 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Latent Factor Models
Dec 13, 2024Feature selection is crucial for pinpointing relevant features in high-dimensional datasets, mitigating the 'curse of dimensionality,' and enhancing machine learning performance. Traditional feature selection methods for classification use data from all classes to select features for each class. This paper explores feature selection methods that select features for each class separately, using class models based on low-rank generative methods and introducing a signal-to-noise ratio (SNR) feature selection criterion. This novel approach has theoretical true feature recovery guarantees under certain assumptions and is shown to outperform some existing feature selection methods on standard classification datasets.
Latent Image and Video Resolution Prediction using Convolutional Neural Networks
Oct 17, 2024



This paper introduces a Video Quality Assessment (VQA) problem that has received little attention in the literature, called the latent resolution prediction problem. The problem arises when images or videos are upscaled from their native resolution and are reported as having a higher resolution than their native resolution. This paper formulates the problem, constructs a dataset for training and evaluation, and introduces several machine learning algorithms, including two Convolutional Neural Networks (CNNs), to address this problem. Experiments indicate that some proposed methods can predict the latent video resolution with about 95% accuracy.
A Study of Shape Modeling Against Noise
Feb 23, 2024
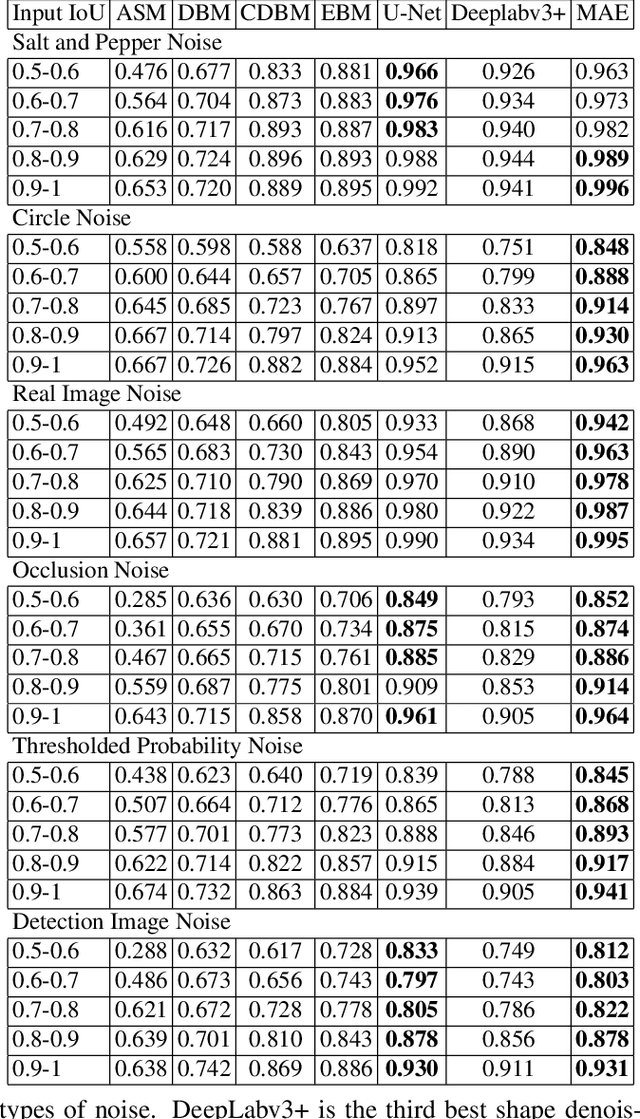

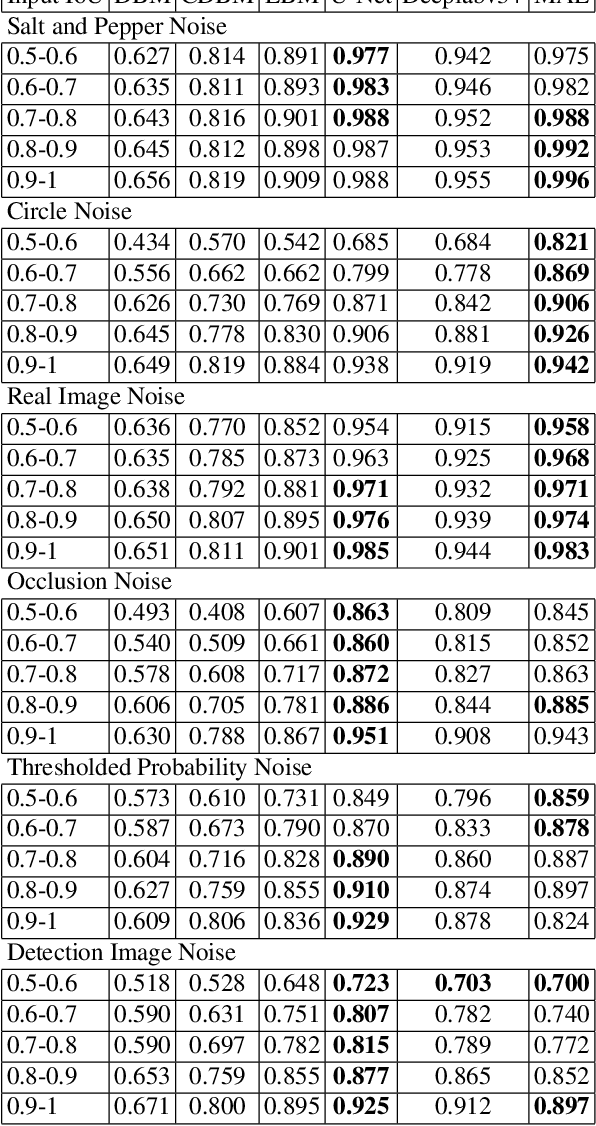
Shape modeling is a challenging task with many potential applications in computer vision and medical imaging. There are many shape modeling methods in the literature, each with its advantages and applications. However, many shape modeling methods have difficulties handling shapes that have missing pieces or outliers. In this regard, this paper introduces shape denoising, a fundamental problem in shape