 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Energy Management and Coordinated AIGC Workload Scheduling for Distributed Data Centers: A Diffusion-Aided Reward Shaping Approach
May 03, 2026Artificial intelligence-generated content (AIGC) has emerged as a transformative paradigm for automating the creation of diverse and customized content, giving rise to rapidly growing computational workloads in cloud data centers. It is imperative for AIGC service providers (ASPs) to strategically schedule AIGC workloads to reduce data center energy costs while guaranteeing high-quality content generation. However, the distinctive characteristics of AIGC services pose critical challenges, including model heterogeneity across ASPs, implicit service quality evaluation, and complex inference process control. To tackle these challenges, we propose a joint energy management and coordinated AIGC workload scheduling framework, which introduces an explicit mathematical characterization of service quality to promote both job transfer among ASPs and fine-grained inference process configuration. Moreover, various energy resources within data centers are jointly considered to enhance power usage flexibility. Subsequently, a system utility maximization problem is formulated to balance AIGC service revenue with operational penalties and costs. Nevertheless, the strong coupling among job scheduling decisions induces severe reward sparsity, which limits the effectiveness of existing deep reinforcement learning (DRL) algorithms. To address this issue, we develop a diffusion model-aided reward shaping approach to synthesize complementary reward signals through a multi-step denoising process. This approach is seamlessly integrated with DRL to enable efficient learning of scheduling policies under sparse environmental feedback. Experiments based on real-world models and datasets demonstrate that our scheme effectively accommodates electricity price fluctuations and AIGC model heterogeneity, while achieving superior learning convergence and system utility compared with benchmark methods.
CT-1: Vision-Language-Camera Models Transfer Spatial Reasoning Knowledge to Camera-Controllable Video Generation
Apr 10, 2026Camera-controllable video generation aims to synthesize videos with flexible and physically plausible camera movements. However, existing methods either provide imprecise camera control from text prompts or rely on labor-intensive manual camera trajectory parameters, limiting their use in automated scenarios. To address these issues, we propose a novel Vision-Language-Camera model, termed CT-1 (Camera Transformer 1), a specialized model designed to transfer spatial reasoning knowledge to video generation by accurately estimating camera trajectories. Built upon vision-language modules and a Diffusion Transformer model, CT-1 employs a Wavelet-based Regularization Loss in the frequency domain to effectively learn complex camera trajectory distributions. These trajectories are integrated into a video diffusion model to enable spatially aware camera control that aligns with user intentions. To facilitate the training of CT-1, we design a dedicated data curation pipeline and construct CT-200K, a large-scale dataset containing over 47M frames. Experimental results demonstrate that our framework successfully bridges the gap between spatial reasoning and video synthesis, yielding faithful and high-quality camera-controllable videos and improving camera control accuracy by 25.7% over prior methods.
Towards Open Environments and Instructions: General Vision-Language Navigation via Fast-Slow Interactive Reasoning
Jan 14, 2026Vision-Language Navigation aims to enable agents to navigate to a target location based on language instructions. Traditional VLN often follows a close-set assumption, i.e., training and test data share the same style of the input images and instructions. However, the real world is open and filled with various unseen environments, posing enormous difficulties for close-set methods. To this end, we focus on the General Scene Adaptation (GSA-VLN) task, aiming to learn generalized navigation ability by introducing diverse environments and inconsistent intructions.Towards this task, when facing unseen environments and instructions, the challenge mainly lies in how to enable the agent to dynamically produce generalized strategies during the navigation process. Recent research indicates that by means of fast and slow cognition