 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning-Free Personalized Alignment via Trial-Error-Explain In-Context Learning
Feb 13, 2025Language models are aligned to the collective voice of many, resulting in generic outputs that do not align with specific users' styles. In this work, we present Trial-Error-Explain In-Context Learning (TICL), a tuning-free method that personalizes language models for text generation tasks with fewer than 10 examples per user. TICL iteratively expands an in-context learning prompt via a trial-error-explain process, adding model-generated negative samples and explanations that provide fine-grained guidance towards a specific user's style. TICL achieves favorable win rates on pairwise comparisons with LLM-as-a-judge up to 91.5% against the previous state-of-the-art and outperforms competitive tuning-free baselines for personalized alignment tasks of writing emails, essays and news articles. Both lexical and qualitative analyses show that the negative samples and explanations enable language models to learn stylistic context more effectively and overcome the bias towards structural and formal phrases observed in their zero-shot outputs. By front-loading inference compute to create a user-specific in-context learning prompt that does not require extra generation steps at test time, TICL presents a novel yet simple approach for personalized alignment.
Construction of Large-Scale Misinformation Labeled Datasets from Social Media Discourse using Label Refinement
Feb 24, 2022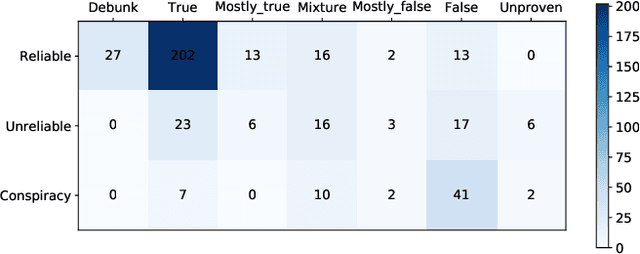

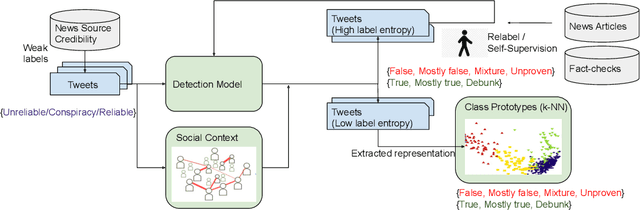

Malicious accounts spreading misinformation has led to widespread false and misleading narratives in recent times, especially during the COVID-19 pandemic, and social media platforms struggle to eliminate these contents rapidly. This is because adapting to new domains requires human intensive fact-checking that is slow and difficult to scale. To address this challenge, we propose to leverage news-source credibility labels as weak labels for social media posts and propose model-guided refinement of labels to construct large-scale, diverse misinformation labeled datasets in new domains. The weak labels can be inaccurate at the article or social media post level where the stance of the user does not align with the news source or article credibility. We propose a framework to use a detection model self-trained on the initial weak labels with uncertainty sampling based on entropy in predictions of the model to identify potentially inaccurate labels and correct for them using self-supervision or relabeling. The framework will incorporate social context of the post in terms of the community of its associated user for surfacing inaccurate labels towards building a large-scale dataset with minimum human effort. To provide labeled datasets with distinction of misleading narratives where information might be missing significant context or has inaccurate ancillary details, the proposed framework will use the few labeled samples as class prototypes to separate high confidence samples into false, unproven, mixture, mostly false, mostly true, true, and debunk information. The approach is demonstrated for providing a large-scale misinformation dataset on COVID-19 vaccines.
