 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Generation with Speech Synthesis for ASR Data Augmentation
May 22, 2023
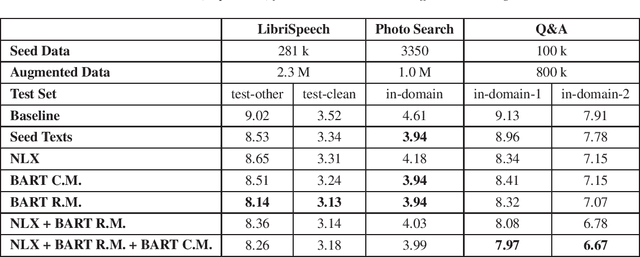
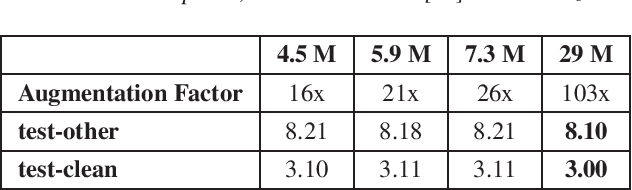
Aiming at reducing the reliance on expensive human annotations, data synthesis for Automatic Speech Recognition (ASR) has remained an active area of research. While prior work mainly focuses on synthetic speech generation for ASR data augmentation, its combination with text generation methods is considerably less explored. In this work, we explore text augmentation for ASR using large-scale pre-trained neural networks, and systematically compare those to traditional text augmentation methods. The generated synthetic texts are then converted to synthetic speech using a text-to-speech (TTS) system and added to the ASR training data. In experiments conducted on three datasets, we find that neural models achieve 9%-15% relative WER improvement and outperform traditional methods. We conclude that text augmentation, particularly through modern neural approaches, is a viable tool for improving the accuracy of ASR systems.
EAC-Net: A Region-based Deep Enhancing and Cropping Approach for Facial Action Unit Detection
Feb 09, 2017
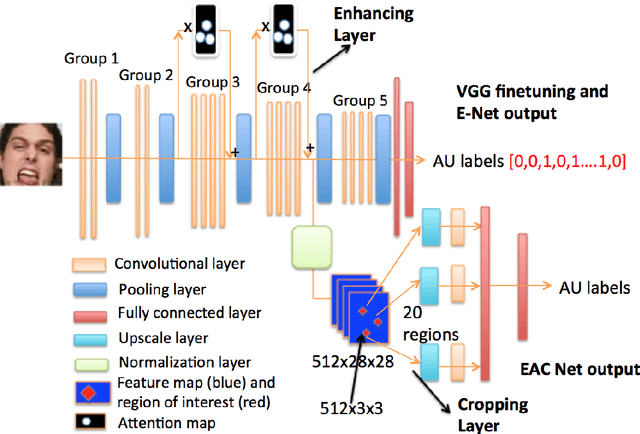
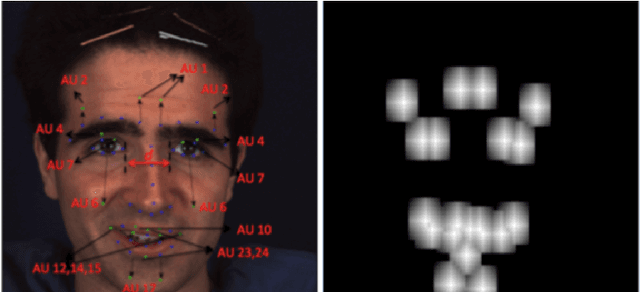
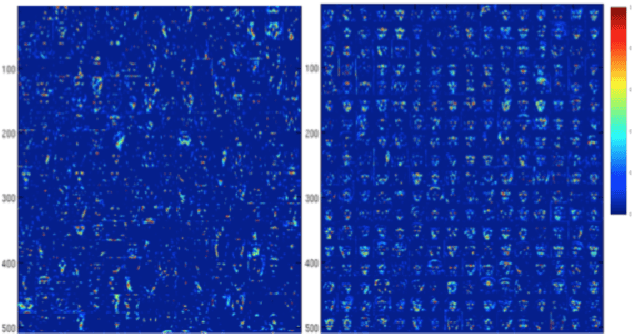
In this paper, we propose a deep learning based approach for facial action unit detection by enhancing and cropping the regions of interest. The approach is implemented by adding two novel nets (layers): the enhancing layers and the cropping layers, to a pretrained CNN model. For the enhancing layers, we designed an attention map based on facial landmark features and applied it to a pretrained neural network to conduct enhanced learning (The E-Net). For the cropping layers, we crop facial regions around the detected landmarks and design convolutional layers to learn deeper features for each facial region (C-Net). We then fuse the E-Net and the C-Net to obtain our Enhancing and Cropping (EAC) Net, which can learn both feature enhancing and region cropping functions. Our approach shows significant improvement in performance compared to the state-of-the-art methods applied to BP4D and DISFA AU datasets.
A Recursive Framework for Expression Recognition: From Web Images to Deep Models to Game Dataset
Aug 04, 2016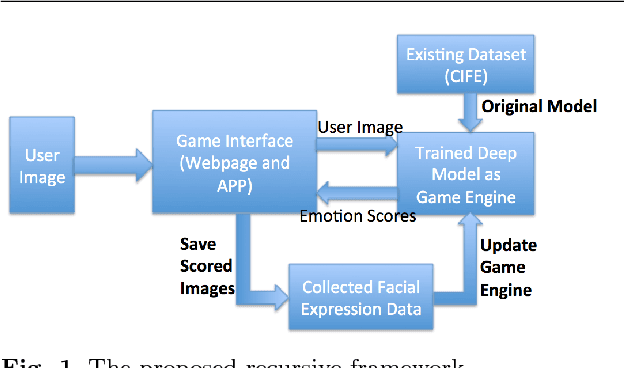