modeling that lies at the core of many computer vision and medical imaging applications and has not received enough attention in the literature. The paper introduces six types of noise that can be used to perturb shapes as well as an objective measure for the noise level and for comparing methods on their shape denoising capabilities. Finally, the paper evaluates seven methods capable of accomplishing this task, of which six are based on deep learning, including some generative models.
Slow Kill for Big Data Learning
May 02, 2023
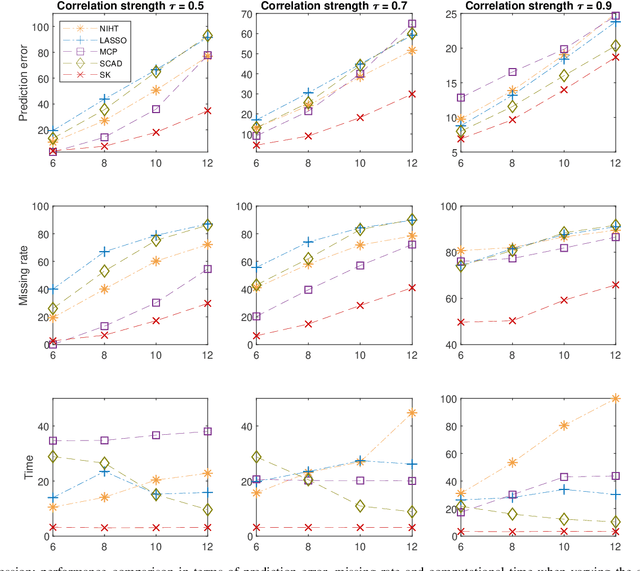
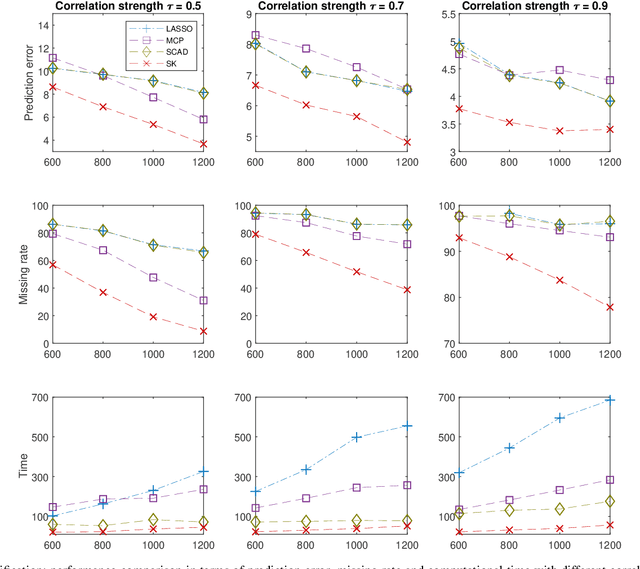
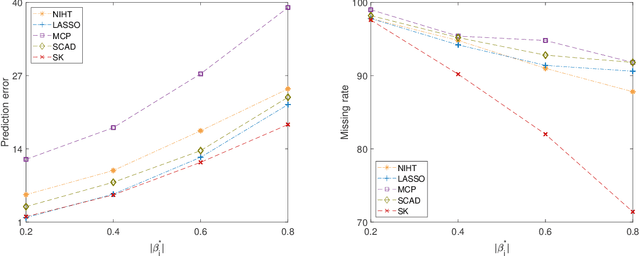
Big-data applications often involve a vast number of observations and features, creating new challenges for variable selection and parameter estimation. This paper presents a novel technique called ``slow kill,'' which utilizes nonconvex constrained optimization, adaptive $\ell_2$-shrinkage, and increasing learning rates. The fact that the problem size can decrease during the slow kill iterations makes it particularly effective for large-scale variable screening. The interaction between statistics and optimization provides valuable insights into controlling quantiles, stepsize, and shrinkage parameters in order to relax the regularity conditions required to achieve the desired level of statistical accuracy. Experimental results on real and synthetic data show that slow kill outperforms state-of-the-art algorithms in various situations while being computationally efficient for large-scale data.
Training a Two Layer ReLU Network Analytically
Apr 06, 2023Neural networks are usually trained with different variants of gradient descent based optimization algorithms such as stochastic gradient descent or the Adam optimizer. Recent theoretical work states that the critical points (where the gradient of the loss is zero) of two-layer ReLU networks with the square loss are not all local minima. However, in this work we will explore an algorithm for training two-layer neural networks with ReLU-like activation and the square loss that