VigDet: Knowledge Informed Neural Temporal Point Process for Coordination Detection on Social Media
Oct 28, 2021

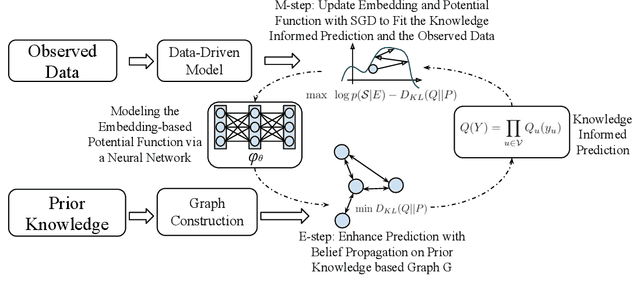
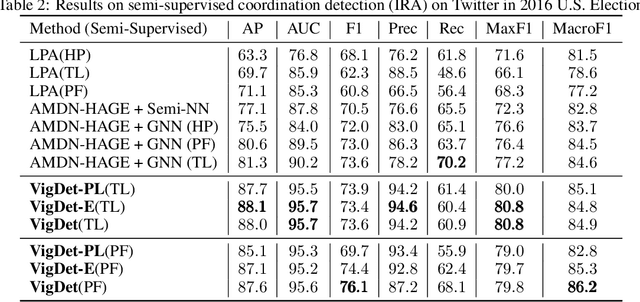
Recent years have witnessed an increasing use of coordinated accounts on social media, operated by misinformation campaigns to influence public opinion and manipulate social outcomes. Consequently, there is an urgent need to develop an effective methodology for coordinated group detection to combat the misinformation on social media. However, existing works suffer from various drawbacks, such as, either limited performance due to extreme reliance on predefined signatures of coordination, or instead an inability to address the natural sparsity of account activities on social media with useful prior domain knowledge. Therefore, in this paper, we propose a coordination detection framework incorporating neural temporal point process with prior knowledge such as temporal logic or pre-defined filtering functions. Specifically, when modeling the observed data from social media with neural temporal point process, we jointly learn a Gibbs-like distribution of group assignment based on how consistent an assignment is to (1) the account embedding space and (2) the prior knowledge. To address the challenge that the distribution is hard to be efficiently computed and sampled from, we design a theoretically guaranteed variational inference approach to learn a mean-field approximation for it. Experimental results on a real-world dataset show the effectiveness of our proposed method compared to the SOTA model in both unsupervised and semi-supervised settings. We further apply our model on a COVID-19 Vaccine Tweets dataset. The detection result suggests the presence of suspicious coordinated efforts on spreading misinformation about COVID-19 vaccines.
* Accepted by NeurIPS 2021. 17 pages, 5 figures
Characterizing Online Engagement with Disinformation and Conspiracies in the 2020 U.S. Presidential Election
Jul 17, 2021


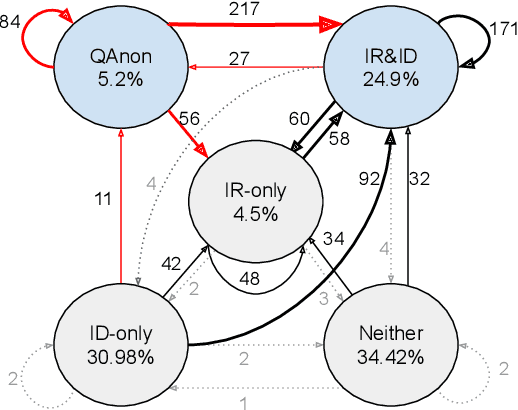
Identifying and characterizing disinformation in political discourse on social media is critical to ensure the integrity of elections and democratic processes around the world. Persistent manipulation of social media has resulted in increased concerns regarding the 2020 U.S. Presidential Election, due to its potential to influence individual opinions and social dynamics. In this work, we focus on the identification of distorted facts, in the form of unreliable and conspiratorial narratives in election-related tweets, to characterize discourse manipulation prior to the election. We apply a detection model to separate factual from unreliable (or conspiratorial) claims analyzing a dataset of 242 million election-related tweets. The identified claims are used to investigate targeted topics of disinformation, and conspiracy groups, most notably the far-right QAnon conspiracy group. Further, we characterize account engagements with unreliable and conspiracy tweets, and with the QAnon conspiracy group, by political leaning and tweet types. Finally, using a regression discontinuity design, we investigate whether Twitter's actions to curb QAnon activity on the platform were effective, and how QAnon accounts adapt to Twitter's restrictions.