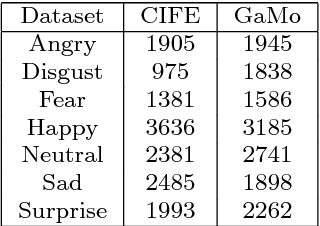

In this paper, we propose a recursive framework to recognize facial expressions from images in real scenes. Unlike traditional approaches that typically focus on developing and refining algorithms for improving recognition performance on an existing dataset, we integrate three important components in a recursive manner: facial dataset generation, facial expression recognition model building, and interactive interfaces for testing and new data collection. To start with, we first create a candid-images-for-facial-expression (CIFE) dataset. We then apply a convolutional neural network (CNN) to CIFE and build a CNN model for web image expression classification. In order to increase the expression recognition accuracy, we also fine-tune the CNN model and thus obtain a better CNN facial expression recognition model. Based on the fine-tuned CNN model, we design a facial expression game engine and collect a new and more balanced dataset, GaMo. The images of this dataset are collected from the different expressions our game users make when playing the game. Finally, we evaluate the GaMo and CIFE datasets and show that our recursive framework can help build a better facial expression model for dealing with real scene facial expression tasks.
Towards an "In-the-Wild" Emotion Dataset Using a Game-based Framework
Jul 10, 2016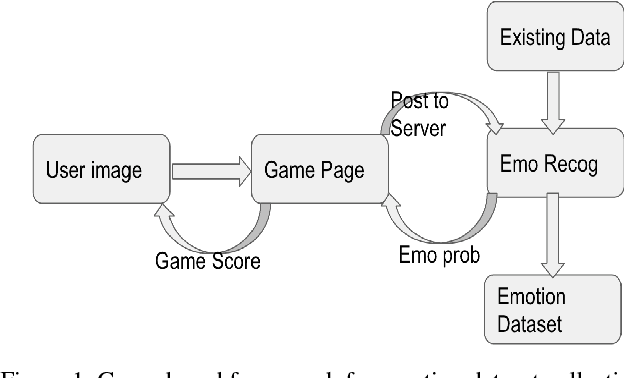
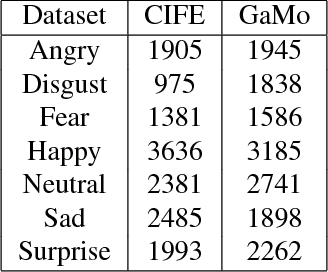
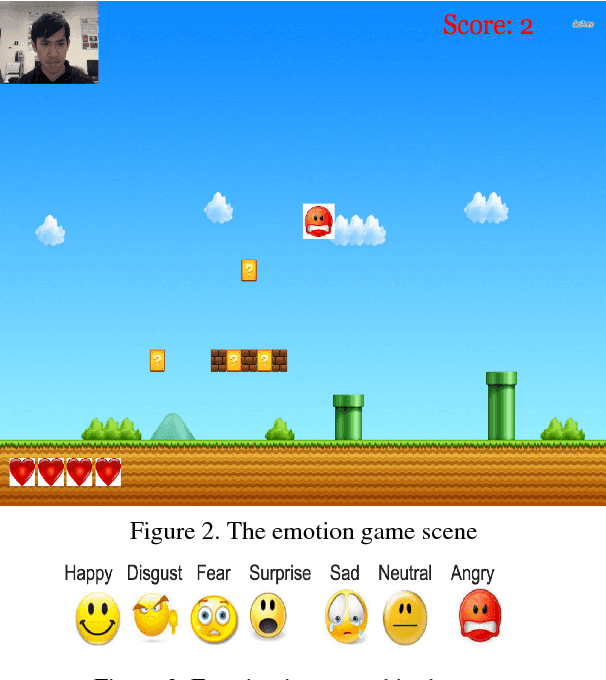

In order to create an "in-the-wild" dataset of facial emotions with large number of balanced samples, this paper proposes a game-based data collection framework. The framework mainly include three components: a game engine, a game interface, and a data collection and evaluation module. We use a deep learning approach to build an emotion classifier as the game engine. Then a emotion web game to allow gamers to enjoy the games, while the data collection module obtains automatically-labelled emotion images. Using our game, we have collected more than 15,000 images within a month of the test run and built an emotion dataset "GaMo". To evaluate the dataset, we compared the performance of two deep learning models trained on both GaMo and CIFE. The results of our experiments show that because of being large and balanced, GaMo can be used to build a more robust emotion detector than the emotion detector trained on CIFE, which was used in the game engine to collect the face images.