 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryMem: Multi-shot Long Video Storytelling with Memory
Dec 22, 2025
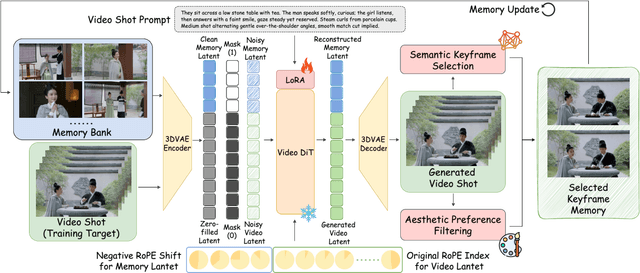

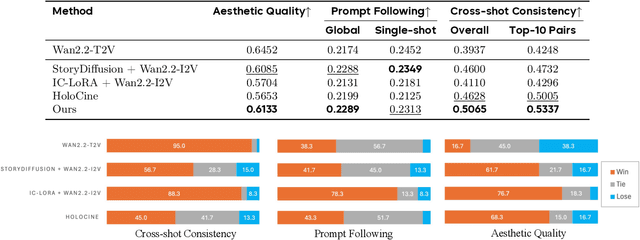
Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
An Automatic Detection Method for Hematoma Features in Placental Abruption Ultrasound Images Based on Few-Shot Learning
Oct 24, 2025Placental abruption is a severe complication during pregnancy, and its early accurate diagnosis is crucial for ensuring maternal and fetal safety. Traditional ultrasound diagnostic methods heavily rely on physician experience, leading to issues such as subjective bias and diagnostic inconsistencies. This paper proposes an improved model, EH-YOLOv11n (Enhanced Hemorrhage-YOLOv11n), based on small-sample learning, aiming to achieve automatic detection of hematoma features in placental ultrasound images. The model enhances performance through multidimensional optimization: it integrates wavelet convolution and coordinate convolution to strengthen frequency and spatial feature extraction; incorporates a cascaded group attention mechanism to suppress ultrasound artifacts and occlusion interference, thereby improving bounding box localization accuracy. Experimental results demonstrate a detection accuracy of 78%, representing a 2.5% improvement over YOLOv11n and a 13.7% increase over YOLOv8. The model exhibits significant superiority in precision-recall curves, confidence scores, and occlusion scenarios. Combining high accuracy with real-time processing, this model provides a reliable solution for computer-aided diagnosis of placental abruption, holding significant clinical application value.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025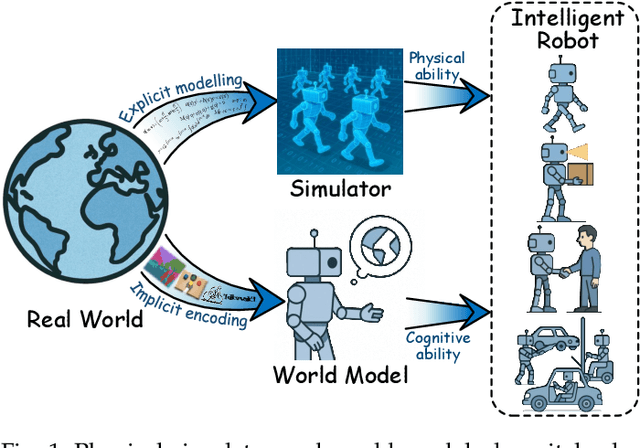
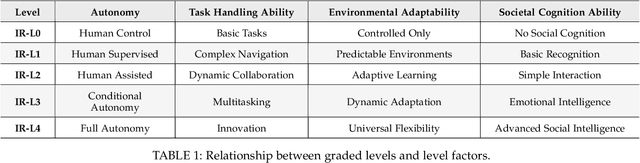
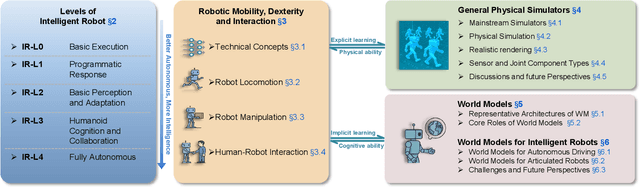

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
WiP: Towards a Secure SECP256K1 for Crypto Wallets: Hardware Architecture and Implementation
Nov 06, 2024



