 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Sep 27, 2023



We present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module. To further strengthen the multimodal LLM's capabilities, we fine-tune the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. We conduct comprehensive empirical analysis comprising both human and automatic evaluations, and demonstrate state-of-the-art performance on various multimodal tasks.
Improving Opinion-based Question Answering Systems Through Label Error Detection and Overwrite
Jun 13, 2023Label error is a ubiquitous problem in annotated data. Large amounts of label error substantially degrades the quality of deep learning models. Existing methods to tackle the label error problem largely focus on the classification task, and either rely on task specific architecture or require non-trivial additional computations, which is undesirable or even unattainable for industry usage. In this paper, we propose LEDO: a model-agnostic and computationally efficient framework for Label Error Detection and Overwrite. LEDO is based on Monte Carlo Dropout combined with uncertainty metrics, and can be easily generalized to multiple tasks and data sets. Applying LEDO to an industry opinion-based question answering system demonstrates it is effective at improving accuracy in all the core models. Specifically, LEDO brings 1.1% MRR gain for the retrieval model, 1.5% PR AUC improvement for the machine reading comprehension model, and 0.9% rise in the Average Precision for the ranker, on top of the strong baselines with a large-scale social media dataset. Importantly, LEDO is computationally efficient compared to methods that require loss function change, and cost-effective as the resulting data can be used in the same continuous training pipeline for production. Further analysis shows that these gains come from an improved decision boundary after cleaning the label errors existed in the training data.
Text Generation with Speech Synthesis for ASR Data Augmentation
May 22, 2023
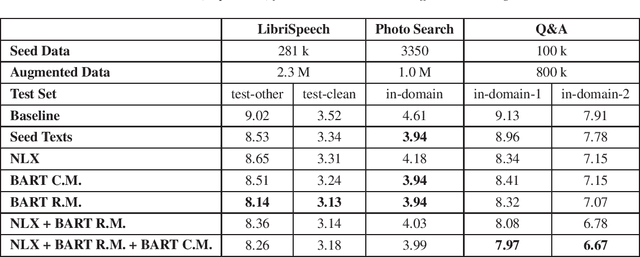
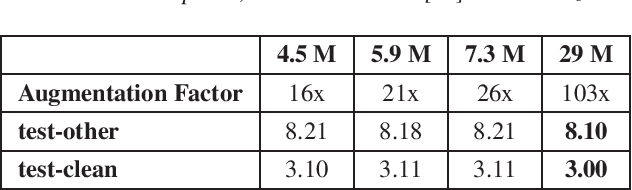
Aiming at reducing the reliance on expensive human annotations, data synthesis for Automatic Speech Recognition (ASR) has remained an active area of research. While prior work mainly focuses on synthetic speech generation for ASR data augmentation, its combination with text generation methods is considerably less explored. In this work, we explore text augmentation for ASR using large-scale pre-trained neural networks, and systematically compare those to traditional text augmentation methods. The generated synthetic texts are then converted to synthetic speech using a text-to-speech (TTS) system and added to the ASR training data. In experiments conducted on three datasets, we find that neural models achieve 9%-15% relative WER improvement and outperform traditional methods. We conclude that text augmentation, particularly through modern neural approaches, is a viable tool for improving the accuracy of ASR systems.
A Study on the Efficiency and Generalization of Light Hybrid Retrievers
Oct 04, 2022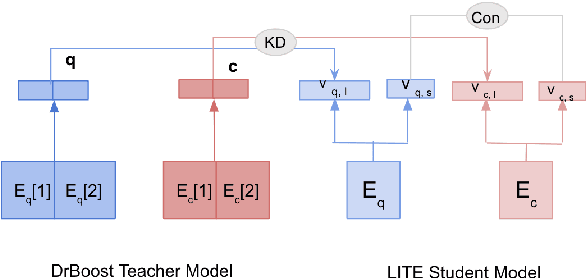
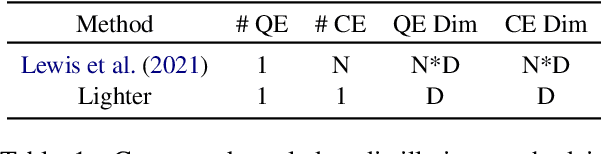
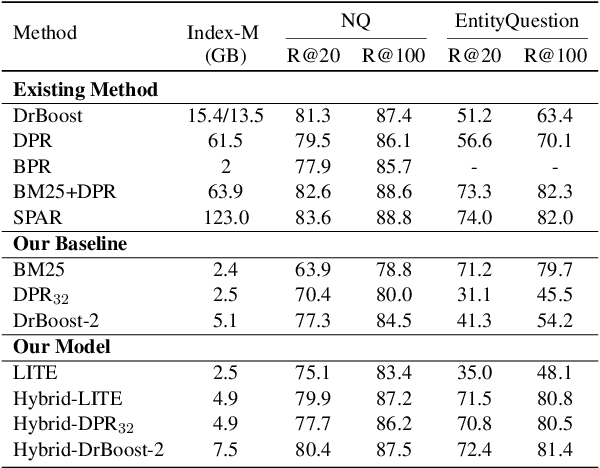
Existing hybrid retrievers which integrate sparse and dense retrievers, are indexing-heavy, limiting their applicability in real-world on-devices settings. We ask the question "Is it possible to reduce the indexing memory of hybrid retrievers without sacrificing performance?" Driven by this question, we leverage an indexing-efficient dense retriever (i.e. DrBoost) to obtain a light hybrid retriever. Moreover, to further reduce the memory, we introduce a lighter dense retriever (LITE) which is jointly trained on contrastive learning and knowledge distillation from DrBoost. Compared to previous heavy hybrid retrievers, our Hybrid-LITE retriever saves 13 memory while maintaining 98.0 performance. In addition, we study the generalization of light hybrid retrievers along two dimensions, out-of-domain (OOD) generalization and robustness against adversarial attacks. We evaluate models on two existing OOD benchmarks and create six adversarial attack sets for robustness evaluation. Experiments show that our light hybrid retrievers achieve better robustness performance than both sparse and dense retrievers. Nevertheless there is a large room to improve the robustness of retrievers, and our datasets can aid future research.
