 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Sides of the Same Optimization Coin: Model Degradation and Representation Collapse in Graph Foundation Models
Sep 11, 2025Graph foundation models, inspired by the success of LLMs, are designed to learn the optimal embedding from multi-domain TAGs for the downstream cross-task generalization capability. During our investigation, graph VQ-MAE stands out among the increasingly diverse landscape of GFM architectures. This is attributed to its ability to jointly encode topology and textual attributes from multiple domains into discrete embedding spaces with clear semantic boundaries. Despite its potential, domain generalization conflicts cause imperceptible pitfalls. In this paper, we instantiate two of them, and they are just like two sides of the same GFM optimization coin - Side 1 Model Degradation: The encoder and codebook fail to capture the diversity of inputs; Side 2 Representation Collapse: The hidden embedding and codebook vector fail to preserve semantic separability due to constraints from narrow representation subspaces. These two pitfalls (sides) collectively impair the decoder and generate the low-quality reconstructed supervision, causing the GFM optimization dilemma during pre-training (coin). Through empirical investigation, we attribute the above challenges to Information Bottleneck and Regularization Deficit. To address them, we propose MoT (Mixture-of-Tinkers) - (1) Information Tinker for Two Pitfalls, which utilizes an edge-wise semantic fusion strategy and a mixture-of-codebooks with domain-aware routing to improve information capacity. (2) Regularization Tinker for Optimization Coin, which utilizes two additional regularizations to further improve gradient supervision in our proposed Information Tinker. Notably, as a flexible architecture, MoT adheres to the scaling laws of GFM, offering a controllable model scale. Compared to SOTA baselines, experiments on 22 datasets across 6 domains demonstrate that MoT achieves significant improvements in supervised, few-shot, and zero-shot scenarios.
HIAL: A New Paradigm for Hypergraph Active Learning via Influence Maximization
Jul 28, 2025In recent years, Hypergraph Neural Networks (HNNs) have demonstrated immense potential in handling complex systems with high-order interactions. However, acquiring large-scale, high-quality labeled data for these models is costly, making Active Learning (AL) a critical technique. Existing Graph Active Learning (GAL) methods, when applied to hypergraphs, often rely on techniques like "clique expansion," which destroys the high-order structural information crucial to a hypergraph's success, thereby leading to suboptimal performance. To address this challenge, we introduce HIAL (Hypergraph Active Learning), a native active learning framework designed specifically for hypergraphs. We innovatively reformulate the Hypergraph Active Learning (HAL) problem as an Influence Maximization task. The core of HIAL is a dual-perspective influence function that, based on our novel "High-Order Interaction-Aware (HOI-Aware)" propagation mechanism, synergistically evaluates a node's feature-space coverage (via Magnitude of Influence, MoI) and its topological influence (via Expected Diffusion Value, EDV). We prove that this objective function is monotone and submodular, thus enabling the use of an efficient greedy algorithm with a formal (1-1/e) approximation guarantee. Extensive experiments on seven public datasets demonstrate that HIAL significantly outperforms state-of-the-art baselines in terms of performance, efficiency, generality, and robustness, establishing an efficient and powerful new paradigm for active learning on hypergraphs.