systems, human beings could generate stable policies, which strengthen their adaptation for open world. Inspired by this idea, we propose the slow4fast-VLN, establishing a dynamic interactive fast-slow reasoning framework. The fast-reasoning module, an end-to-end strategy network, outputs actions via real-time input. It accumulates execution records in a history repository to build memory. The slow-reasoning module analyze the memories generated by the fast-reasoning module. Through deep reflection, it extracts experiences that enhance the generalization ability of decision-making. These experiences are structurally stored and used to continuously optimize the fast-reasoning module. Unlike traditional methods that treat fast-slow reasoning as independent mechanisms, our framework enables fast-slow interaction. By leveraging the experiences from slow reasoning. This interaction allows the system to continuously adapt and efficiently execute navigation tasks when facing unseen scenarios.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
SportsGPT: An LLM-driven Framework for Interpretable Sports Motion Assessment and Training Guidance
Dec 19, 2025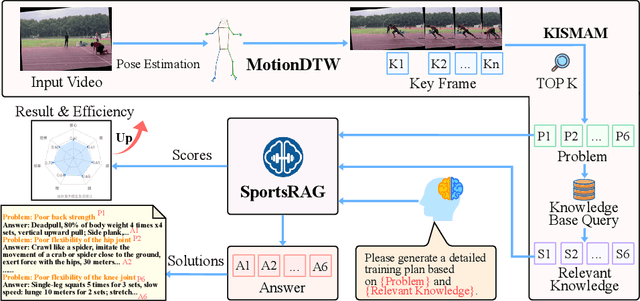
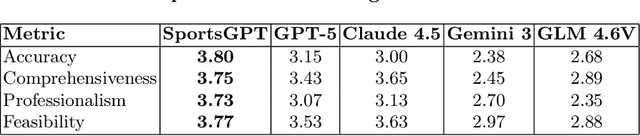
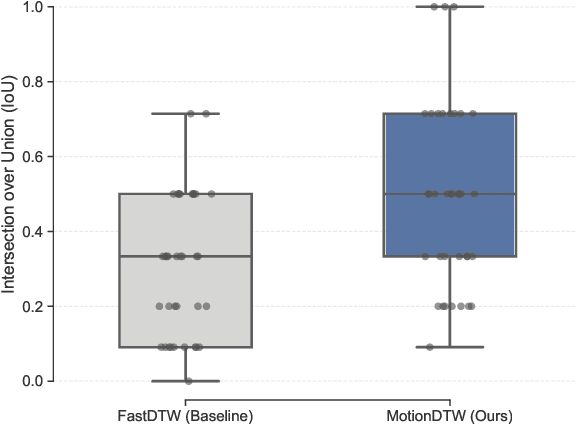

Existing intelligent sports analysis systems mainly focus on "scoring and visualization," often lacking automatic performance diagnosis and interpretable training guidance. Recent advances in Large Language Models (LLMs) and motion analysis techniques provide new opportunities to address the above limitations. In this paper, we propose SportsGPT, an LLM-driven framework for interpretable sports motion assessment and training guidance, which establishes a closed loop from motion time-series input to professional training guidance. First, given a set of high-quality target models, we introduce MotionDTW, a two-stage time series alignment algorithm designed for accurate keyframe extraction from skeleton-based motion sequences. Subsequently, we design a Knowledge-based Interpretable Sports Motion Assessment Model (KISMAM) to obtain a set of interpretable assessment metrics (e.g., insufficient extension) by contrasting the keyframes with the target models. Finally, we propose SportsRAG, a RAG-based training guidance model built upon Qwen3. Leveraging a 6B-token knowledge base, it prompts the LLM to generate professional training guidance by retrieving domain-specific QA pairs. Experimental results demonstrate that MotionDTW significantly outperforms traditional methods with lower temporal error and higher IoU scores. Furthermore, ablation studies validate the KISMAM and SportsRAG, confirming that SportsGPT surpasses general LLMs in diagnostic accuracy and professionalism.
Run, Ruminate, and Regulate: A Dual-process Thinking System for Vision-and-Language Navigation
Nov 18, 2025Vision-and-Language Navigation (VLN) requires an agent to dynamically explore complex 3D environments following human instructions. Recent research underscores the potential of harnessing large language models (LLMs) for VLN, given their commonsense knowledge and general reasoning capabilities. Despite their strengths, a substantial gap in task completion performance persists between LLM-based approaches and domain experts, as LLMs inherently struggle to comprehend real-world spatial correlations precisely. Additionally, introducing LLMs is accompanied with substantial computational cost and inference latency. To address these issues, we propose a novel dual-process thinking framework dubbed R3, integrating LLMs' generalization capabilities with VLN-specific expertise in a zero-shot manner. The framework comprises three core modules: Runner, Ruminator, and Regulator. The Runner is a lightweight transformer-based expert model that ensures efficient and accurate navigation under regular circumstances. The Ruminator employs a powerful multimodal LLM as the backbone and adopts chain-of-thought (CoT) prompting to elicit structured reasoning. The Regulator monitors the navigation progress and controls the appropriate thinking mode according to three criteria, integrating Runner and Ruminator harmoniously. Experimental results illustrate that R3 significantly outperforms other state-of-the-art methods, exceeding 3.28% and 3.30% in SPL and RGSPL respectively on the REVERIE benchmark. This pronounced enhancement highlights the effectiveness of our method in handling challenging VLN tasks.
