 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient Guidance Enables Test Time Control
Oct 02, 2025We introduce Policy Gradient Guidance (PGG), a simple extension of classifier-free guidance from diffusion models to classical policy gradient methods. PGG augments the policy gradient with an unconditional branch and interpolates conditional and unconditional branches, yielding a test-time control knob that modulates behavior without retraining. We provide a theoretical derivation showing that the additional normalization term vanishes under advantage estimation, leading to a clean guided policy gradient update. Empirically, we evaluate PGG on discrete and continuous control benchmarks. We find that conditioning dropout-central to diffusion guidance-offers gains in simple discrete tasks and low sample regimes, but dropout destabilizes continuous control. Training with modestly larger guidance ($\gamma>1$) consistently improves stability, sample efficiency, and controllability. Our results show that guidance, previously confined to diffusion policies, can be adapted to standard on-policy methods, opening new directions for controllable online reinforcement learning.
Learning to Reason Across Parallel Samples for LLM Reasoning
Jun 10, 2025Scaling test-time compute brings substantial performance gains for large language models (LLMs). By sampling multiple answers and heuristically aggregate their answers (e.g., either through majority voting or using verifiers to rank the answers), one can achieve consistent performance gains in math domains. In this paper, we propose a new way to leverage such multiple sample set. We train a compact LLM, called Sample Set Aggregator (SSA), that takes a concatenated sequence of multiple samples and output the final answer, optimizing it for the answer accuracy with reinforcement learning. Experiments on multiple reasoning datasets show that SSA outperforms other test-time scaling methods such as reward model-based re-ranking. Our approach also shows a promising generalization ability, across sample set sizes, base model families and scales, and tasks. By separating LLMs to generate answers and LLMs to analyze and aggregate sampled answers, our approach can work with the outputs from premier black box models easily and efficiently.
Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models
Mar 21, 2025Vision-Language Models (VLMs) excel at identifying and describing objects but struggle with spatial reasoning such as accurately understanding the relative positions of objects. Inspired by the dual-pathway (ventral-dorsal) model of human vision, we investigate why VLMs fail spatial tasks despite strong object recognition capabilities. Our interpretability-driven analysis reveals a critical underlying cause: vision embeddings in VLMs are treated primarily as semantic ``bag-of-tokens," overshadowing subtle yet crucial positional cues due to their disproportionately large embedding norms. We validate this insight through extensive diagnostic experiments, demonstrating minimal performance impact when token orders or fine-grained spatial details are removed. Guided by these findings, we propose simple, interpretable interventions, including normalizing vision embedding norms and extracting mid-layer spatially rich features, to restore spatial awareness. Empirical results on both our synthetic data and standard benchmarks demonstrate improved spatial reasoning capabilities, highlighting the value of interpretability-informed design choices. Our study not only uncovers fundamental limitations in current VLM architectures but also provides actionable insights for enhancing structured perception of visual scenes.
VerifierQ: Enhancing LLM Test Time Compute with Q-Learning-based Verifiers
Oct 10, 2024
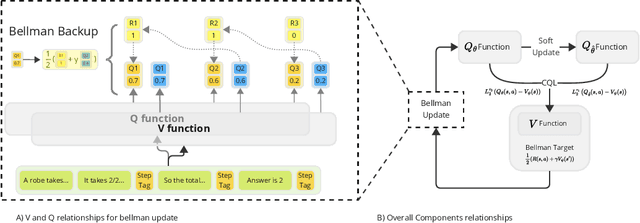
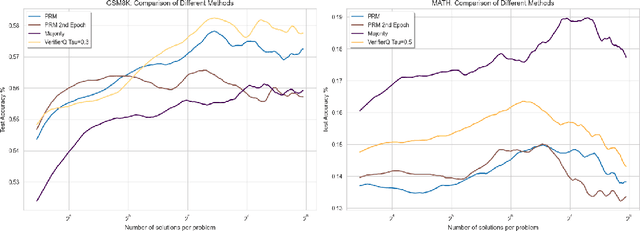
Recent advancements in test time compute, particularly through the use of verifier models, have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). This generator-verifier approach closely resembles the actor-critic framework in reinforcement learning (RL). However, current verifier models in LLMs often rely on supervised fine-tuning without temporal difference learning such as Q-learning. This paper introduces VerifierQ, a novel approach that integrates Offline Q-learning into LLM verifier models. We address three key challenges in applying Q-learning to LLMs: (1) handling utterance-level Markov Decision Processes (MDPs), (2) managing large action spaces, and (3) mitigating overestimation bias. VerifierQ introduces a modified Bellman update for bounded Q-values, incorporates Implicit Q-learning (IQL) for efficient action space management, and integrates a novel Conservative Q-learning (CQL) formulation for balanced Q-value estimation. Our method enables parallel Q-value computation and improving training efficiency. While recent work has explored RL techniques like MCTS for generators, VerifierQ is among the first to investigate the verifier (critic) aspect in LLMs through Q-learning. This integration of RL principles into verifier models complements existing advancements in generator techniques, potentially enabling more robust and adaptive reasoning in LLMs. Experimental results on mathematical reasoning tasks demonstrate VerifierQ's superior performance compared to traditional supervised fine-tuning approaches, with improvements in efficiency, accuracy and robustness. By enhancing the synergy between generation and evaluation capabilities, VerifierQ contributes to the ongoing evolution of AI systems in addressing complex cognitive tasks across various domains.