 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Seal: Open and Efficient Video Watermarking
Dec 12, 2024



The proliferation of AI-generated content and sophisticated video editing tools has made it both important and challenging to moderate digital platforms. Video watermarking addresses these challenges by embedding imperceptible signals into videos, allowing for identification. However, the rare open tools and methods often fall short on efficiency, robustness, and flexibility. To reduce these gaps, this paper introduces Video Seal, a comprehensive framework for neural video watermarking and a competitive open-sourced model. Our approach jointly trains an embedder and an extractor, while ensuring the watermark robustness by applying transformations in-between, e.g., video codecs. This training is multistage and includes image pre-training, hybrid post-training and extractor fine-tuning. We also introduce temporal watermark propagation, a technique to convert any image watermarking model to an efficient video watermarking model without the need to watermark every high-resolution frame. We present experimental results demonstrating the effectiveness of the approach in terms of speed, imperceptibility, and robustness. Video Seal achieves higher robustness compared to strong baselines especially under challenging distortions combining geometric transformations and video compression. Additionally, we provide new insights such as the impact of video compression during training, and how to compare methods operating on different payloads. Contributions in this work - including the codebase, models, and a public demo - are open-sourced under permissive licenses to foster further research and development in the field.
DeDrift: Robust Similarity Search under Content Drift
Aug 05, 2023

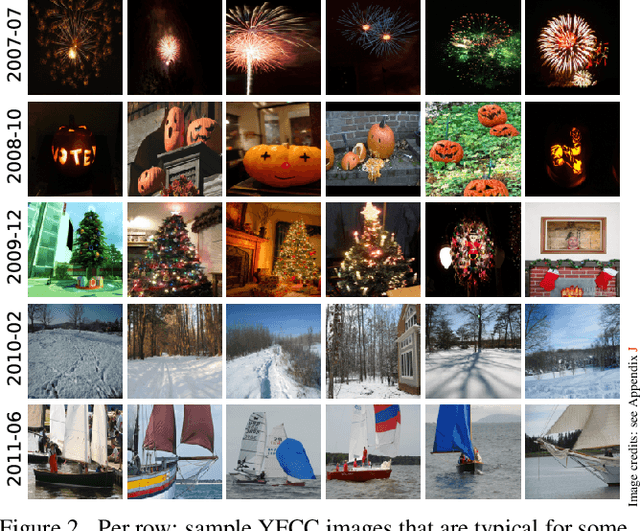

The statistical distribution of content uploaded and searched on media sharing sites changes over time due to seasonal, sociological and technical factors. We investigate the impact of this "content drift" for large-scale similarity search tools, based on nearest neighbor search in embedding space. Unless a costly index reconstruction is performed frequently, content drift degrades the search accuracy and efficiency. The degradation is especially severe since, in general, both the query and database distributions change. We introduce and analyze real-world image and video datasets for which temporal information is available over a long time period. Based on the learnings, we devise DeDrift, a method that updates embedding quantizers to continuously adapt large-scale indexing structures on-the-fly. DeDrift almost eliminates the accuracy degradation due to the query and database content drift while being up to 100x faster than a full index reconstruction.
Similarity Search for Efficient Active Learning and Search of Rare Concepts
Jun 30, 2020
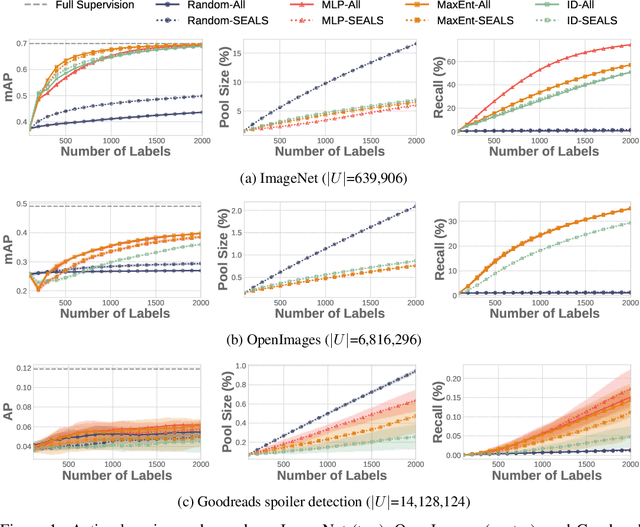

