 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Neural Network Pruning with Screening Methods
Feb 11, 2025



Deep neural networks (DNNs) such as convolutional neural networks (CNNs) for visual tasks, recurrent neural networks (RNNs) for sequence data, and transformer models for rich linguistic or multimodal tasks, achieved unprecedented performance on a wide range of tasks. The impressive performance of modern DNNs is partially attributed to their sheer scale. The latest deep learning models have tens to hundreds of millions of parameters which makes the inference processes resource-intensive. The high computational complexity of these networks prevents their deployment on resource-limited devices such as mobile platforms, IoT devices, and edge computing systems because these devices require energy-efficient and real-time processing capabilities. This paper proposes and evaluates a network pruning framework that eliminates non-essential parameters based on a statistical analysis of network component significance across classification categories. The proposed method uses screening methods coupled with a weighted scheme to assess connection and channel contributions for unstructured and structured pruning which allows for the elimination of unnecessary network elements without significantly degrading model performance. Extensive experimental validation on real-world vision datasets for both fully connected neural networks (FNNs) and CNNs has shown that the proposed framework produces competitive lean networks compared to the original networks. Moreover, the proposed framework outperforms state-of-art network pruning methods in two out of three cases.
A study of local optima for learning feature interactions using neural networks
Feb 11, 2020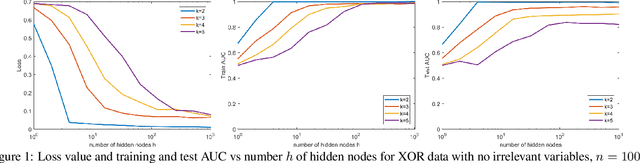
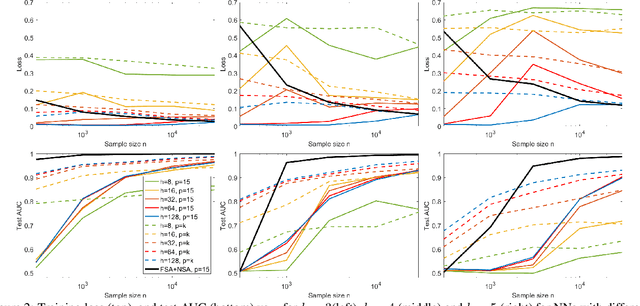
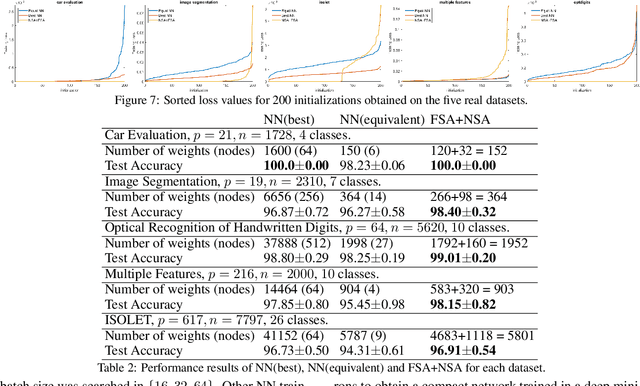
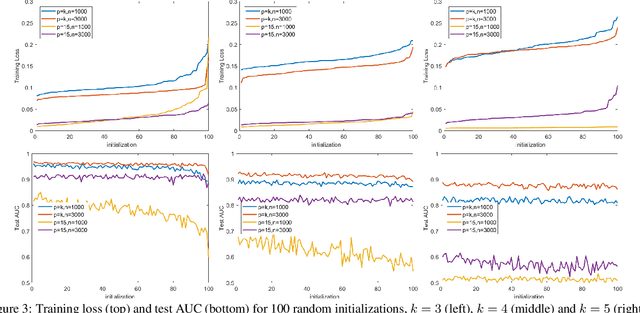
In many fields such as bioinformatics, high energy physics, power distribution, etc., it is desirable to learn non-linear models where a small number of variables are selected and the interaction between them is explicitly modeled to predict the response. In principle, neural networks (NNs) could accomplish this task since they can model non-linear feature interactions very well. However, NNs require large amounts of training data to have a good generalization. In this paper we study the datastarved regime where a NN is trained on a relatively small amount of training data. For that purpose we study feature selection for NNs, which is known to improve generalization for linear models. As an extreme case of data with feature selection and feature interactions we study the XOR-like data with irrelevant variables. We experimentally observed that the cross-entropy loss function on XOR-like data has many non-equivalent local optima, and the number of local optima grows exponentially with the number of irrelevant variables. To deal with the local minima and for feature selection we propose a node pruning and feature selection algorithm that improves the capability of NNs to find better local minima even when there are irrelevant variables. Finally, we show that the performance of a NN on real datasets can be improved using pruning, obtaining compact networks on a small number of features, with good prediction and interpretability.