alternatively finds the critical points of the loss function analytically for one layer while keeping the other layer and the neuron activation pattern fixed. Experiments indicate that this simple algorithm can find deeper optima than Stochastic Gradient Descent or the Adam optimizer, obtaining significantly smaller training loss values on four out of the five real datasets evaluated. Moreover, the method is faster than the gradient descent methods and has virtually no tuning parameters.
Feature Selection for Forecasting
Mar 08, 2023This work investigates the importance of feature selection for improving the forecasting performance of machine learning algorithms for financial data. Artificial neural networks (ANN), convolutional neural networks (CNN), long-short term memory (LSTM) networks, as well as linear models were applied for forecasting purposes. The Feature Selection with Annealing (FSA) algorithm was used to select the features from about 1000 possible predictors obtained from 26 technical indicators with specific periods and their lags. In addition to this, the Boruta feature selection algorithm was applied as a baseline feature selection method. The dependent variables consisted of daily logarithmic returns and daily trends of ten financial data sets, including cryptocurrency and different stocks. Experiments indicate that the FSA algorithm increased the performance of ML models regardless of the problem type. The FSA hybrid machine learning models showed better performance in 10 out of 10 data sets for regression and 8 out of 10 data sets for classification. None of the hybrid Boruta models outperformed the hybrid FSA models. However, the BORCNN model performance was comparable to the best model for 4 out of 10 data sets for regression estimates. BOR-LR and BOR-CNN models showed comparable performance with the best hybrid FSA models in 2 out of 10 datasets for classification. FSA was observed to improve the model performance in both better performance metrics as well as a decreased computation time by providing a lower dimensional input feature space.
