 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextSeal: A Localized LLM Watermark for Provenance & Distillation Protection
May 12, 2026We introduce TextSeal, a state-of-the-art watermark for large language models. Building on Gumbel-max sampling, TextSeal introduces dual-key generation to restore output diversity, along with entropy-weighted scoring and multi-region localization for improved detection. It supports serving optimizations such as speculative decoding and multi-token prediction, and does not add any inference overhead. TextSeal strictly dominates baselines like SynthID-text in detection strength and is robust to dilution, maintaining confident localized detection even in heavily mixed human/AI documents. The scheme is theoretically distortion-free, and evaluation across reasoning benchmarks confirms that it preserves downstream performance; while a multilingual human evaluation (6000 A/B comparisons, 5 languages) shows no perceptible quality difference. Beyond its use for provenance detection, TextSeal is also ``radioactive'': its watermark signal transfers through model distillation, enabling detection of unauthorized use.
Learning to Watermark in the Latent Space of Generative Models
Jan 22, 2026Existing approaches for watermarking AI-generated images often rely on post-hoc methods applied in pixel space, introducing computational overhead and potential visual artifacts. In this work, we explore latent space watermarking and introduce DistSeal, a unified approach for latent watermarking that works across both diffusion and autoregressive models. Our approach works by training post-hoc watermarking models in the latent space of generative models. We demonstrate that these latent watermarkers can be effectively distilled either into the generative model itself or into the latent decoder, enabling in-model watermarking. The resulting latent watermarks achieve competitive robustness while offering similar imperceptibility and up to 20x speedup compared to pixel-space baselines. Our experiments further reveal that distilling latent watermarkers outperforms distilling pixel-space ones, providing a solution that is both more efficient and more robust.
Pixel Seal: Adversarial-only training for invisible image and video watermarking
Dec 18, 2025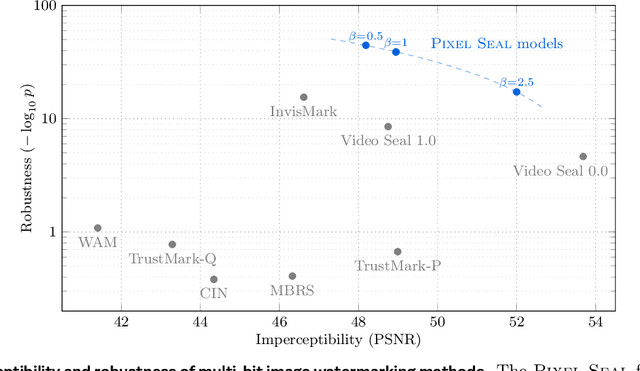
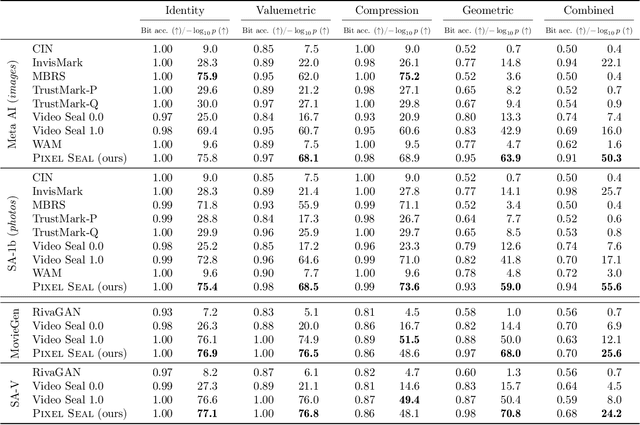
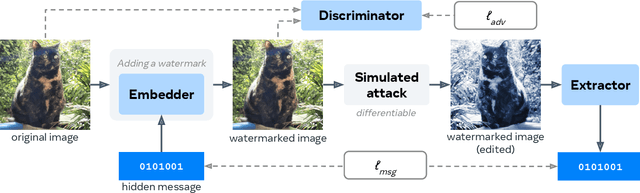
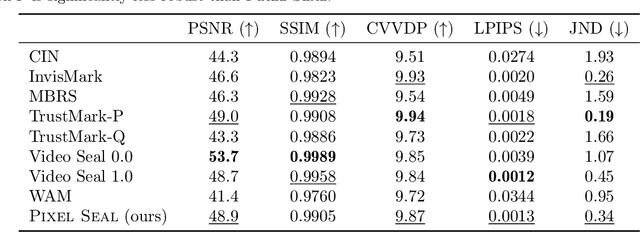
Invisible watermarking is essential for tracing the provenance of digital content. However, training state-of-the-art models remains notoriously difficult, with current approaches often struggling to balance robustness against true imperceptibility. This work introduces Pixel Seal, which sets a new state-of-the-art for image and video watermarking. We first identify three fundamental issues of existing methods: (i) the reliance on proxy perceptual losses such as MSE and LPIPS that fail to mimic human perception and result in visible watermark artifacts; (ii) the optimization instability caused by conflicting objectives, which necessitates exhaustive hyperparameter tuning; and (iii) reduced robustness and imperceptibility of watermarks when scaling models to high-resolution images and videos. To overcome these issues, we first propose an adversarial-only training paradigm that eliminates unreliable pixel-wise imperceptibility losses. Second, we introduce a three-stage training schedule that stabilizes convergence by decoupling robustness and imperceptibility. Third, we address the resolution gap via high-resolution adaptation, employing JND-based attenuation and training-time inference simulation to eliminate upscaling artifacts. We thoroughly evaluate the robustness and imperceptibility of Pixel Seal on different image types and across a wide range of transformations, and show clear improvements over the state-of-the-art. We finally demonstrate that the model efficiently adapts to video via temporal watermark pooling, positioning Pixel Seal as a practical and scalable solution for reliable provenance in real-world image and video settings.
How Good is Post-Hoc Watermarking With Language Model Rephrasing?
Dec 18, 2025Generation-time text watermarking embeds statistical signals into text for traceability of AI-generated content. We explore *post-hoc watermarking* where an LLM rewrites existing text while applying generation-time watermarking, to protect copyrighted documents, or detect their use in training or RAG via watermark radioactivity. Unlike generation-time approaches, which is constrained by how LLMs are served, this setting offers additional degrees of freedom for both generation and detection. We investigate how allocating compute (through larger rephrasing models, beam search, multi-candidate generation, or entropy filtering at detection) affects the quality-detectability trade-off. Our strategies achieve strong detectability and semantic fidelity on open-ended text such as books. Among our findings, the simple Gumbel-max scheme surprisingly outperforms more recent alternatives under nucleus sampling, and most methods benefit significantly from beam search. However, most approaches struggle when watermarking verifiable text such as code, where we counterintuitively find that smaller models outperform larger ones. This study reveals both the potential and limitations of post-hoc watermarking, laying groundwork for practical applications and future research.
Transferable Black-Box One-Shot Forging of Watermarks via Image Preference Models
Oct 23, 2025