* Accepted at ICWSM'22
COVID-19 Vaccines: Characterizing Misinformation Campaigns and Vaccine Hesitancy on Twitter
Jun 15, 2021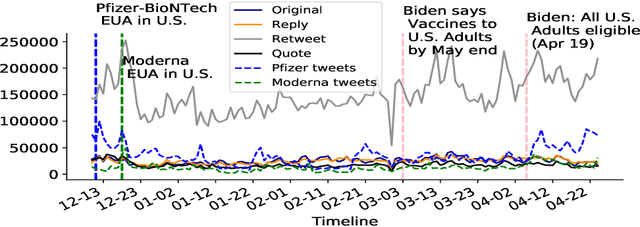
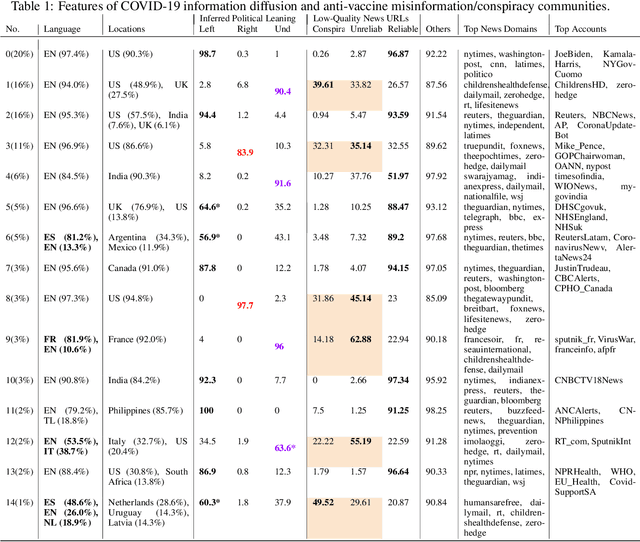
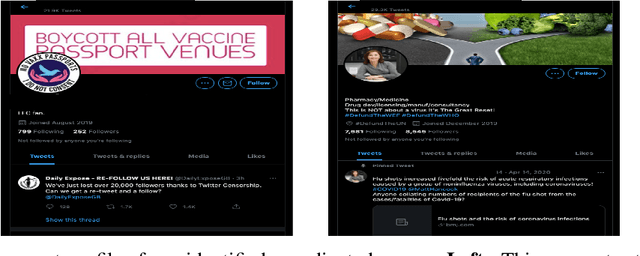
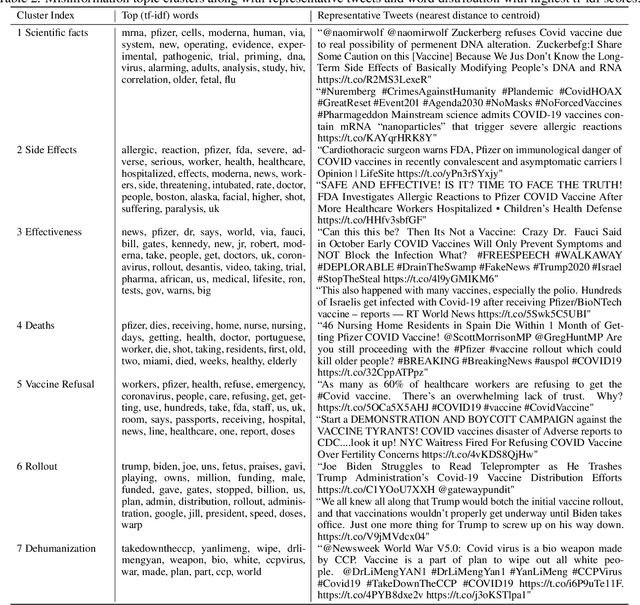
Vaccine hesitancy and misinformation on social media has increased concerns about COVID-19 vaccine uptake required to achieve herd immunity and overcome the pandemic. However anti-science and political misinformation and conspiracies have been rampant throughout the pandemic. For COVID-19 vaccines, we investigate misinformation and conspiracy campaigns and their characteristic behaviours. We identify whether coordinated efforts are used to promote misinformation in vaccine related discussions, and find accounts coordinately promoting a `Great Reset' conspiracy group promoting vaccine related misinformation and strong anti-vaccine and anti-social messages such as boycott vaccine passports, no lock-downs and masks. We characterize other misinformation communities from the information diffusion structure, and study the large anti-vaccine misinformation community and smaller anti-vaccine communities, including a far-right anti-vaccine conspiracy group. In comparison with the mainstream and health news, left-leaning group, which are more pro-vaccine, the right-leaning group is influenced more by the anti-vaccine and far-right misinformation/conspiracy communities. The misinformation communities are more vocal either specific to the vaccine discussion or political discussion, and we find other differences in the characteristic behaviours of different communities. Lastly, we investigate misinformation narratives and tactics of information distortion that can increase vaccine hesitancy, using topic modeling and comparison with reported vaccine side-effects (VAERS) finding rarer side-effects are more frequently discussed on social media.
