 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Prompt Guards in Production with Controlled-Release Prompting
Oct 02, 2025As large language models (LLMs) advance, ensuring AI safety and alignment is paramount. One popular approach is prompt guards, lightweight mechanisms designed to filter malicious queries while being easy to implement and update. In this work, we introduce a new attack that circumvents such prompt guards, highlighting their limitations. Our method consistently jailbreaks production models while maintaining response quality, even under the highly protected chat interfaces of Google Gemini (2.5 Flash/Pro), DeepSeek Chat (DeepThink), Grok (3), and Mistral Le Chat (Magistral). The attack exploits a resource asymmetry between the prompt guard and the main LLM, encoding a jailbreak prompt that lightweight guards cannot decode but the main model can. This reveals an attack surface inherent to lightweight prompt guards in modern LLM architectures and underscores the need to shift defenses from blocking malicious inputs to preventing malicious outputs. We additionally identify other critical alignment issues, such as copyrighted data extraction, training data extraction, and malicious response leakage during thinking.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
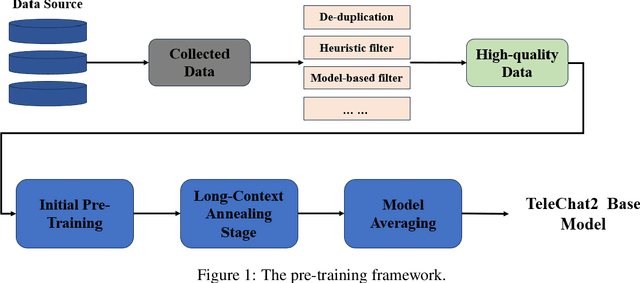

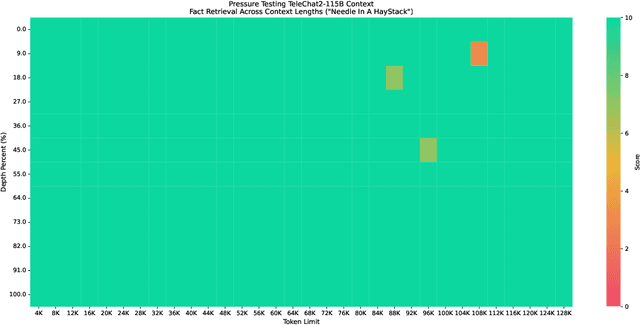
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
Exploring Neural Network Pruning with Screening Methods
Feb 11, 2025Deep neural networks (DNNs) such as convolutional neural networks (CNNs) for visual tasks, recurrent neural networks (RNNs) for sequence data, and transformer models for rich linguistic or multimodal tasks, achieved unprecedented performance on a wide range of tasks. The impressive performance of modern DNNs is partially attributed to their sheer scale. The latest deep learning models have tens to hundreds of millions of parameters which makes the inference processes resource-intensive. The high computational complexity of these networks prevents their deployment on resource-limited devices such as mobile platforms, IoT devices, and edge computing systems because these devices require energy-efficient and real-time processing capabilities. This paper proposes and evaluates a network pruning framework that eliminates non-essential parameters based on a statistical analysis of network component significance across classification categories. The proposed method uses screening methods coupled with a weighted scheme to assess connection and channel contributions for unstructured and structured pruning which allows for the elimination of unnecessary network elements without significantly degrading model performance. Extensive experimental validation on real-world vision datasets for both fully connected neural networks (FNNs) and CNNs has shown that the proposed framework produces competitive lean networks compared to the original networks. Moreover, the proposed framework outperforms state-of-art network pruning methods in two out of three cases.
Publicly Detectable Watermarking for Language Models
Oct 27, 2023We construct the first provable watermarking scheme for language models with public detectability or verifiability: we use a private key for watermarking and a public key for watermark detection. Our protocol is the first watermarking scheme that does not embed a statistical signal in generated text. Rather, we directly embed a publicly-verifiable cryptographic signature using a form of rejection sampling. We show that our construction meets strong formal security guarantees and preserves many desirable properties found in schemes in the private-key watermarking setting. In particular, our watermarking scheme retains distortion-freeness and model agnosticity. We implement our scheme and make empirical measurements over open models in the 7B parameter range. Our experiments suggest that our watermarking scheme meets our formal claims while preserving text quality.
RDFC-GAN: RGB-Depth Fusion CycleGAN for Indoor Depth Completion
Jun 06, 2023The raw depth image captured by indoor depth sensors usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and the limited distance range. The incomplete depth map with missing values burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing large contiguous regions of missing depth values, which is common and critical in images captured in indoor environments. To overcome these challenges, we design a novel two-branch end-to-end fusion network named RDFC-GAN, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure, by adhering to the Manhattan world assumption and utilizing normal maps from RGB-D information as guidance, to regress the local dense depth values from the raw depth map. In the other branch, we propose an RGB-depth fusion CycleGAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments, with the help of our proposed pseudo depth maps in training.
Overparameterized (robust) models from computational constraints
Aug 27, 2022Overparameterized models with millions of parameters have been hugely successful. In this work, we ask: can the need for large models be, at least in part, due to the \emph{computational} limitations of the learner? Additionally, we ask, is this situation exacerbated for \emph{robust} learning? We show that this indeed could be the case. We show learning tasks for which computationally bounded learners need \emph{significantly more} model parameters than what information-theoretic learners need. Furthermore, we show that even more model parameters could be necessary for robust learning. In particular, for computationally bounded learners, we extend the recent result of Bubeck and Sellke [NeurIPS'2021] which shows that robust models might need more parameters, to the computational regime and show that bounded learners could provably need an even larger number of parameters. Then, we address the following related question: can we hope to remedy the situation for robust computationally bounded learning by restricting \emph{adversaries} to also be computationally bounded for sake of obtaining models with fewer parameters? Here again, we show that this could be possible. Specifically, building on the work of Garg, Jha, Mahloujifar, and Mahmoody [ALT'2020], we demonstrate a learning task that can be learned efficiently and robustly against a computationally bounded attacker, while to be robust against an information-theoretic attacker requires the learner to utilize significantly more parameters.
RGB-Depth Fusion GAN for Indoor Depth Completion
Mar 21, 2022



