 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoppelgänger's Watch: A Split Objective Approach to Large Language Models
Sep 09, 2024In this paper, we investigate the problem of "generation supervision" in large language models, and present a novel bicameral architecture to separate supervision signals from their core capability, helpfulness. Doppelg\"anger, a new module parallel to the underlying language model, supervises the generation of each token, and learns to concurrently predict the supervision score(s) of the sequences up to and including each token. In this work, we present the theoretical findings, and leave the report on experimental results to a forthcoming publication.
Best Practices for Data-Efficient Modeling in NLG:How to Train Production-Ready Neural Models with Less Data
Nov 08, 2020Natural language generation (NLG) is a critical component in conversational systems, owing to its role of formulating a correct and natural text response. Traditionally, NLG components have been deployed using template-based solutions. Although neural network solutions recently developed in the research community have been shown to provide several benefits, deployment of such model-based solutions has been challenging due to high latency, correctness issues, and high data needs. In this paper, we present approaches that have helped us deploy data-efficient neural solutions for NLG in conversational systems to production. We describe a family of sampling and modeling techniques to attain production quality with light-weight neural network models using only a fraction of the data that would be necessary otherwise, and show a thorough comparison between each. Our results show that domain complexity dictates the appropriate approach to achieve high data efficiency. Finally, we distill the lessons from our experimental findings into a list of best practices for production-level NLG model development, and present them in a brief runbook. Importantly, the end products of all of the techniques are small sequence-to-sequence models (2Mb) that we can reliably deploy in production.
NoiseRank: Unsupervised Label Noise Reduction with Dependence Models
Mar 15, 2020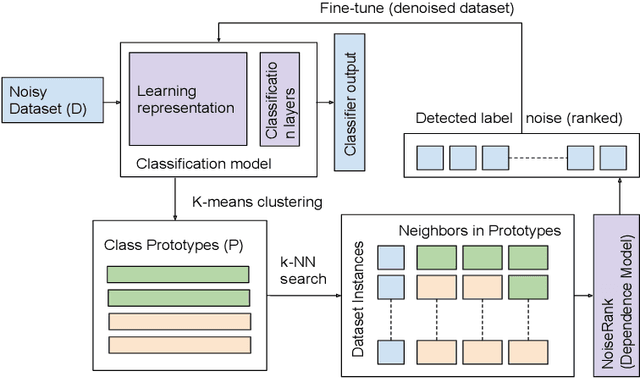

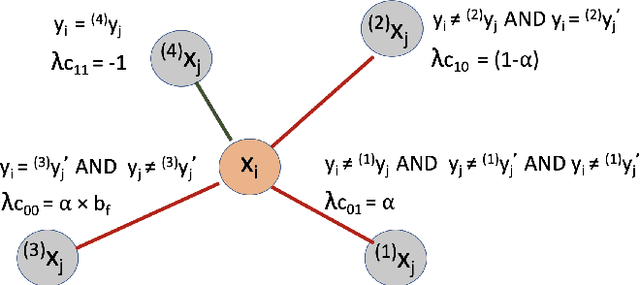
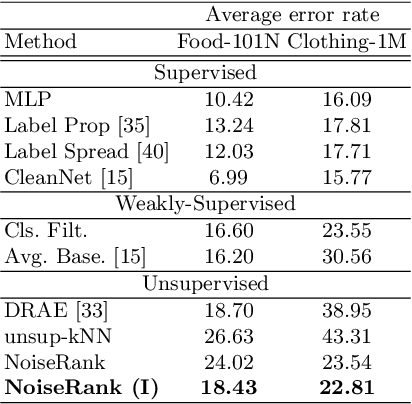
Label noise is increasingly prevalent in datasets acquired from noisy channels. Existing approaches that detect and remove label noise generally rely on some form of supervision, which is not scalable and error-prone. In this paper, we propose NoiseRank, for unsupervised label noise reduction using Markov Random Fields (MRF). We construct a dependence model to estimate the posterior probability of an instance being incorrectly labeled given the dataset, and rank instances based on their estimated probabilities. Our method 1) Does not require supervision from ground-truth labels, or priors on label or noise distribution. 2) It is interpretable by design, enabling transparency in label noise removal. 3) It is agnostic to classifier architecture/optimization framework and content modality. These advantages enable wide applicability in real noise settings, unlike prior works constrained by one or more conditions. NoiseRank improves state-of-the-art classification on Food101-N (~20% noise), and is effective on high noise Clothing-1M (~40% noise).
Unsupervised Supervised Learning II: Training Margin Based Classifiers without Labels
Jul 21, 2010
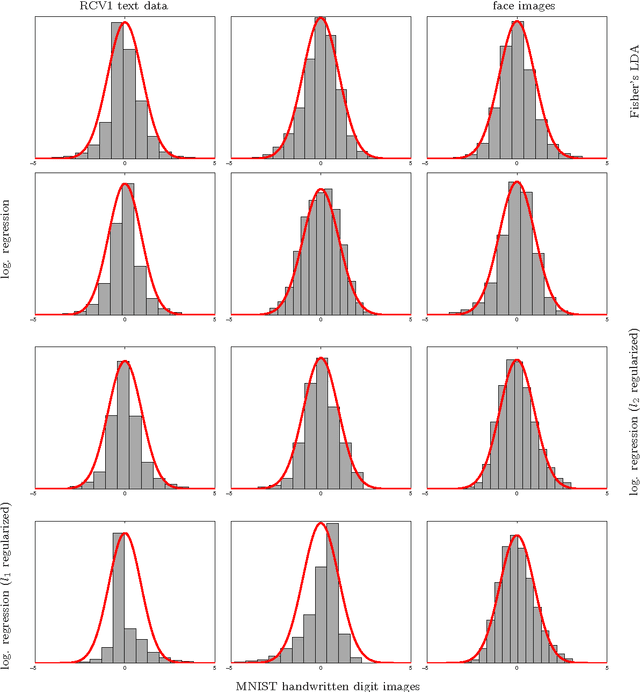

Many popular linear classifiers, such as logistic regression, boosting, or SVM, are trained by optimizing a margin-based risk function. Traditionally, these risk functions are computed based on a labeled dataset. We develop a novel technique for estimating such risks using only unlabeled data and the marginal label distribution. We prove that the proposed risk estimator is consistent on high-dimensional datasets and demonstrate it on synthetic and real-world data. In particular, we show how the estimate is used for evaluating classifiers in transfer learning, and for training classifiers with no labeled data whatsoever.