 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtGen: Conditional Generative Modeling of Articulated Objects in Arbitrary Part-Level States
Dec 13, 2025Generating articulated assets is crucial for robotics, digital twins, and embodied intelligence. Existing generative models often rely on single-view inputs representing closed states, resulting in ambiguous or unrealistic kinematic structures due to the entanglement between geometric shape and joint dynamics. To address these challenges, we introduce ArtGen, a conditional diffusion-based framework capable of generating articulated 3D objects with accurate geometry and coherent kinematics from single-view images or text descriptions at arbitrary part-level states. Specifically, ArtGen employs cross-state Monte Carlo sampling to explicitly enforce global kinematic consistency, reducing structural-motion entanglement. Additionally, we integrate a Chain-of-Thought reasoning module to infer robust structural priors, such as part semantics, joint types, and connectivity, guiding a sparse-expert Diffusion Transformer to specialize in diverse kinematic interactions. Furthermore, a compositional 3D-VAE latent prior enhanced with local-global attention effectively captures fine-grained geometry and global part-level relationships. Extensive experiments on the PartNet-Mobility benchmark demonstrate that ArtGen significantly outperforms state-of-the-art methods.
SM$^3$: Self-Supervised Multi-task Modeling with Multi-view 2D Images for Articulated Objects
Jan 17, 2024



Reconstructing real-world objects and estimating their movable joint structures are pivotal technologies within the field of robotics. Previous research has predominantly focused on supervised approaches, relying on extensively annotated datasets to model articulated objects within limited categories. However, this approach falls short of effectively addressing the diversity present in the real world. To tackle this issue, we propose a self-supervised interaction perception method, referred to as SM$^3$, which leverages multi-view RGB images captured before and after interaction to model articulated objects, identify the movable parts, and infer the parameters of their rotating joints. By constructing 3D geometries and textures from the captured 2D images, SM$^3$ achieves integrated optimization of movable part and joint parameters during the reconstruction process, obviating the need for annotations. Furthermore, we introduce the MMArt dataset, an extension of PartNet-Mobility, encompassing multi-view and multi-modal data of articulated objects spanning diverse categories. Evaluations demonstrate that SM$^3$ surpasses existing benchmarks across various categories and objects, while its adaptability in real-world scenarios has been thoroughly validated.
DTF-Net: Category-Level Pose Estimation and Shape Reconstruction via Deformable Template Field
Aug 04, 2023
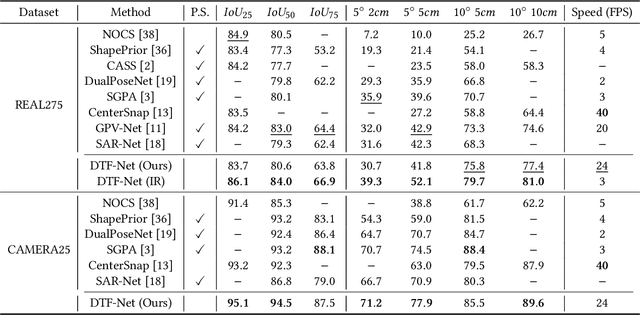


Estimating 6D poses and reconstructing 3D shapes of objects in open-world scenes from RGB-depth image pairs is challenging. Many existing methods rely on learning geometric features that correspond to specific templates while disregarding shape variations and pose differences among objects in the same category. As a result, these methods underperform when handling unseen object instances in complex environments. In contrast, other approaches aim to achieve category-level estimation and reconstruction by leveraging normalized geometric structure priors, but the static prior-based reconstruction struggles with substantial intra-class variations. To solve these problems, we propose the DTF-Net, a novel framework for pose estimation and shape reconstruction based on implicit neural fields of object categories. In DTF-Net, we design a deformable template field to represent the general category-wise shape latent features and intra-category geometric deformation features. The field establishes continuous shape correspondences, deforming the category template into arbitrary observed instances to accomplish shape reconstruction. We introduce a pose regression module that shares the deformation features and template codes from the fields to estimate the accurate 6D pose of each object in the scene. We integrate a multi-modal representation extraction module to extract object features and semantic masks, enabling end-to-end inference. Moreover, during training, we implement a shape-invariant training strategy and a viewpoint sampling method to further enhance the model's capability to extract object pose features. Extensive experiments on the REAL275 and CAMERA25 datasets demonstrate the superiority of DTF-Net in both synthetic and real scenes. Furthermore, we show that DTF-Net effectively supports grasping tasks with a real robot arm.
RDFC-GAN: RGB-Depth Fusion CycleGAN for Indoor Depth Completion
Jun 06, 2023The raw depth image captured by indoor depth sensors usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and the limited distance range. The incomplete depth map with missing values burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing large contiguous regions of missing depth values, which is common and critical in images captured in indoor environments. To overcome these challenges, we design a novel two-branch end-to-end fusion network named RDFC-GAN, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure, by adhering to the Manhattan world assumption and utilizing normal maps from RGB-D information as guidance, to regress the local dense depth values from the raw depth map. In the other branch, we propose an RGB-depth fusion CycleGAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments, with the help of our proposed pseudo depth maps in training.
RGB-Depth Fusion GAN for Indoor Depth Completion
Mar 21, 2022



The raw depth image captured by the indoor depth sensor usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and limited distance range. The incomplete depth map burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing the large contiguous regions of missing depth values, which is common and critical. In this paper, we design a novel two-branch end-to-end fusion network, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure to regress the local dense depth values from the raw depth map, with the help of local guidance information extracted from the RGB image. In the other branch, we propose an RGB-depth fusion GAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments with the help of the pseudo depth map.