Scalable Clustering: Large Scale Unsupervised Learning of Gaussian Mixture Models with Outliers
Feb 28, 2023
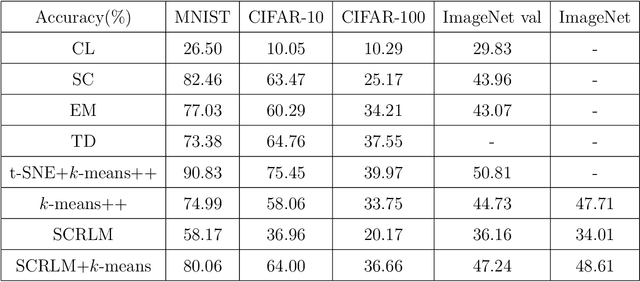
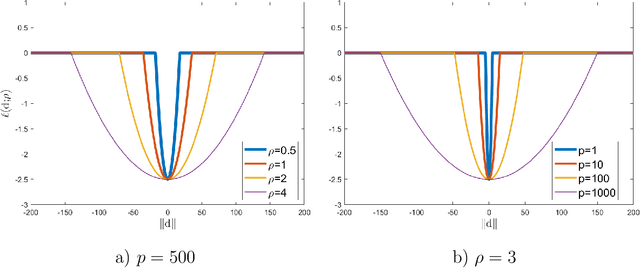
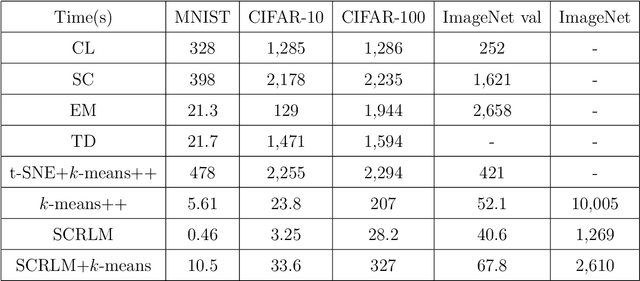
Clustering is a widely used technique with a long and rich history in a variety of areas. However, most existing algorithms do not scale well to large datasets, or are missing theoretical guarantees of convergence. This paper introduces a provably robust clustering algorithm based on loss minimization that performs well on Gaussian mixture models with outliers. It provides theoretical guarantees that the algorithm obtains high accuracy with high probability under certain assumptions. Moreover, it can also be used as an initialization strategy for $k$-means clustering. Experiments on real-world large-scale datasets demonstrate the effectiveness of the algorithm when clustering a large number of clusters, and a $k$-means algorithm initialized by the algorithm outperforms many of the classic clustering methods in both speed and accuracy, while scaling well to large datasets such as ImageNet.
Online Feature Screening for Data Streams with Concept Drift
Apr 07, 2021
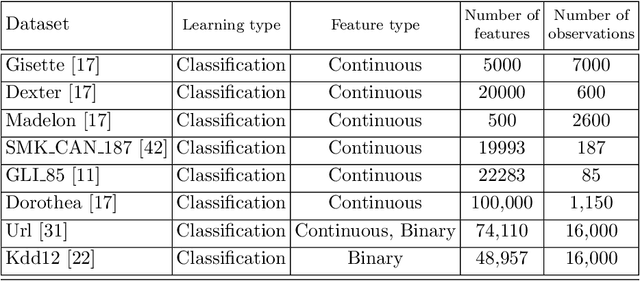
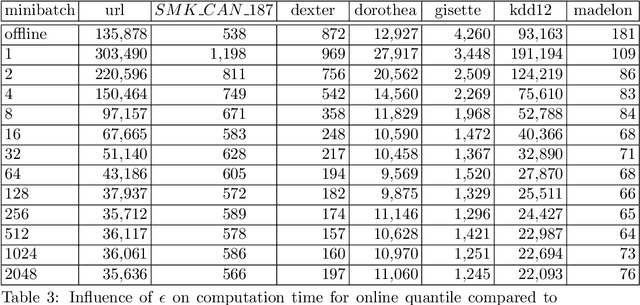

Screening feature selection methods are often used as a preprocessing step for reducing the number of variables before training step. Traditional screening methods only focus on dealing with complete high dimensional datasets. Modern datasets not only have higher dimension and larger sample size, but also have properties such as streaming input, sparsity and concept drift. Therefore a considerable number of online feature selection methods were introduced to handle these kind of problems in recent years. Online screening methods are one of the categories of online feature selection methods. The methods that we proposed in this research are capable of handling all three situations mentioned above. Our research study focuses on classification datasets. Our experiments show proposed methods can generate the same feature importance as their offline version with faster speed and less storage consumption. Furthermore, the results show that online screening methods with integrated model adaptation have a higher true feature detection rate than without model adaptation on data streams with the concept drift property. Among the two large real datasets that potentially have the concept drift property, online screening methods with model adaptation show advantages in either saving computing time and space, reducing model complexity, or improving prediction accuracy.
