $500K$ to $1.5B$ parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
Detecting Benchmark Contamination Through Watermarking
Feb 24, 2025
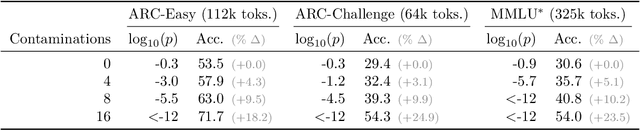
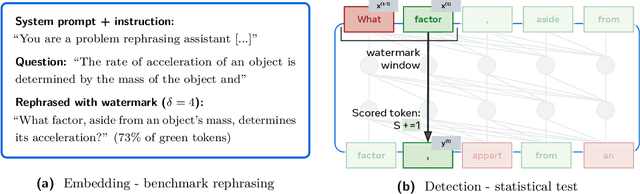
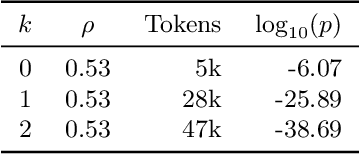
Benchmark contamination poses a significant challenge to the reliability of Large Language Models (LLMs) evaluations, as it is difficult to assert whether a model has been trained on a test set. We introduce a solution to this problem by watermarking benchmarks before their release. The embedding involves reformulating the original questions with a watermarked LLM, in a way that does not alter the benchmark utility. During evaluation, we can detect ``radioactivity'', \ie traces that the text watermarks leave in the model during training, using a theoretically grounded statistical test. We test our method by pre-training 1B models from scratch on 10B tokens with controlled benchmark contamination, and validate its effectiveness in detecting contamination on ARC-Easy, ARC-Challenge, and MMLU. Results show similar benchmark utility post-watermarking and successful contamination detection when models are contaminated enough to enhance performance, e.g. $p$-val $=10^{-3}$ for +5$\%$ on ARC-Easy.
Unlocking Visual Secrets: Inverting Features with Diffusion Priors for Image Reconstruction
Dec 11, 2024Inverting visual representations within deep neural networks (DNNs) presents a challenging and important problem in the field of security and privacy for deep learning. The main goal is to invert the features of an unidentified target image generated by a pre-trained DNN, aiming to reconstruct the original image. Feature inversion holds particular significance in understanding the privacy leakage inherent in contemporary split DNN execution techniques, as well as in various applications based on the extracted DNN features. In this paper, we explore the use of diffusion models, a promising technique for image synthesis, to enhance feature inversion quality. We also investigate the potential of incorporating alternative forms of prior knowledge, such as textual prompts and cross-frame temporal correlations, to further improve the quality of inverted features. Our findings reveal that diffusion models can effectively leverage hidden information from the DNN features, resulting in superior reconstruction performance compared to previous methods. This research offers valuable insights into how diffusion models can enhance privacy and security within applications that are reliant on DNN features.
Auditing $f$-Differential Privacy in One Run
Oct 29, 2024



Empirical auditing has emerged as a means of catching some of the flaws in the implementation of privacy-preserving algorithms. Existing auditing mechanisms, however, are either computationally inefficient requiring multiple runs of the machine learning algorithms or suboptimal in calculating an empirical privacy. In this work, we present a tight and efficient auditing procedure and analysis that can effectively assess the privacy of mechanisms. Our approach is efficient; similar to the recent work of Steinke, Nasr, and Jagielski (2023), our auditing procedure leverages the randomness of examples in the input dataset and requires only a single run of the target mechanism. And it is more accurate; we provide a novel analysis that enables us to achieve tight empirical privacy estimates by using the hypothesized $f$-DP curve of the mechanism, which provides a more accurate measure of privacy than the traditional $\epsilon,\delta$ differential privacy parameters. We use our auditing procure and analysis to obtain empirical privacy, demonstrating that our auditing procedure delivers tighter privacy estimates.
Aligning LLMs to Be Robust Against Prompt Injection
Oct 07, 2024