Recent years have seen a surge in interest in digital content watermarking techniques, driven by the proliferation of generative models and increased legal pressure. With an ever-growing percentage of AI-generated content available online, watermarking plays an increasingly important role in ensuring content authenticity and attribution at scale. There have been many works assessing the robustness of watermarking to removal attacks, yet, watermark forging, the scenario when a watermark is stolen from genuine content and applied to malicious content, remains underexplored. In this work, we investigate watermark forging in the context of widely used post-hoc image watermarking. Our contributions are as follows. First, we introduce a preference model to assess whether an image is watermarked. The model is trained using a ranking loss on purely procedurally generated images without any need for real watermarks. Second, we demonstrate the model's capability to remove and forge watermarks by optimizing the input image through backpropagation. This technique requires only a single watermarked image and works without knowledge of the watermarking model, making our attack much simpler and more practical than attacks introduced in related work. Third, we evaluate our proposed method on a variety of post-hoc image watermarking models, demonstrating that our approach can effectively forge watermarks, questioning the security of current watermarking approaches. Our code and further resources are publicly available.
Geometric Image Synchronization with Deep Watermarking
Sep 18, 2025



Synchronization is the task of estimating and inverting geometric transformations (e.g., crop, rotation) applied to an image. This work introduces SyncSeal, a bespoke watermarking method for robust image synchronization, which can be applied on top of existing watermarking methods to enhance their robustness against geometric transformations. It relies on an embedder network that imperceptibly alters images and an extractor network that predicts the geometric transformation to which the image was subjected. Both networks are end-to-end trained to minimize the error between the predicted and ground-truth parameters of the transformation, combined with a discriminator to maintain high perceptual quality. We experimentally validate our method on a wide variety of geometric and valuemetric transformations, demonstrating its effectiveness in accurately synchronizing images. We further show that our synchronization can effectively upgrade existing watermarking methods to withstand geometric transformations to which they were previously vulnerable.
Detecting Benchmark Contamination Through Watermarking
Feb 24, 2025
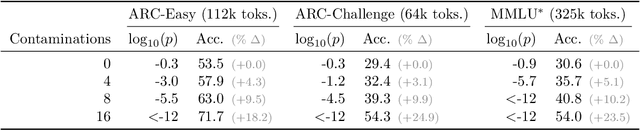
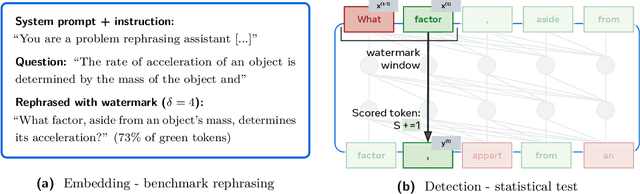
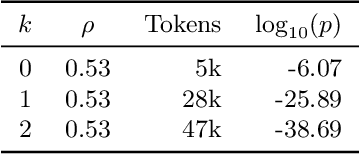
Benchmark contamination poses a significant challenge to the reliability of Large Language Models (LLMs) evaluations, as it is difficult to assert whether a model has been trained on a test set. We introduce a solution to this problem by watermarking benchmarks before their release. The embedding involves reformulating the original questions with a watermarked LLM, in a way that does not alter the benchmark utility. During evaluation, we can detect ``radioactivity'', \ie traces that the text watermarks leave in the model during training, using a theoretically grounded statistical test. We test our method by pre-training 1B models from scratch on 10B tokens with controlled benchmark contamination, and validate its effectiveness in detecting contamination on ARC-Easy, ARC-Challenge, and MMLU. Results show similar benchmark utility post-watermarking and successful contamination detection when models are contaminated enough to enhance performance, e.g. $p$-val $=10^{-3}$ for +5$\%$ on ARC-Easy.
Watermarking across Modalities for Content Tracing and Generative AI
Feb 04, 2025



