 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMC: A General Framework of Multi-stage Context Learning and Utilization for Visual Detection Tasks
Paper and Code
Jul 08, 2024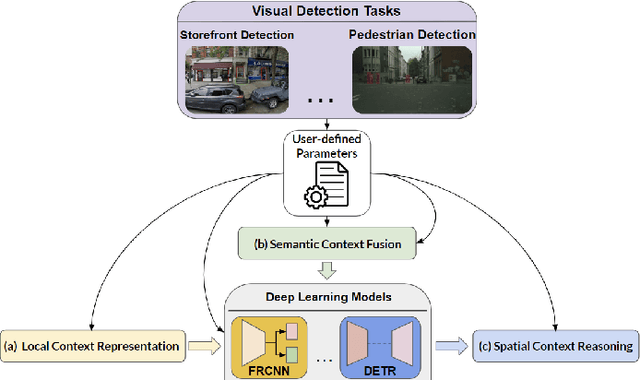
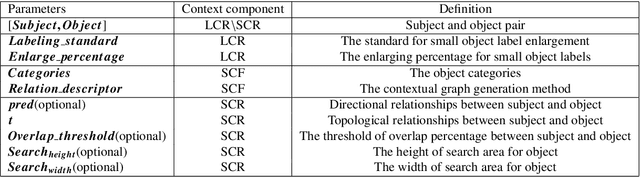
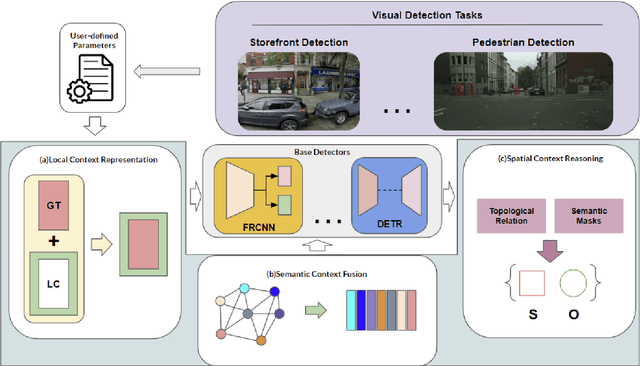
Various contextual information has been employed by many approaches for visual detection tasks. However, most of the existing approaches only focus on specific context for specific tasks. In this paper, GMC, a general framework is proposed for multistage context learning and utilization, with various deep network architectures for various visual detection tasks. The GMC framework encompasses three stages: preprocessing, training, and post-processing. In the preprocessing stage, the representation of local context is enhanced by utilizing commonly used labeling standards. During the training stage, semantic context information is fused with visual information, leveraging prior knowledge from the training dataset to capture semantic relationships. In the post-processing stage, general topological relations and semantic masks for stuff are incorporated to enable spatial context reasoning between objects. The proposed framework provides a comprehensive and adaptable solution for context learning and utilization in visual detection scenarios. The framework offers flexibility with user-defined configurations and provide adaptability to diverse network architectures and visual detection tasks, offering an automated and streamlined solution that minimizes user effort and inference time in context learning and reasoning. Experimental results on the visual detection tasks, for storefront object detection, pedestrian detection and COCO object detection, demonstrate that our framework outperforms previous state-of-the-art detectors and transformer architectures. The experiments also demonstrate that three contextual learning components can not only be applied individually and in combination, but can also be applied to various network architectures, and its flexibility and effectiveness in various detection scenarios.