 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient Guidance Enables Test Time Control
Oct 02, 2025We introduce Policy Gradient Guidance (PGG), a simple extension of classifier-free guidance from diffusion models to classical policy gradient methods. PGG augments the policy gradient with an unconditional branch and interpolates conditional and unconditional branches, yielding a test-time control knob that modulates behavior without retraining. We provide a theoretical derivation showing that the additional normalization term vanishes under advantage estimation, leading to a clean guided policy gradient update. Empirically, we evaluate PGG on discrete and continuous control benchmarks. We find that conditioning dropout-central to diffusion guidance-offers gains in simple discrete tasks and low sample regimes, but dropout destabilizes continuous control. Training with modestly larger guidance ($\gamma>1$) consistently improves stability, sample efficiency, and controllability. Our results show that guidance, previously confined to diffusion policies, can be adapted to standard on-policy methods, opening new directions for controllable online reinforcement learning.
Learning to Reason Across Parallel Samples for LLM Reasoning
Jun 10, 2025Scaling test-time compute brings substantial performance gains for large language models (LLMs). By sampling multiple answers and heuristically aggregate their answers (e.g., either through majority voting or using verifiers to rank the answers), one can achieve consistent performance gains in math domains. In this paper, we propose a new way to leverage such multiple sample set. We train a compact LLM, called Sample Set Aggregator (SSA), that takes a concatenated sequence of multiple samples and output the final answer, optimizing it for the answer accuracy with reinforcement learning. Experiments on multiple reasoning datasets show that SSA outperforms other test-time scaling methods such as reward model-based re-ranking. Our approach also shows a promising generalization ability, across sample set sizes, base model families and scales, and tasks. By separating LLMs to generate answers and LLMs to analyze and aggregate sampled answers, our approach can work with the outputs from premier black box models easily and efficiently.
Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models
Mar 21, 2025Vision-Language Models (VLMs) excel at identifying and describing objects but struggle with spatial reasoning such as accurately understanding the relative positions of objects. Inspired by the dual-pathway (ventral-dorsal) model of human vision, we investigate why VLMs fail spatial tasks despite strong object recognition capabilities. Our interpretability-driven analysis reveals a critical underlying cause: vision embeddings in VLMs are treated primarily as semantic ``bag-of-tokens," overshadowing subtle yet crucial positional cues due to their disproportionately large embedding norms. We validate this insight through extensive diagnostic experiments, demonstrating minimal performance impact when token orders or fine-grained spatial details are removed. Guided by these findings, we propose simple, interpretable interventions, including normalizing vision embedding norms and extracting mid-layer spatially rich features, to restore spatial awareness. Empirical results on both our synthetic data and standard benchmarks demonstrate improved spatial reasoning capabilities, highlighting the value of interpretability-informed design choices. Our study not only uncovers fundamental limitations in current VLM architectures but also provides actionable insights for enhancing structured perception of visual scenes.
VerifierQ: Enhancing LLM Test Time Compute with Q-Learning-based Verifiers
Oct 10, 2024
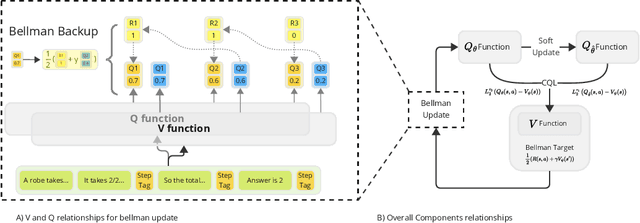
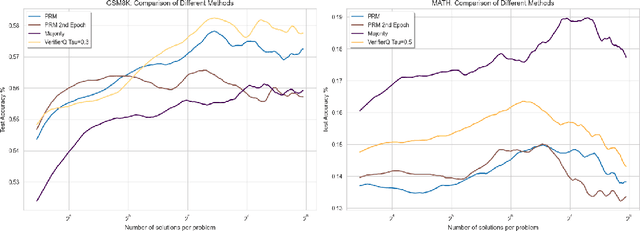
Recent advancements in test time compute, particularly through the use of verifier models, have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). This generator-verifier approach closely resembles the actor-critic framework in reinforcement learning (RL). However, current verifier models in LLMs often rely on supervised fine-tuning without temporal difference learning such as Q-learning. This paper introduces VerifierQ, a novel approach that integrates Offline Q-learning into LLM verifier models. We address three key challenges in applying Q-learning to LLMs: (1) handling utterance-level Markov Decision Processes (MDPs), (2) managing large action spaces, and (3) mitigating overestimation bias. VerifierQ introduces a modified Bellman update for bounded Q-values, incorporates Implicit Q-learning (IQL) for efficient action space management, and integrates a novel Conservative Q-learning (CQL) formulation for balanced Q-value estimation. Our method enables parallel Q-value computation and improving training efficiency. While recent work has explored RL techniques like MCTS for generators, VerifierQ is among the first to investigate the verifier (critic) aspect in LLMs through Q-learning. This integration of RL principles into verifier models complements existing advancements in generator techniques, potentially enabling more robust and adaptive reasoning in LLMs. Experimental results on mathematical reasoning tasks demonstrate VerifierQ's superior performance compared to traditional supervised fine-tuning approaches, with improvements in efficiency, accuracy and robustness. By enhancing the synergy between generation and evaluation capabilities, VerifierQ contributes to the ongoing evolution of AI systems in addressing complex cognitive tasks across various domains.