The Compact Support Neural Network
Apr 01, 2021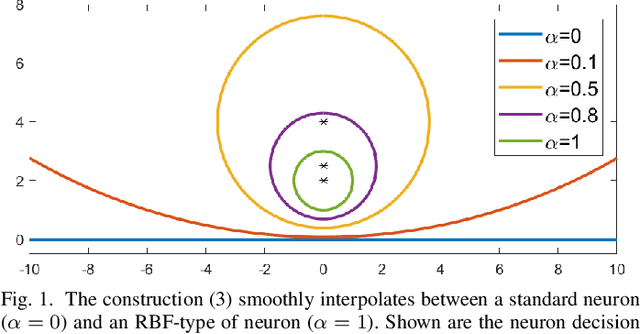
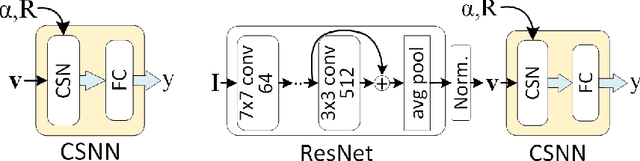
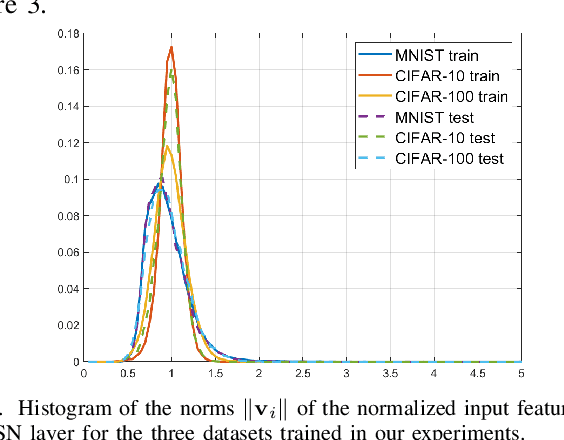
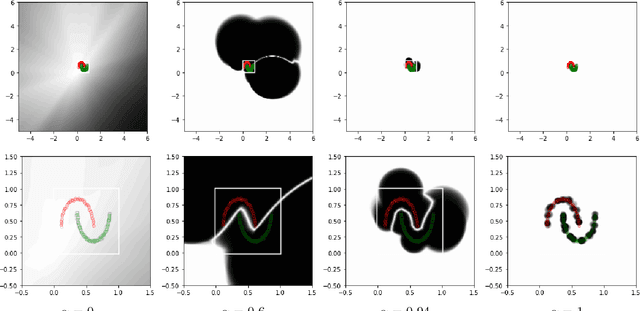
Neural networks are popular and useful in many fields, but they have the problem of giving high confidence responses for examples that are away from the training data. This makes the neural networks very confident in their prediction while making gross mistakes, thus limiting their reliability for safety-critical applications such as autonomous driving, space exploration, etc. In this paper, we present a neuron generalization that has the standard dot-product-based neuron and the RBF neuron as two extreme cases of a shape parameter. Using ReLU as the activation function we obtain a novel neuron that has compact support, which means its output is zero outside a bounded domain. We show how to avoid difficulties in training a neural network with such neurons, by starting with a trained standard neural network and gradually increasing the shape parameter to the desired value. Through experiments on standard benchmark datasets, we show the promise of the proposed approach, in that it can have good prediction accuracy on in-distribution samples while being able to consistently detect and have low confidence on out-of-distribution samples.