Neural Rule Ensembles: Encoding Sparse Feature Interactions into Neural Networks
Feb 11, 2020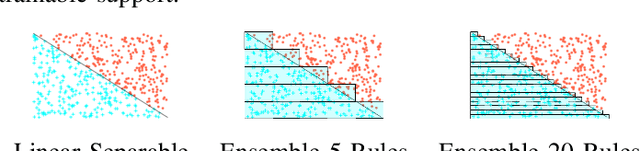
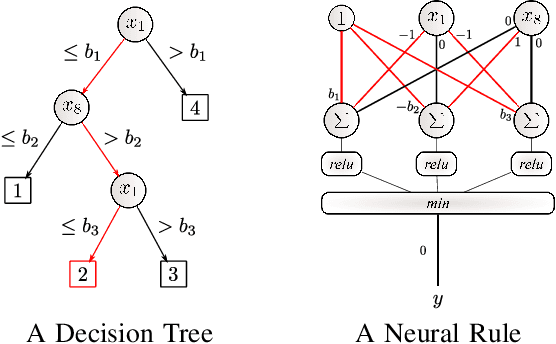
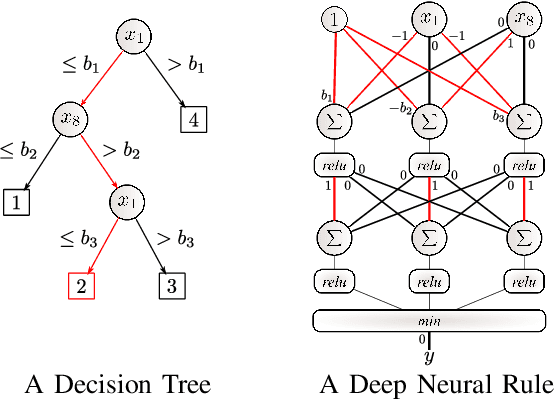

Artificial Neural Networks form the basis of very powerful learning methods. It has been observed that a naive application of fully connected neural networks to data with many irrelevant variables often leads to overfitting. In an attempt to circumvent this issue, a prior knowledge pertaining to what features are relevant and their possible feature interactions can be encoded into these networks. In this work, we use decision trees to capture such relevant features and their interactions and define a mapping to encode extracted relationships into a neural network. This addresses the initialization related concern of fully connected neural networks. At the same time through feature selection it enables learning of compact representations compared to state of the art tree-based approaches. Empirical evaluations and simulation studies show the superiority of such an approach over fully connected neural networks and tree-based approaches
Training Efficient Network Architecture and Weights via Direct Sparsity Control
Feb 11, 2020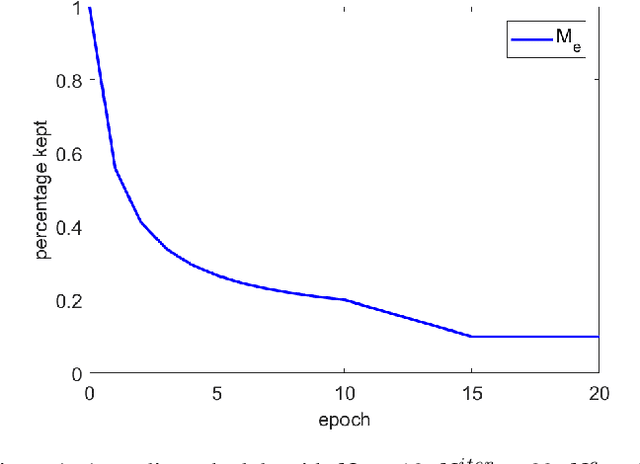
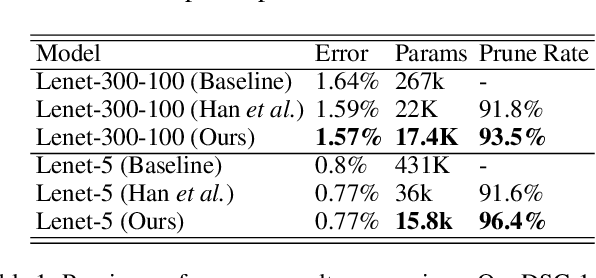
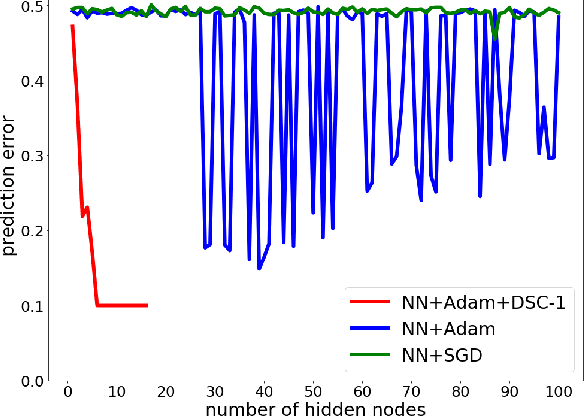
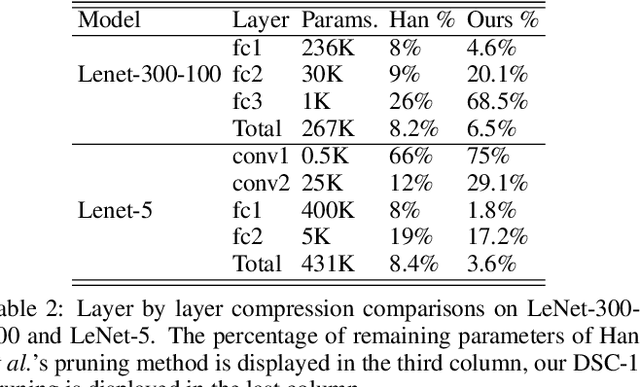
Artificial neural networks (ANNs) especially deep convolutional networks are very popular these days and have been proved to successfully offer quite reliable solutions to many vision problems. However, the use of deep neural networks is widely impeded by their intensive computational and memory cost. In this paper, we propose a novel efficient network pruning method that is suitable for both non-structured and structured channel-level pruning. Our proposed method tightens a sparsity constraint by gradually removing network parameters or filter channels based on a criterion and a schedule. The attractive fact that the network size keeps dropping throughout the iterations makes it suitable for the pruning of any untrained or pre-trained network. Because our method uses a L0 constraint instead of the L1 penalty, it does not introduce any bias in the training parameters or filter channels. Furthermore, the L0 constraint makes it easy to directly specify the desired sparsity level during the network pruning process. Finally, experimental validation on synthetic and real datasets both show that the proposed method obtains better or competitive performance compared to other states of art network pruning methods.