GMC: A General Framework of Multi-stage Context Learning and Utilization for Visual Detection Tasks
Jul 08, 2024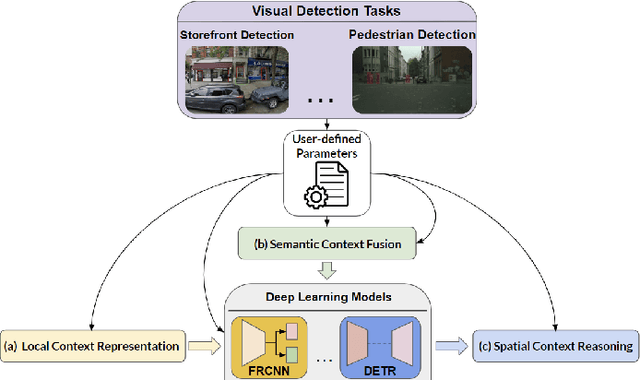
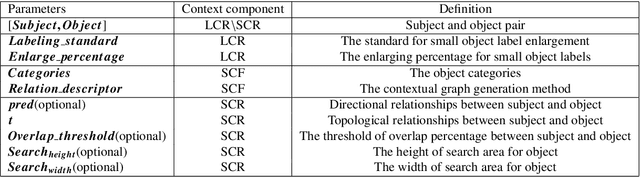
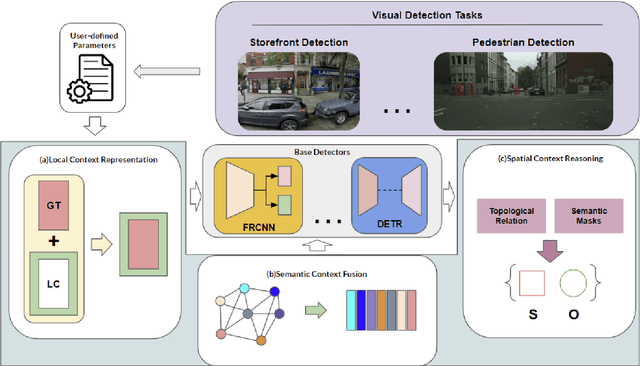
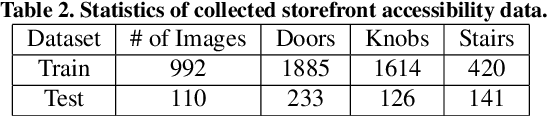
Various contextual information has been employed by many approaches for visual detection tasks. However, most of the existing approaches only focus on specific context for specific tasks. In this paper, GMC, a general framework is proposed for multistage context learning and utilization, with various deep network architectures for various visual detection tasks. The GMC framework encompasses three stages: preprocessing, training, and post-processing. In the preprocessing stage, the representation of local context is enhanced by utilizing commonly used labeling standards. During the training stage, semantic context information is fused with visual information, leveraging prior knowledge from the training dataset to capture semantic relationships. In the post-processing stage, general topological relations and semantic masks for stuff are incorporated to enable spatial context reasoning between objects. The proposed framework provides a comprehensive and adaptable solution for context learning and utilization in visual detection scenarios. The framework offers flexibility with user-defined configurations and provide adaptability to diverse network architectures and visual detection tasks, offering an automated and streamlined solution that minimizes user effort and inference time in context learning and reasoning. Experimental results on the visual detection tasks, for storefront object detection, pedestrian detection and COCO object detection, demonstrate that our framework outperforms previous state-of-the-art detectors and transformer architectures. The experiments also demonstrate that three contextual learning components can not only be applied individually and in combination, but can also be applied to various network architectures, and its flexibility and effectiveness in various detection scenarios.