The SECP256K1 elliptic curve algorithm is fundamental in cryptocurrency wallets for generating secure public keys from private keys, thereby ensuring the protection and ownership of blockchain-based digital assets. However, the literature highlights several successful side-channel attacks on hardware wallets that exploit SECP256K1 to extract private keys. This work proposes a novel hardware architecture for SECP256K1, optimized for side-channel attack resistance and efficient resource utilization. The architecture incorporates complete addition formulas, temporary registers, and parallel processing techniques, making elliptic curve point addition and doubling operations indistinguishable. Implementation results demonstrate an average reduction of 45% in LUT usage compared to similar works, emphasizing the design's resource efficiency.
MultiConfederated Learning: Inclusive Non-IID Data handling with Decentralized Federated Learning
Apr 20, 2024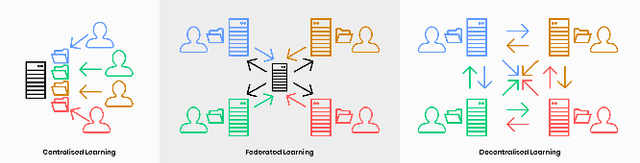

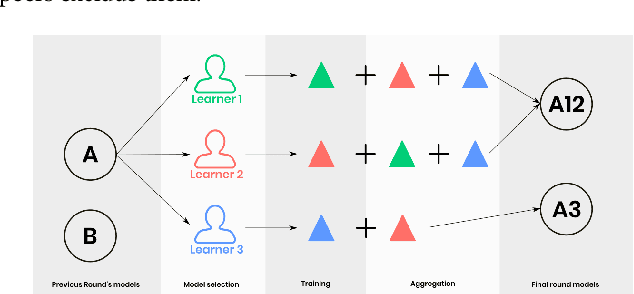

Federated Learning (FL) has emerged as a prominent privacy-preserving technique for enabling use cases like confidential clinical machine learning. FL operates by aggregating models trained by remote devices which owns the data. Thus, FL enables the training of powerful global models using crowd-sourced data from a large number of learners, without compromising their privacy. However, the aggregating server is a single point of failure when generating the global model. Moreover, the performance of the model suffers when the data is not independent and identically distributed (non-IID data) on all remote devices. This leads to vastly different models being aggregated, which can reduce the performance by as much as 50% in certain scenarios. In this paper, we seek to address the aforementioned issues while retaining the benefits of FL. We propose MultiConfederated Learning: a decentralized FL framework which is designed to handle non-IID data. Unlike traditional FL, MultiConfederated Learning will maintain multiple models in parallel (instead of a single global model) to help with convergence when the data is non-IID. With the help of transfer learning, learners can converge to fewer models. In order to increase adaptability, learners are allowed to choose which updates to aggregate from their peers.
NeurIT: Pushing the Limit of Neural Inertial Tracking for Indoor Robotic IoT
Apr 13, 2024Inertial tracking is vital for robotic IoT and has gained popularity thanks to the ubiquity of low-cost Inertial Measurement Units (IMUs) and deep learning-powered tracking algorithms. Existing works, however, have not fully utilized IMU measurements, particularly magnetometers, nor maximized the potential of deep learning to achieve the desired accuracy. To enhance the tracking accuracy for indoor robotic applications, we introduce NeurIT, a sequence-to-sequence framework that elevates tracking accuracy to a new level. NeurIT employs a Time-Frequency Block-recurrent Transformer (TF-BRT) at its core, combining the power of recurrent neural network (RNN) and Transformer to learn representative features in both time and frequency domains. To fully utilize IMU information, we strategically employ body-frame differentiation of the magnetometer, which considerably reduces the tracking error. NeurIT is implemented on a customized robotic platform and evaluated in various indoor environments. Experimental results demonstrate that NeurIT achieves a mere 1-meter tracking error over a 300-meter distance. Notably, it significantly outperforms state-of-the-art baselines by 48.21% on unseen data. NeurIT also performs comparably to the visual-inertial approach (Tango Phone) in vision-favored conditions and surpasses it in plain environments. We believe NeurIT takes an important step forward toward practical neural inertial tracking for ubiquitous and scalable tracking of robotic things. NeurIT, including the source code and the dataset, is open-sourced here: https://github.com/NeurIT-Project/NeurIT.
DiffMorpher: Unleashing the Capability of Diffusion Models for Image Morphing
Dec 12, 2023
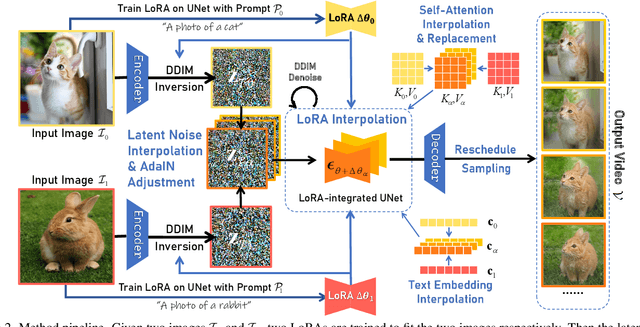
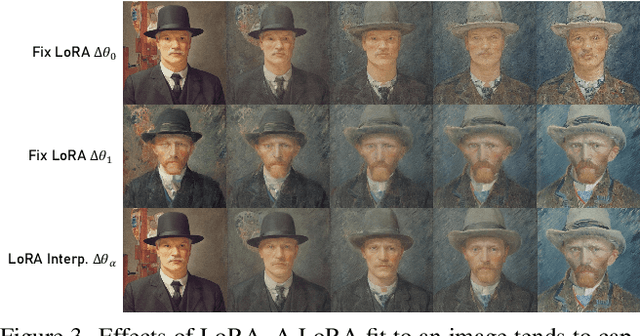
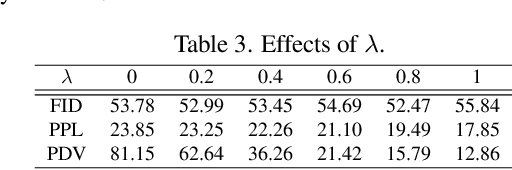
Diffusion models have achieved remarkable image generation quality surpassing previous generative models. However, a notable limitation of diffusion models, in comparison to GANs, is their difficulty in smoothly interpolating between two image samples, due to their highly unstructured latent space. Such a smooth interpolation is intriguing as it naturally serves as a solution for the image morphing task with many applications. In this work, we present DiffMorpher, the first approach enabling smooth and natural image interpolation using diffusion models. Our key idea is to capture the semantics of the two images by fitting two LoRAs to them respectively, and interpolate between both the LoRA parameters and the latent noises to ensure a smooth semantic transition, where correspondence automatically emerges without the need for annotation. In addition, we propose an attention interpolation and injection technique and a new sampling schedule to further enhance the smoothness between consecutive images. Extensive experiments demonstrate that DiffMorpher achieves starkly better image morphing effects than previous methods across a variety of object categories, bridging a critical functional gap that distinguished diffusion models from GANs.
TogetherNet: Bridging Image Restoration and Object Detection Together via Dynamic Enhancement Learning
Sep 03, 2022