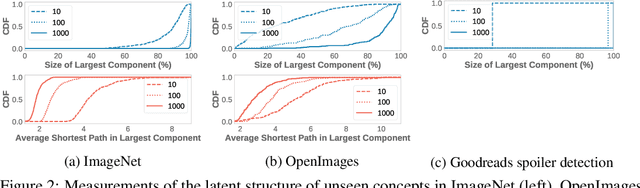
Many active learning and search approaches are intractable for industrial settings with billions of unlabeled examples. Existing approaches, such as uncertainty sampling or information density, search globally for the optimal examples to label, scaling linearly or even quadratically with the unlabeled data. However, in practice, data is often heavily skewed; only a small fraction of collected data will be relevant for a given learning task. For example, when identifying rare classes, detecting malicious content, or debugging model performance, the ratio of positive to negative examples can be 1 to 1,000 or more. In this work, we exploit this skew in large training datasets to reduce the number of unlabeled examples considered in each selection round by only looking at the nearest neighbors to the labeled examples. Empirically, we observe that learned representations effectively cluster unseen concepts, making active learning very effective and substantially reducing the number of viable unlabeled examples. We evaluate several active learning and search techniques in this setting on three large-scale datasets: ImageNet, Goodreads spoiler detection, and OpenImages. For rare classes, active learning methods need as little as 0.31% of the labeled data to match the average precision of full supervision. By limiting active learning methods to only consider the immediate neighbors of the labeled data as candidates for labeling, we need only process as little as 1% of the unlabeled data while achieving similar reductions in labeling costs as the traditional global approach. This process of expanding the candidate pool with the nearest neighbors of the labeled set can be done efficiently and reduces the computational complexity of selection by orders of magnitude.
NoiseRank: Unsupervised Label Noise Reduction with Dependence Models
Mar 15, 2020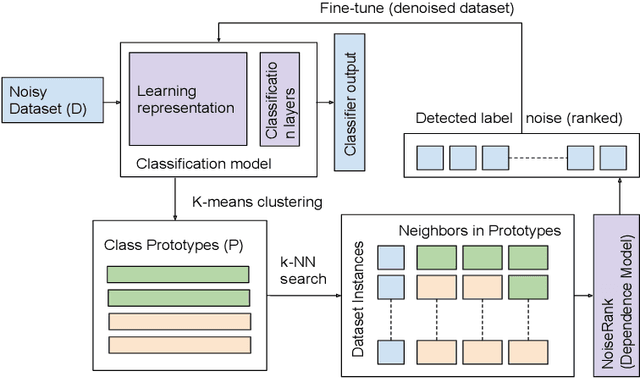

