 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifierQ: Enhancing LLM Test Time Compute with Q-Learning-based Verifiers
Paper and Code

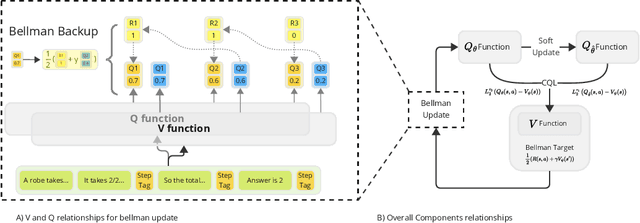
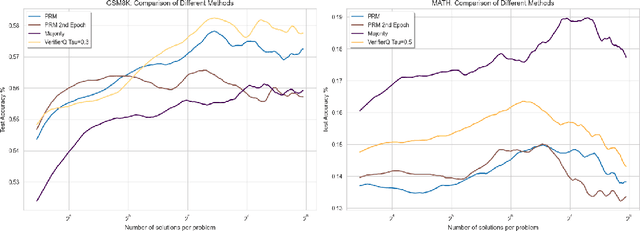
Recent advancements in test time compute, particularly through the use of verifier models, have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). This generator-verifier approach closely resembles the actor-critic framework in reinforcement learning (RL). However, current verifier models in LLMs often rely on supervised fine-tuning without temporal difference learning such as Q-learning. This paper introduces VerifierQ, a novel approach that integrates Offline Q-learning into LLM verifier models. We address three key challenges in applying Q-learning to LLMs: (1) handling utterance-level Markov Decision Processes (MDPs), (2) managing large action spaces, and (3) mitigating overestimation bias. VerifierQ introduces a modified Bellman update for bounded Q-values, incorporates Implicit Q-learning (IQL) for efficient action space management, and integrates a novel Conservative Q-learning (CQL) formulation for balanced Q-value estimation. Our method enables parallel Q-value computation and improving training efficiency. While recent work has explored RL techniques like MCTS for generators, VerifierQ is among the first to investigate the verifier (critic) aspect in LLMs through Q-learning. This integration of RL principles into verifier models complements existing advancements in generator techniques, potentially enabling more robust and adaptive reasoning in LLMs. Experimental results on mathematical reasoning tasks demonstrate VerifierQ's superior performance compared to traditional supervised fine-tuning approaches, with improvements in efficiency, accuracy and robustness. By enhancing the synergy between generation and evaluation capabilities, VerifierQ contributes to the ongoing evolution of AI systems in addressing complex cognitive tasks across various domains.