Toward General and Robust LLM-enhanced Text-attributed Graph Learning
Apr 03, 2025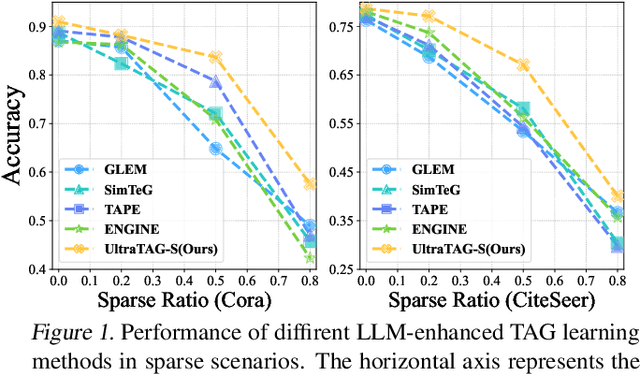

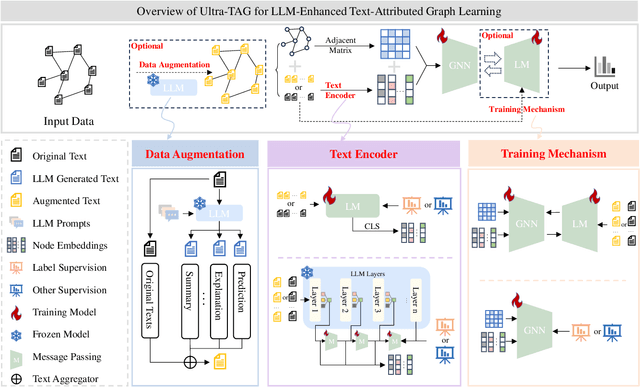

Recent advancements in Large Language Models (LLMs) and the proliferation of Text-Attributed Graphs (TAGs) across various domains have positioned LLM-enhanced TAG learning as a critical research area. By utilizing rich graph descriptions, this paradigm leverages LLMs to generate high-quality embeddings, thereby enhancing the representational capacity of Graph Neural Networks (GNNs). However, the field faces significant challenges: (1) the absence of a unified framework to systematize the diverse optimization perspectives arising from the complex interactions between LLMs and GNNs, and (2) the lack of a robust method capable of handling real-world TAGs, which often suffer from texts and edge sparsity, leading to suboptimal performance. To address these challenges, we propose UltraTAG, a unified pipeline for LLM-enhanced TAG learning. UltraTAG provides a unified comprehensive and domain-adaptive framework that not only organizes existing methodologies but also paves the way for future advancements in the field. Building on this framework, we propose UltraTAG-S, a robust instantiation of UltraTAG designed to tackle the inherent sparsity issues in real-world TAGs. UltraTAG-S employs LLM-based text propagation and text augmentation to mitigate text sparsity, while leveraging LLM-augmented node selection techniques based on PageRank and edge reconfiguration strategies to address edge sparsity. Our extensive experiments demonstrate that UltraTAG-S significantly outperforms existing baselines, achieving improvements of 2.12\% and 17.47\% in ideal and sparse settings, respectively. Moreover, as the data sparsity ratio increases, the performance improvement of UltraTAG-S also rises, which underscores the effectiveness and robustness of UltraTAG-S.
DiRW: Path-Aware Digraph Learning for Heterophily
Oct 14, 2024Recently, graph neural network (GNN) has emerged as a powerful representation learning tool for graph-structured data. However, most approaches are tailored for undirected graphs, neglecting the abundant information embedded in the edges of directed graphs (digraphs). In fact, digraphs are widely applied in the real world (e.g., social networks and recommendations) and are also confirmed to offer a new perspective for addressing topological heterophily challenges (i.e., connected nodes have complex patterns of feature distribution or labels). Despite recent significant advancements in DiGNNs, existing spatial- and spectral-based methods have inherent limitations due to the complex learning mechanisms and reliance on high-quality topology, leading to low efficiency and unstable performance. To address these issues, we propose Directed Random Walk (DiRW), which can be viewed as a plug-and-play strategy or an innovative neural architecture that provides a guidance or new learning paradigm for most spatial-based methods or digraphs. Specifically, DiRW incorporates a direction-aware path sampler optimized from the perspectives of walk probability, length, and number in a weight-free manner by considering node profiles and topological structure. Building upon this, DiRW utilizes a node-wise learnable path aggregator for generalized messages obtained by our proposed adaptive walkers to represent the current node. Extensive experiments on 9 datasets demonstrate that DiRW: (1) enhances most spatial-based methods as a plug-and-play strategy; (2) achieves SOTA performance as a new digraph learning paradigm.