Audience Creation for Consumables -- Simple and Scalable Precision Merchandising for a Growing Marketplace
Nov 17, 2020
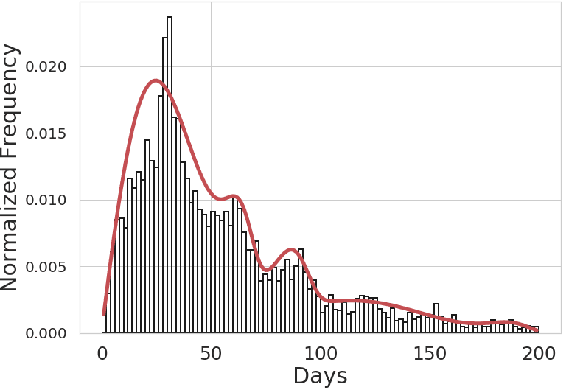
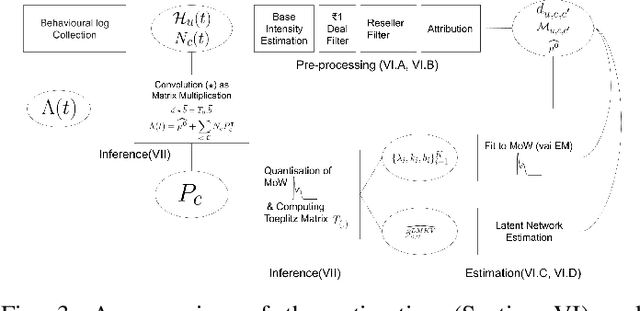
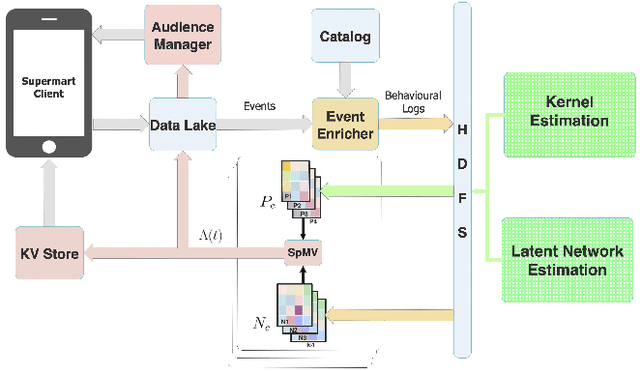
Consumable categories, such as grocery and fast-moving consumer goods, are quintessential to the growth of e-commerce marketplaces in developing countries. In this work, we present the design and implementation of a precision merchandising system, which creates audience sets from over 10 million consumers and is deployed at Flipkart Supermart, one of the largest online grocery stores in India. We employ temporal point process to model the latent periodicity and mutual-excitation in the purchase dynamics of consumables. Further, we develop a likelihood-free estimation procedure that is robust against data sparsity, censure and noise typical of a growing marketplace. Lastly, we scale the inference by quantizing the triggering kernels and exploiting sparse matrix-vector multiplication primitive available on a commercial distributed linear algebra backend. In operation spanning more than a year, we have witnessed a consistent increase in click-through rate in the range of 25-70% for banner-based merchandising in the storefront, and in the range of 12-26% for push notification-based campaigns.
Best Practices for Data-Efficient Modeling in NLG:How to Train Production-Ready Neural Models with Less Data
Nov 08, 2020Natural language generation (NLG) is a critical component in conversational systems, owing to its role of formulating a correct and natural text response. Traditionally, NLG components have been deployed using template-based solutions. Although neural network solutions recently developed in the research community have been shown to provide several benefits, deployment of such model-based solutions has been challenging due to high latency, correctness issues, and high data needs. In this paper, we present approaches that have helped us deploy data-efficient neural solutions for NLG in conversational systems to production. We describe a family of sampling and modeling techniques to attain production quality with light-weight neural network models using only a fraction of the data that would be necessary otherwise, and show a thorough comparison between each. Our results show that domain complexity dictates the appropriate approach to achieve high data efficiency. Finally, we distill the lessons from our experimental findings into a list of best practices for production-level NLG model development, and present them in a brief runbook. Importantly, the end products of all of the techniques are small sequence-to-sequence models (2Mb) that we can reliably deploy in production.