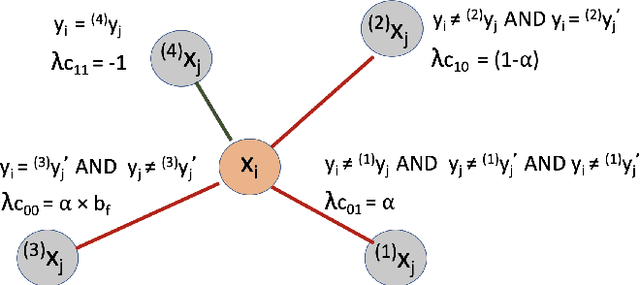
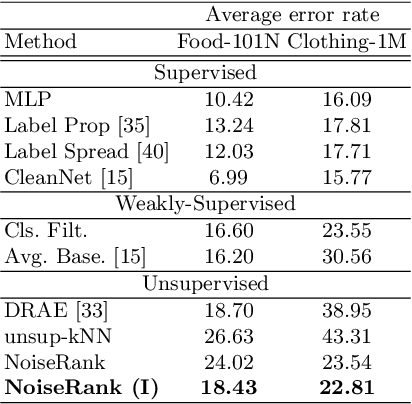
Label noise is increasingly prevalent in datasets acquired from noisy channels. Existing approaches that detect and remove label noise generally rely on some form of supervision, which is not scalable and error-prone. In this paper, we propose NoiseRank, for unsupervised label noise reduction using Markov Random Fields (MRF). We construct a dependence model to estimate the posterior probability of an instance being incorrectly labeled given the dataset, and rank instances based on their estimated probabilities. Our method 1) Does not require supervision from ground-truth labels, or priors on label or noise distribution. 2) It is interpretable by design, enabling transparency in label noise removal. 3) It is agnostic to classifier architecture/optimization framework and content modality. These advantages enable wide applicability in real noise settings, unlike prior works constrained by one or more conditions. NoiseRank improves state-of-the-art classification on Food101-N (~20% noise), and is effective on high noise Clothing-1M (~40% noise).
Billion-scale semi-supervised learning for image classification
May 02, 2019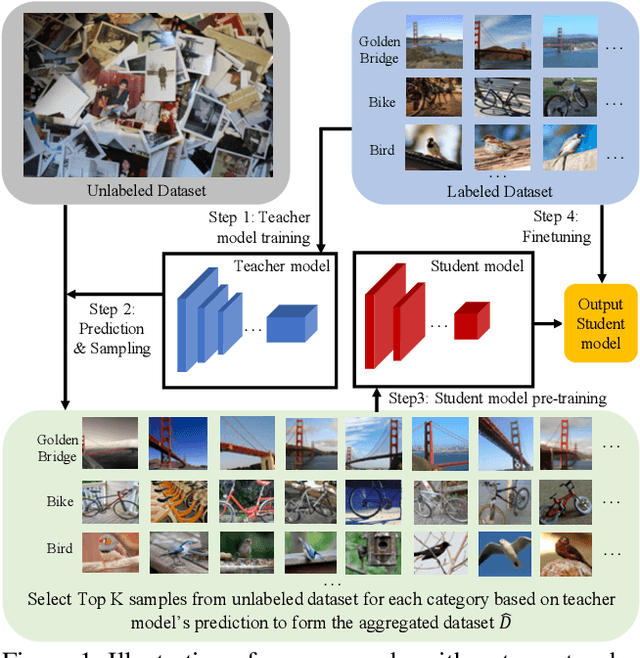

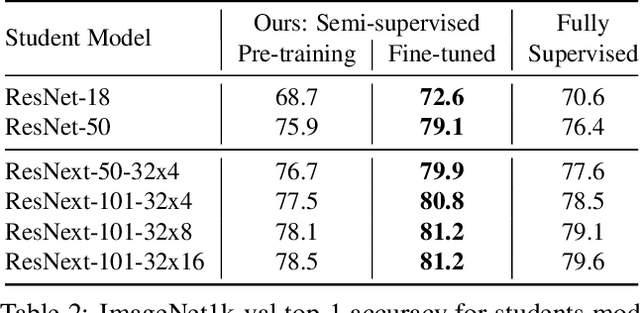
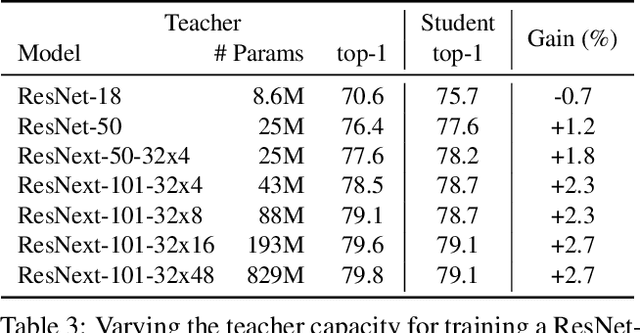
This paper presents a study of semi-supervised learning with large convolutional networks. We propose a pipeline, based on a teacher/student paradigm, that leverages a large collection of unlabelled images (up to 1 billion). Our main goal is to improve the performance for a given target architecture, like ResNet-50 or ResNext. We provide an extensive analysis of the success factors of our approach, which leads us to formulate some recommendations to produce high-accuracy models for image classification with semi-supervised learning. As a result, our approach brings important gains to standard architectures for image, video and fine-grained classification. For instance, by leveraging one billion unlabelled images, our learned vanilla ResNet-50 achieves 81.2% top-1 accuracy on the ImageNet benchmark.