Network Inference from a Mixture of Diffusion Models for Fake News Mitigation
Aug 08, 2020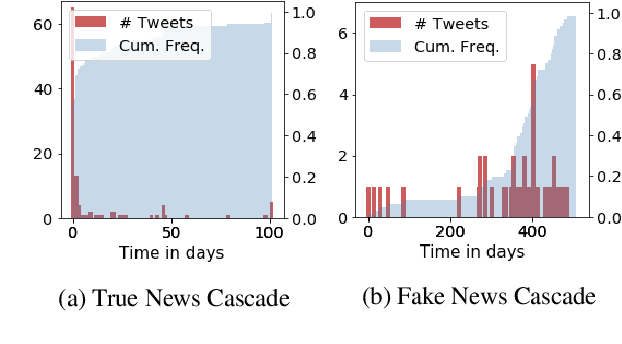
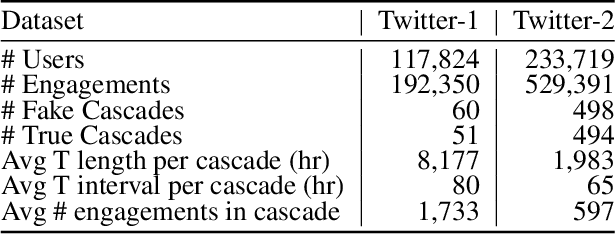
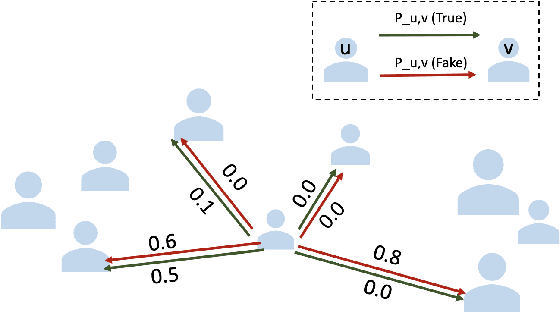
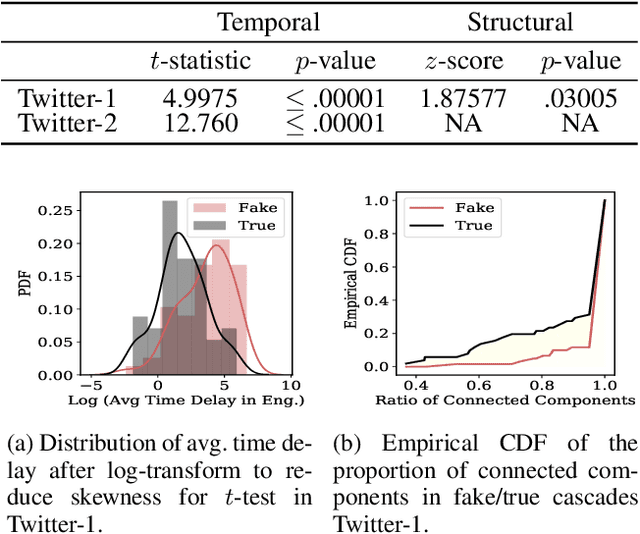
The dissemination of fake news intended to deceive people, influence public opinion and manipulate social outcomes, has become a pressing problem on social media. Moreover, information sharing on social media facilitates diffusion of viral information cascades. In this work, we focus on understanding and leveraging diffusion dynamics of false and legitimate contents in order to facilitate network interventions for fake news mitigation. We analyze real-world Twitter datasets comprising fake and true news cascades, to understand differences in diffusion dynamics and user behaviours with regards to fake and true contents. Based on the analysis, we model the diffusion as a mixture of Independent Cascade models (MIC) with parameters $\theta_T, \theta_F$ over the social network graph; and derive unsupervised inference techniques for parameter estimation of the diffusion mixture model from observed, unlabeled cascades. Users influential in the propagation of true and fake contents are identified using the inferred diffusion dynamics. Characteristics of the identified influential users reveal positive correlation between influential users identified for fake news and their relative appearance in fake news cascades. Identified influential users tend to be related to topics of more viral information cascades than less viral ones; and identified fake news influential users have relatively fewer counts of direct followers, compared to the true news influential users. Intervention analysis on nodes and edges demonstrates capacity of the inferred diffusion dynamics in supporting network interventions for mitigation.
Coronavirus on Social Media: Analyzing Misinformation in Twitter Conversations
Apr 21, 2020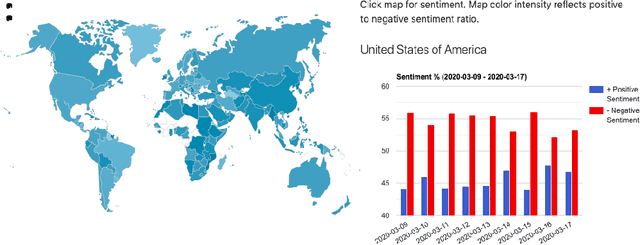
The ongoing Coronavirus Disease (COVID-19) pandemic highlights the interconnected-ness of our present-day globalized world. With social distancing policies in place, virtual communication has become an important source of (mis)information. As increasing number of people rely on social media platforms for news, identifying misinformation has emerged as a critical task in these unprecedented times. In addition to being malicious, the spread of such information poses a serious public health risk. To this end, we design a dashboard to track misinformation on popular social media news sharing platform - Twitter. The dashboard allows visibility into the social media discussions around Coronavirus and the quality of information shared on the platform, updated over time. We collect streaming data using the Twitter API from March 1, 2020 to date and identify false, misleading and clickbait contents from collected Tweets. We provide analysis of user accounts and misinformation spread across countries. In addition, we provide analysis of public sentiments on intervention policies such as "#socialdistancing" and "#workfromhome", and we track topics, and emerging hashtags and sentiments over countries. The dashboard maintains an evolving list of misinformation cascades, sentiments and emerging trends over time, accessible online at \url{https://usc-melady.github.io/COVID-19-Tweet-Analysis}.