Watermarking embeds information into digital content like images, audio, or text, imperceptible to humans but robustly detectable by specific algorithms. This technology has important applications in many challenges of the industry such as content moderation, tracing AI-generated content, and monitoring the usage of AI models. The contributions of this thesis include the development of new watermarking techniques for images, audio, and text. We first introduce methods for active moderation of images on social platforms. We then develop specific techniques for AI-generated content. We specifically demonstrate methods to adapt latent generative models to embed watermarks in all generated content, identify watermarked sections in speech, and improve watermarking in large language models with tests that ensure low false positive rates. Furthermore, we explore the use of digital watermarking to detect model misuse, including the detection of watermarks in language models fine-tuned on watermarked text, and introduce training-free watermarks for the weights of large transformers. Through these contributions, the thesis provides effective solutions for the challenges posed by the increasing use of generative AI models and the need for model monitoring and content moderation. It finally examines the challenges and limitations of watermarking techniques and discuss potential future directions for research in this area.
Video Seal: Open and Efficient Video Watermarking
Dec 12, 2024



The proliferation of AI-generated content and sophisticated video editing tools has made it both important and challenging to moderate digital platforms. Video watermarking addresses these challenges by embedding imperceptible signals into videos, allowing for identification. However, the rare open tools and methods often fall short on efficiency, robustness, and flexibility. To reduce these gaps, this paper introduces Video Seal, a comprehensive framework for neural video watermarking and a competitive open-sourced model. Our approach jointly trains an embedder and an extractor, while ensuring the watermark robustness by applying transformations in-between, e.g., video codecs. This training is multistage and includes image pre-training, hybrid post-training and extractor fine-tuning. We also introduce temporal watermark propagation, a technique to convert any image watermarking model to an efficient video watermarking model without the need to watermark every high-resolution frame. We present experimental results demonstrating the effectiveness of the approach in terms of speed, imperceptibility, and robustness. Video Seal achieves higher robustness compared to strong baselines especially under challenging distortions combining geometric transformations and video compression. Additionally, we provide new insights such as the impact of video compression during training, and how to compare methods operating on different payloads. Contributions in this work - including the codebase, models, and a public demo - are open-sourced under permissive licenses to foster further research and development in the field.
Watermark Anything with Localized Messages
Nov 11, 2024



Image watermarking methods are not tailored to handle small watermarked areas. This restricts applications in real-world scenarios where parts of the image may come from different sources or have been edited. We introduce a deep-learning model for localized image watermarking, dubbed the Watermark Anything Model (WAM). The WAM embedder imperceptibly modifies the input image, while the extractor segments the received image into watermarked and non-watermarked areas and recovers one or several hidden messages from the areas found to be watermarked. The models are jointly trained at low resolution and without perceptual constraints, then post-trained for imperceptibility and multiple watermarks. Experiments show that WAM is competitive with state-of-the art methods in terms of imperceptibility and robustness, especially against inpainting and splicing, even on high-resolution images. Moreover, it offers new capabilities: WAM can locate watermarked areas in spliced images and extract distinct 32-bit messages with less than 1 bit error from multiple small regions - no larger than 10% of the image surface - even for small $256\times 256$ images.