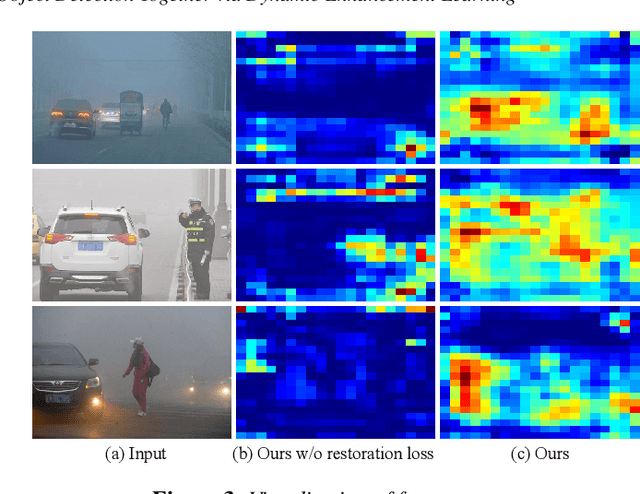
Adverse weather conditions such as haze, rain, and snow often impair the quality of captured images, causing detection networks trained on normal images to generalize poorly in these scenarios. In this paper, we raise an intriguing question - if the combination of image restoration and object detection, can boost the performance of cutting-edge detectors in adverse weather conditions. To answer it, we propose an effective yet unified detection paradigm that bridges these two subtasks together via dynamic enhancement learning to discern objects in adverse weather conditions, called TogetherNet. Different from existing efforts that intuitively apply image dehazing/deraining as a pre-processing step, TogetherNet considers a multi-task joint learning problem. Following the joint learning scheme, clean features produced by the restoration network can be shared to learn better object detection in the detection network, thus helping TogetherNet enhance the detection capacity in adverse weather conditions. Besides the joint learning architecture, we design a new Dynamic Transformer Feature Enhancement module to improve the feature extraction and representation capabilities of TogetherNet. Extensive experiments on both synthetic and real-world datasets demonstrate that our TogetherNet outperforms the state-of-the-art detection approaches by a large margin both quantitatively and qualitatively. Source code is available at https://github.com/yz-wang/TogetherNet.