NoiseRank: Unsupervised Label Noise Reduction with Dependence Models
Mar 15, 2020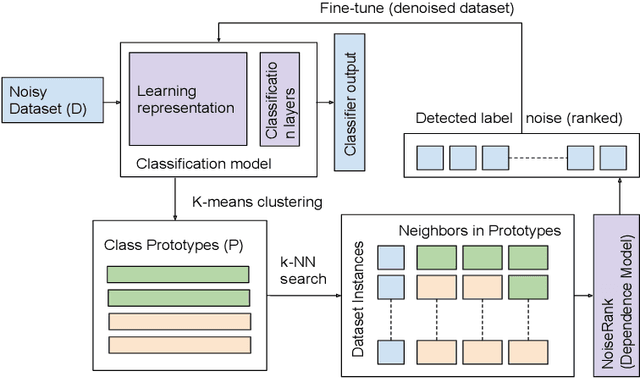

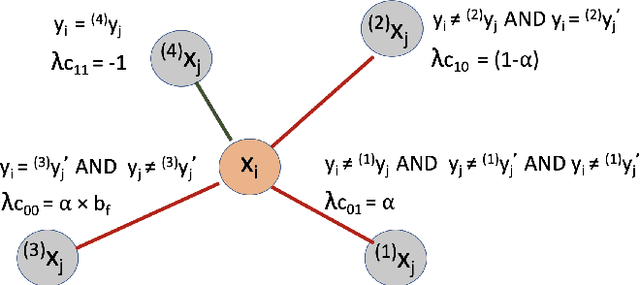
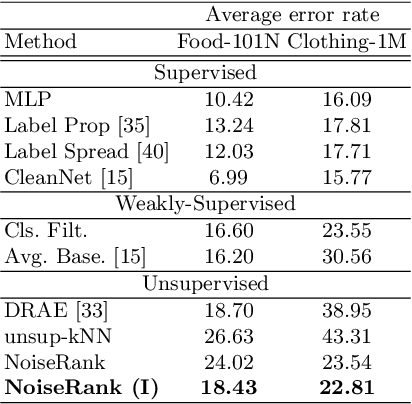
Label noise is increasingly prevalent in datasets acquired from noisy channels. Existing approaches that detect and remove label noise generally rely on some form of supervision, which is not scalable and error-prone. In this paper, we propose NoiseRank, for unsupervised label noise reduction using Markov Random Fields (MRF). We construct a dependence model to estimate the posterior probability of an instance being incorrectly labeled given the dataset, and rank instances based on their estimated probabilities. Our method 1) Does not require supervision from ground-truth labels, or priors on label or noise distribution. 2) It is interpretable by design, enabling transparency in label noise removal. 3) It is agnostic to classifier architecture/optimization framework and content modality. These advantages enable wide applicability in real noise settings, unlike prior works constrained by one or more conditions. NoiseRank improves state-of-the-art classification on Food101-N (~20% noise), and is effective on high noise Clothing-1M (~40% noise).
Combating Fake News: A Survey on Identification and Mitigation Techniques
Jan 18, 2019



The proliferation of fake news on social media has opened up new directions of research for timely identification and containment of fake news, and mitigation of its widespread impact on public opinion. While much of the earlier research was focused on identification of fake news based on its contents or by exploiting users' engagements with the news on social media, there has been a rising interest in proactive intervention strategies to counter the spread of misinformation and its impact on society. In this survey, we describe the modern-day problem of fake news and, in particular, highlight the technical challenges associated with it. We discuss existing methods and techniques applicable to both identification and mitigation, with a focus on the significant advances in each method and their advantages and limitations. In addition, research has often been limited by the quality of existing datasets and their specific application contexts. To alleviate this problem, we comprehensively compile and summarize characteristic features of available datasets. Furthermore, we outline new directions of research to facilitate future development of effective and interdisciplinary solutions.