The raw depth image captured by the indoor depth sensor usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and limited distance range. The incomplete depth map burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing the large contiguous regions of missing depth values, which is common and critical. In this paper, we design a novel two-branch end-to-end fusion network, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure to regress the local dense depth values from the raw depth map, with the help of local guidance information extracted from the RGB image. In the other branch, we propose an RGB-depth fusion GAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments with the help of the pseudo depth map.
Online Feature Screening for Data Streams with Concept Drift
Apr 07, 2021
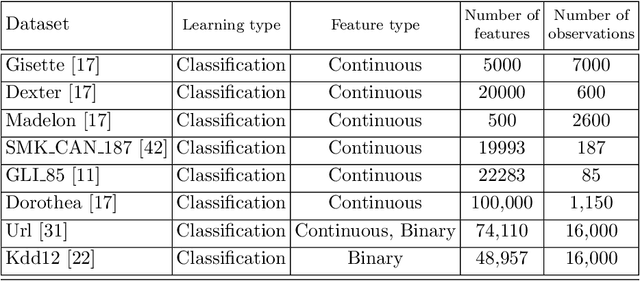
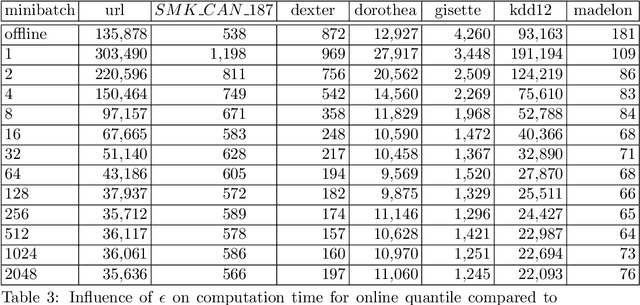

Screening feature selection methods are often used as a preprocessing step for reducing the number of variables before training step. Traditional screening methods only focus on dealing with complete high dimensional datasets. Modern datasets not only have higher dimension and larger sample size, but also have properties such as streaming input, sparsity and concept drift. Therefore a considerable number of online feature selection methods were introduced to handle these kind of problems in recent years. Online screening methods are one of the categories of online feature selection methods. The methods that we proposed in this research are capable of handling all three situations mentioned above. Our research study focuses on classification datasets. Our experiments show proposed methods can generate the same feature importance as their offline version with faster speed and less storage consumption. Furthermore, the results show that online screening methods with integrated model adaptation have a higher true feature detection rate than without model adaptation on data streams with the concept drift property. Among the two large real datasets that potentially have the concept drift property, online screening methods with model adaptation show advantages in either saving computing time and space, reducing model complexity, or improving prediction accuracy.
Are screening methods useful in feature selection? An empirical study
Sep 14, 2018



Filter or screening methods are often used as a preprocessing step for reducing the number of variables used by a learning algorithm in obtaining a classification or regression model. While there are many such filter methods, there is a need for an objective evaluation of these methods. Such an evaluation is needed to compare them with each other and also to answer whether they are at all useful, or a learning algorithm could do a better job without them. For this purpose, many popular screening methods are partnered in this paper with three regression learners and five classification learners and evaluated on ten real datasets to obtain accuracy criteria such as R-square and area under the ROC curve (AUC). The obtained results are compared through curve plots and comparison tables in order to find out whether screening methods help improve the performance of learning algorithms and how they fare with each other. Our findings revealed that the screening methods were only useful in one regression and three classification datasets out of the ten datasets evaluated.