Segment Anything Model for Pedestrian Infrastructure Inventory: Assessing Zero-Shot Segmentation on Multi-Mode Geospatial Data
Oct 24, 2023



In this paper, a Segment Anything Model (SAM)-based pedestrian infrastructure segmentation workflow is designed and optimized, which is capable of efficiently processing multi-sourced geospatial data including LiDAR data and satellite imagery data. We used an expanded definition of pedestrian infrastructure inventory which goes beyond the traditional transportation elements to include street furniture objects often omitted from the traditional definition. Our contributions lie in producing the necessary knowledge to answer the following two questions. First, which data representation can facilitate zero-shot segmentation of infrastructure objects with SAM? Second, how well does the SAM-based method perform on segmenting pedestrian infrastructure objects? Our findings indicate that street view images generated from mobile LiDAR point cloud data, when paired along with satellite imagery data, can work efficiently with SAM to create a scalable pedestrian infrastructure inventory approach with immediate benefits to GIS professionals, city managers, transportation owners, and walkers, especially those with travel-limiting disabilities.
Robots in the Garden: Artificial Intelligence and Adaptive Landscapes
May 22, 2023This paper introduces ELUA, the Ecological Laboratory for Urban Agriculture, a collaboration among landscape architects, architects and computer scientists who specialize in artificial intelligence, robotics and computer vision. ELUA has two gantry robots, one indoors and the other outside on the rooftop of a 6-story campus building. Each robot can seed, water, weed, and prune in its garden. To support responsive landscape research, ELUA also includes sensor arrays, an AI-powered camera, and an extensive network infrastructure. This project demonstrates a way to integrate artificial intelligence into an evolving urban ecosystem, and encourages landscape architects to develop an adaptive design framework where design becomes a long-term engagement with the environment.
* 4 figures, 9 pages
Context Understanding in Computer Vision: A Survey
Feb 10, 2023



Contextual information plays an important role in many computer vision tasks, such as object detection, video action detection, image classification, etc. Recognizing a single object or action out of context could be sometimes very challenging, and context information may help improve the understanding of a scene or an event greatly. Appearance context information, e.g., colors or shapes of the background of an object can improve the recognition accuracy of the object in the scene. Semantic context (e.g. a keyboard on an empty desk vs. a keyboard next to a desktop computer ) will improve accuracy and exclude unrelated events. Context information that are not in the image itself, such as the time or location of an images captured, can also help to decide whether certain event or action should occur. Other types of context (e.g. 3D structure of a building) will also provide additional information to improve the accuracy. In this survey, different context information that has been used in computer vision tasks is reviewed. We categorize context into different types and different levels. We also review available machine learning models and image/video datasets that can employ context information. Furthermore, we compare context based integration and context-free integration in mainly two classes of tasks: image-based and video-based. Finally, this survey is concluded by a set of promising future directions in context learning and utilization.