Simulating Distribution Dynamics: Liquid Temporal Feature Evolution for Single-Domain Generalized Object Detection
Nov 13, 2025In this paper, we focus on Single-Domain Generalized Object Detection (Single-DGOD), aiming to transfer a detector trained on one source domain to multiple unknown domains. Existing methods for Single-DGOD typically rely on discrete data augmentation or static perturbation methods to expand data diversity, thereby mitigating the lack of access to target domain data. However, in real-world scenarios such as changes in weather or lighting conditions, domain shifts often occur continuously and gradually. Discrete augmentations and static perturbations fail to effectively capture the dynamic variation of feature distributions, thereby limiting the model's ability to perceive fine-grained cross-domain differences. To this end, we propose a new method, Liquid Temporal Feature Evolution, which simulates the progressive evolution of features from the source domain to simulated latent distributions by incorporating temporal modeling and liquid neural network-driven parameter adjustment. Specifically, we introduce controllable Gaussian noise injection and multi-scale Gaussian blurring to simulate initial feature perturbations, followed by temporal modeling and a liquid parameter adjustment mechanism to generate adaptive modulation parameters, enabling a smooth and continuous adaptation across domains. By capturing progressive cross-domain feature evolution and dynamically regulating adaptation paths, our method bridges the source-unknown domain distribution gap, significantly boosting generalization and robustness to unseen shifts. Significant performance improvements on the Diverse Weather dataset and Real-to-Art benchmark demonstrate the superiority of our method. Our code is available at https://github.com/2490o/LTFE.
Towards Reliable LLM-based Robot Planning via Combined Uncertainty Estimation
Oct 09, 2025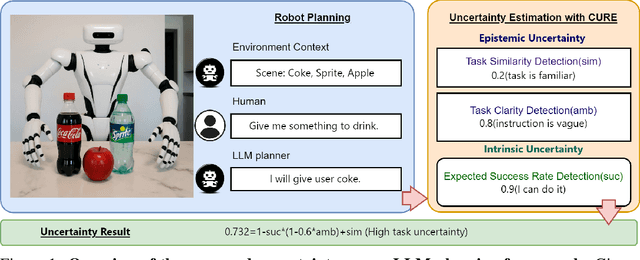
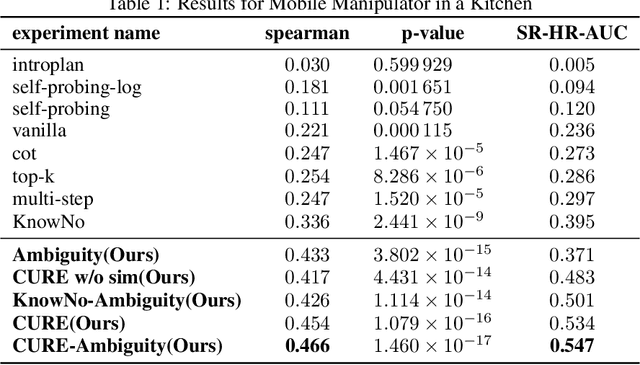
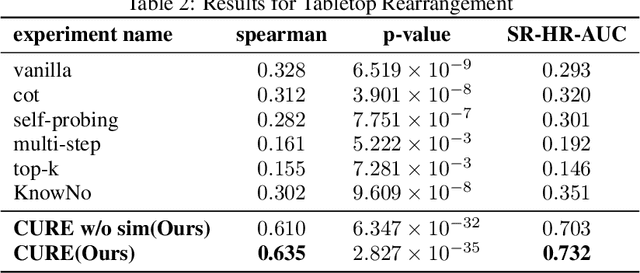
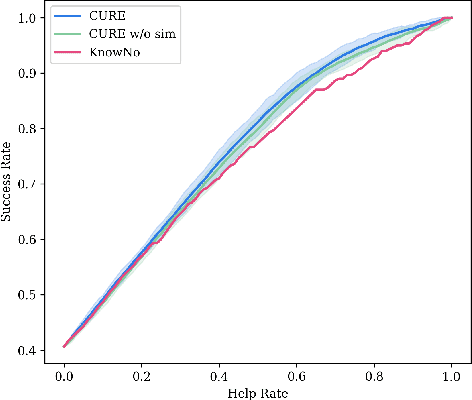
Large language models (LLMs) demonstrate advanced reasoning abilities, enabling robots to understand natural language instructions and generate high-level plans with appropriate grounding. However, LLM hallucinations present a significant challenge, often leading to overconfident yet potentially misaligned or unsafe plans. While researchers have explored uncertainty estimation to improve the reliability of LLM-based planning, existing studies have not sufficiently differentiated between epistemic and intrinsic uncertainty, limiting the effectiveness of uncertainty esti- mation. In this paper, we present Combined Uncertainty estimation for Reliable Embodied planning (CURE), which decomposes the uncertainty into epistemic and intrinsic uncertainty, each estimated separately. Furthermore, epistemic uncertainty is subdivided into task clarity and task familiarity for more accurate evaluation. The overall uncertainty assessments are obtained using random network distillation and multi-layer perceptron regression heads driven by LLM features. We validated our approach in two distinct experimental settings: kitchen manipulation and tabletop rearrangement experiments. The results show that, compared to existing methods, our approach yields uncertainty estimates that are more closely aligned with the actual execution outcomes.
AniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025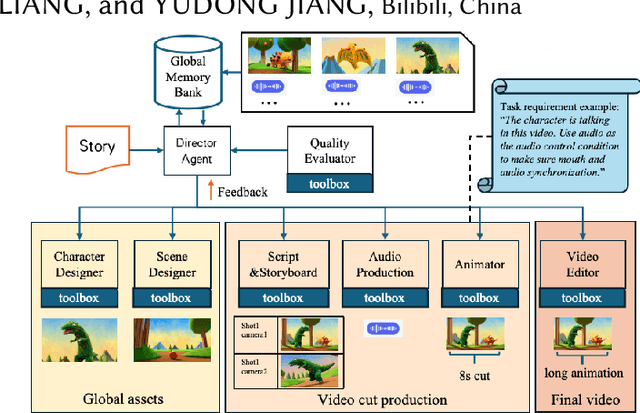
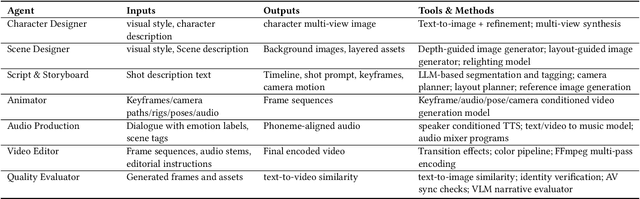

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025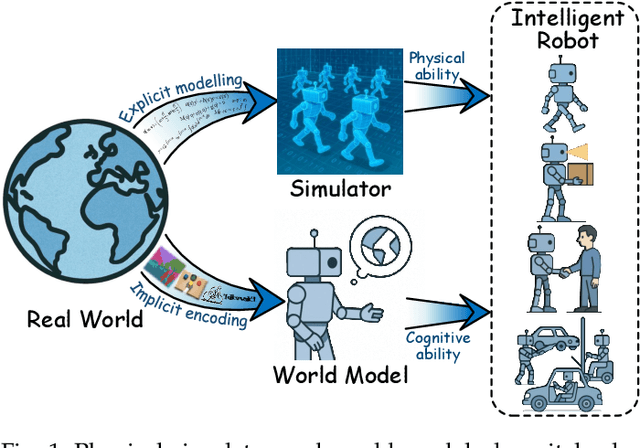
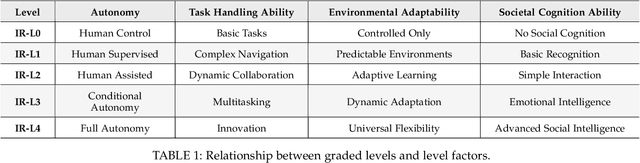
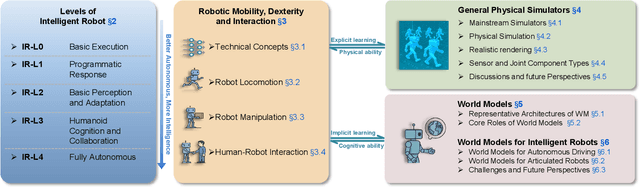

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.