A study of local optima for learning feature interactions using neural networks
Feb 11, 2020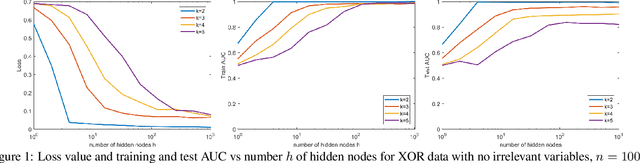
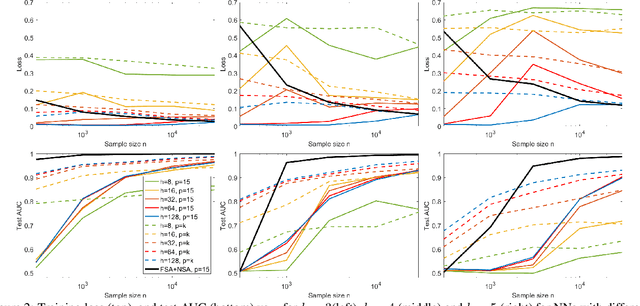
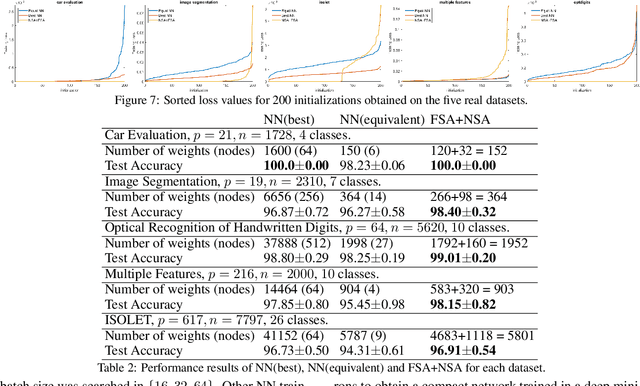
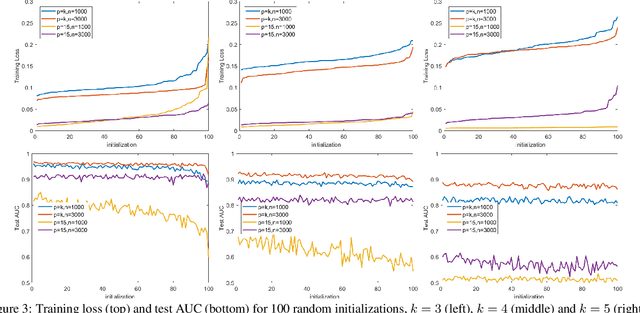
In many fields such as bioinformatics, high energy physics, power distribution, etc., it is desirable to learn non-linear models where a small number of variables are selected and the interaction between them is explicitly modeled to predict the response. In principle, neural networks (NNs) could accomplish this task since they can model non-linear feature interactions very well. However, NNs require large amounts of training data to have a good generalization. In this paper we study the datastarved regime where a NN is trained on a relatively small amount of training data. For that purpose we study feature selection for NNs, which is known to improve generalization for linear models. As an extreme case of data with feature selection and feature interactions we study the XOR-like data with irrelevant variables. We experimentally observed that the cross-entropy loss function on XOR-like data has many non-equivalent local optima, and the number of local optima grows exponentially with the number of irrelevant variables. To deal with the local minima and for feature selection we propose a node pruning and feature selection algorithm that improves the capability of NNs to find better local minima even when there are irrelevant variables. Finally, we show that the performance of a NN on real datasets can be improved using pruning, obtaining compact networks on a small number of features, with good prediction and interpretability.