SnapshotNet: Self-supervised Feature Learning for Point Cloud Data Segmentation Using Minimal Labeled Data
Jan 13, 2022
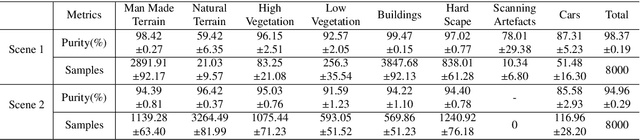
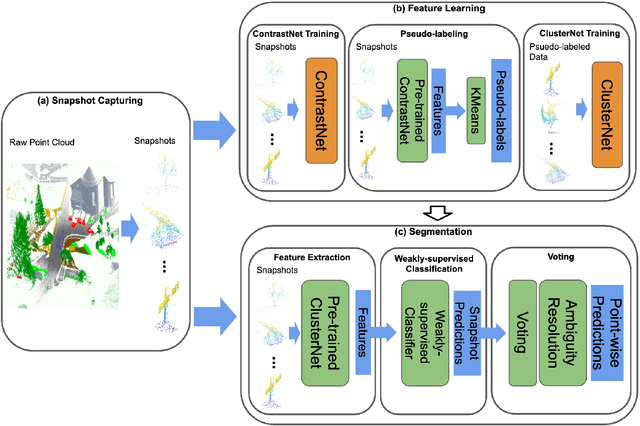
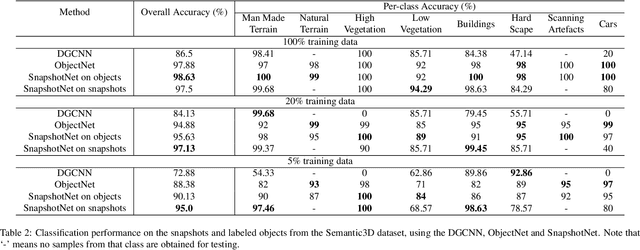
Manually annotating complex scene point cloud datasets is both costly and error-prone. To reduce the reliance on labeled data, a new model called SnapshotNet is proposed as a self-supervised feature learning approach, which directly works on the unlabeled point cloud data of a complex 3D scene. The SnapshotNet pipeline includes three stages. In the snapshot capturing stage, snapshots, which are defined as local collections of points, are sampled from the point cloud scene. A snapshot could be a view of a local 3D scan directly captured from the real scene, or a virtual view of such from a large 3D point cloud dataset. Snapshots could also be sampled at different sampling rates or fields of view (FOVs), thus multi-FOV snapshots, to capture scale information from the scene. In the feature learning stage, a new pre-text task called multi-FOV contrasting is proposed to recognize whether two snapshots are from the same object or not, within the same FOV or across different FOVs. Snapshots go through two self-supervised learning steps: the contrastive learning step with both part and scale contrasting, followed by a snapshot clustering step to extract higher level semantic features. Then a weakly-supervised segmentation stage is implemented by first training a standard SVM classifier on the learned features with a small fraction of labeled snapshots. The trained SVM is used to predict labels for input snapshots and predicted labels are converted into point-wise label assignments for semantic segmentation of the entire scene using a voting procedure. The experiments are conducted on the Semantic3D dataset and the results have shown that the proposed method is capable of learning effective features from snapshots of complex scene data without any labels. Moreover, the proposed method has shown advantages when comparing to the SOA method on weakly-supervised point cloud semantic segmentation.
NIDA-CLIFGAN: Natural Infrastructure Damage Assessment through Efficient Classification Combining Contrastive Learning, Information Fusion and Generative Adversarial Networks
Oct 27, 2021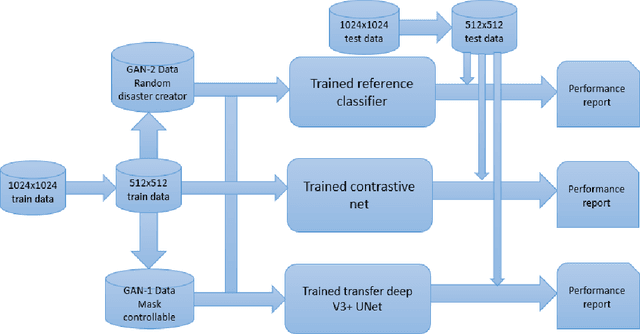


During natural disasters, aircraft and satellites are used to survey the impacted regions. Usually human experts are needed to manually label the degrees of the building damage so that proper humanitarian assistance and disaster response (HADR) can be achieved, which is labor-intensive and time-consuming. Expecting human labeling of major disasters over a wide area gravely slows down the HADR efforts. It is thus of crucial interest to take advantage of the cutting-edge Artificial Intelligence and Machine Learning techniques to speed up the natural infrastructure damage assessment process to achieve effective HADR. Accordingly, the paper demonstrates a systematic effort to achieve efficient building damage classification. First, two novel generative adversarial nets (GANs) are designed to augment data used to train the deep-learning-based classifier. Second, a contrastive learning based method using novel data structures is developed to achieve great performance. Third, by using information fusion, the classifier is effectively trained with very few training data samples for transfer learning. All the classifiers are small enough to be loaded in a smart phone or simple laptop for first responders. Based on the available overhead imagery dataset, results demonstrate data and computational efficiency with 10% of the collected data combined with a GAN reducing the time of computation from roughly half a day to about 1 hour with roughly similar classification performances.