Large language models (LLMs) are becoming increasingly prevalent in modern software systems, interfacing between the user and the internet to assist with tasks that require advanced language understanding. To accomplish these tasks, the LLM often uses external data sources such as user documents, web retrieval, results from API calls, etc. This opens up new avenues for attackers to manipulate the LLM via prompt injection. Adversarial prompts can be carefully crafted and injected into external data sources to override the user's intended instruction and instead execute a malicious instruction. Prompt injection attacks constitute a major threat to LLM security, making the design and implementation of practical countermeasures of paramount importance. To this end, we show that alignment can be a powerful tool to make LLMs more robust against prompt injection. Our method -- SecAlign -- first builds an alignment dataset by simulating prompt injection attacks and constructing pairs of desirable and undesirable responses. Then, we apply existing alignment techniques to fine-tune the LLM to be robust against these simulated attacks. Our experiments show that SecAlign robustifies the LLM substantially with a negligible hurt on model utility. Moreover, SecAlign's protection generalizes to strong attacks unseen in training. Specifically, the success rate of state-of-the-art GCG-based prompt injections drops from 56% to 2% in Mistral-7B after our alignment process. Our code is released at https://github.com/facebookresearch/SecAlign
Guarantees of confidentiality via Hammersley-Chapman-Robbins bounds
Apr 06, 2024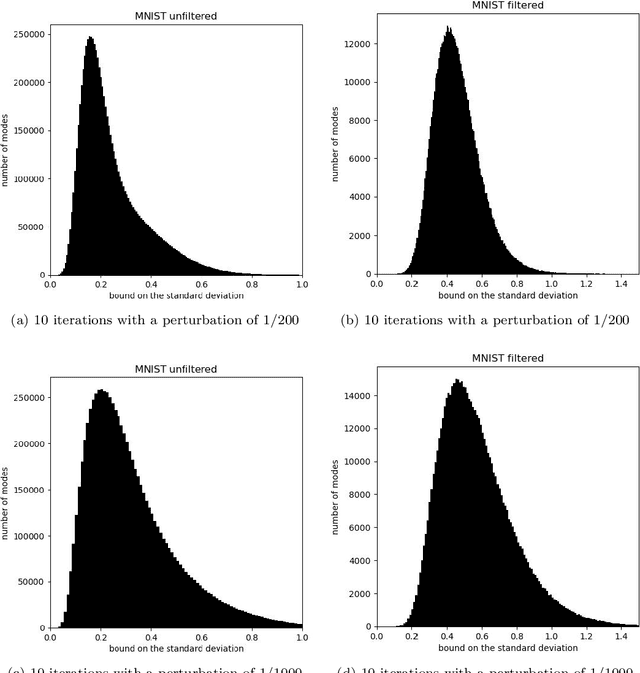

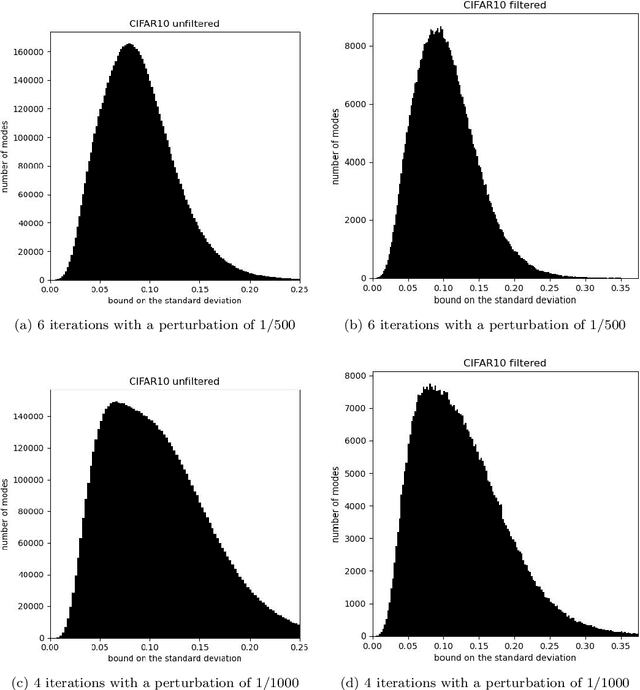

Protecting privacy during inference with deep neural networks is possible by adding noise to the activations in the last layers prior to the final classifiers or other task-specific layers. The activations in such layers are known as "features" (or, less commonly, as "embeddings" or "feature embeddings"). The added noise helps prevent reconstruction of the inputs from the noisy features. Lower bounding the variance of every possible unbiased estimator of the inputs quantifies the confidentiality arising from such added noise. Convenient, computationally tractable bounds are available from classic inequalities of Hammersley and of Chapman and Robbins -- the HCR bounds. Numerical experiments indicate that the HCR bounds are on the precipice of being effectual for small neural nets with the data sets, "MNIST" and "CIFAR-10," which contain 10 classes each for image classification. The HCR bounds appear to be insufficient on their own to guarantee confidentiality of the inputs to inference with standard deep neural nets, "ResNet-18" and "Swin-T," pre-trained on the data set, "ImageNet-1000," which contains 1000 classes. Supplementing the addition of noise to features with other methods for providing confidentiality may be warranted in the case of ImageNet. In all cases, the results reported here limit consideration to amounts of added noise that incur little degradation in the accuracy of classification from the noisy features. Thus, the added noise enhances confidentiality without much reduction in the accuracy on the task of image classification.