 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Wideband WiFi Sensing via Self-Conditioned CSI Extrapolation
Jan 10, 2026WiFi sensing has suffered from the limited bandwidths designated for its original communication purpose, leading to fundamental limits in multipath resolution and thus multi-user sensing. Unfortunately, it is practically prohibitive to obtain large bandwidths on commercial WiFi, considering the conflict between the limited spectrum and the crowded networks. In this paper, we present Neuro-Wideband (NWB), a completely different paradigm that enables wideband WiFi sensing without specialized hardware or extra channel measurements. Our key insight is that any physical measurement of channel state information (CSI) inherently encapsulates multipath parameters, which, while unsolvable in isolation, can be transformed into an expanded form of CSI (eCSI) approximating measurements over a broader bandwidth. To ground this insight, we propose WUKONG to address NWB as a unique self-conditioned learning problem that can be trained by using any existing CSI data as self-labeled samples. WUKONG introduces a novel deep learning framework by integrating Transformer and Diffusion models, which captures sample-specific multipath parameters and transfers this sample-level knowledge to the outcome eCSI. We conduct real-world experiments to evaluate WUKONG on diverse WiFi signals across protocols and bandwidths. The results show the promising effectiveness of NWB, which is further demonstrated through case studies on localization and multi-person breathing monitoring using eCSI. Overall, the proposed NWB promises a practical pathway toward realizing wideband WiFi sensing on commodity hardware, expanding the design space of wireless sensing systems.
Information-Preserving CSI Feedback: Invertible Networks with Endogenous Quantization and Channel Error Mitigation
Jul 27, 2025



Deep learning has emerged as a promising solution for efficient channel state information (CSI) feedback in frequency division duplex (FDD) massive MIMO systems. Conventional deep learning-based methods typically rely on a deep autoencoder to compress the CSI, which leads to irreversible information loss and degrades reconstruction accuracy. This paper introduces InvCSINet, an information-preserving CSI feedback framework based on invertible neural networks (INNs). By leveraging the bijective nature of INNs, the model ensures information-preserving compression and reconstruction with shared model parameters. To address practical challenges such as quantization and channel-induced errors, we endogenously integrate an adaptive quantization module, a differentiable bit-channel distortion module and an information compensation module into the INN architecture. This design enables the network to learn and compensate the information loss during CSI compression, quantization, and noisy transmission, thereby preserving the CSI integrity throughout the feedback process. Simulation results validate the effectiveness of the proposed scheme, demonstrating superior CSI recovery performance and robustness to practical impairments with a lightweight architecture.
ProMind-LLM: Proactive Mental Health Care via Causal Reasoning with Sensor Data
May 20, 2025Mental health risk is a critical global public health challenge, necessitating innovative and reliable assessment methods. With the development of large language models (LLMs), they stand out to be a promising tool for explainable mental health care applications. Nevertheless, existing approaches predominantly rely on subjective textual mental records, which can be distorted by inherent mental uncertainties, leading to inconsistent and unreliable predictions. To address these limitations, this paper introduces ProMind-LLM. We investigate an innovative approach integrating objective behavior data as complementary information alongside subjective mental records for robust mental health risk assessment. Specifically, ProMind-LLM incorporates a comprehensive pipeline that includes domain-specific pretraining to tailor the LLM for mental health contexts, a self-refine mechanism to optimize the processing of numerical behavioral data, and causal chain-of-thought reasoning to enhance the reliability and interpretability of its predictions. Evaluations of two real-world datasets, PMData and Globem, demonstrate the effectiveness of our proposed methods, achieving substantial improvements over general LLMs. We anticipate that ProMind-LLM will pave the way for more dependable, interpretable, and scalable mental health case solutions.
One-shot Federated Learning Methods: A Practical Guide
Feb 13, 2025One-shot Federated Learning (OFL) is a distributed machine learning paradigm that constrains client-server communication to a single round, addressing privacy and communication overhead issues associated with multiple rounds of data exchange in traditional Federated Learning (FL). OFL demonstrates the practical potential for integration with future approaches that require collaborative training models, such as large language models (LLMs). However, current OFL methods face two major challenges: data heterogeneity and model heterogeneity, which result in subpar performance compared to conventional FL methods. Worse still, despite numerous studies addressing these limitations, a comprehensive summary is still lacking. To address these gaps, this paper presents a systematic analysis of the challenges faced by OFL and thoroughly reviews the current methods. We also offer an innovative categorization method and analyze the trade-offs of various techniques. Additionally, we discuss the most promising future directions and the technologies that should be integrated into the OFL field. This work aims to provide guidance and insights for future research.
USpeech: Ultrasound-Enhanced Speech with Minimal Human Effort via Cross-Modal Synthesis
Oct 29, 2024



Speech enhancement is crucial in human-computer interaction, especially for ubiquitous devices. Ultrasound-based speech enhancement has emerged as an attractive choice because of its superior ubiquity and performance. However, inevitable interference from unexpected and unintended sources during audio-ultrasound data acquisition makes existing solutions rely heavily on human effort for data collection and processing. This leads to significant data scarcity that limits the full potential of ultrasound-based speech enhancement. To address this, we propose USpeech, a cross-modal ultrasound synthesis framework for speech enhancement with minimal human effort. At its core is a two-stage framework that establishes correspondence between visual and ultrasonic modalities by leveraging audible audio as a bridge. This approach overcomes challenges from the lack of paired video-ultrasound datasets and the inherent heterogeneity between video and ultrasound data. Our framework incorporates contrastive video-audio pre-training to project modalities into a shared semantic space and employs an audio-ultrasound encoder-decoder for ultrasound synthesis. We then present a speech enhancement network that enhances speech in the time-frequency domain and recovers the clean speech waveform via a neural vocoder. Comprehensive experiments show USpeech achieves remarkable performance using synthetic ultrasound data comparable to physical data, significantly outperforming state-of-the-art ultrasound-based speech enhancement baselines. USpeech is open-sourced at https://github.com/aiot-lab/USpeech/.
MindGuard: Towards Accessible and Sitgma-free Mental Health First Aid via Edge LLM
Sep 16, 2024Mental health disorders are among the most prevalent diseases worldwide, affecting nearly one in four people. Despite their widespread impact, the intervention rate remains below 25%, largely due to the significant cooperation required from patients for both diagnosis and intervention. The core issue behind this low treatment rate is stigma, which discourages over half of those affected from seeking help. This paper presents MindGuard, an accessible, stigma-free, and professional mobile mental healthcare system designed to provide mental health first aid. The heart of MindGuard is an innovative edge LLM, equipped with professional mental health knowledge, that seamlessly integrates objective mobile sensor data with subjective Ecological Momentary Assessment records to deliver personalized screening and intervention conversations. We conduct a broad evaluation of MindGuard using open datasets spanning four years and real-world deployment across various mobile devices involving 20 subjects for two weeks. Remarkably, MindGuard achieves results comparable to GPT-4 and outperforms its counterpart with more than 10 times the model size. We believe that MindGuard paves the way for mobile LLM applications, potentially revolutionizing mental healthcare practices by substituting self-reporting and intervention conversations with passive, integrated monitoring within daily life, thus ensuring accessible and stigma-free mental health support.
RS-BNN: A Deep Learning Framework for the Optimal Beamforming Design of Rate-Splitting Multiple Access
Jul 09, 2024



Rate splitting multiple access (RSMA) relies on beamforming design for attaining spectral efficiency and energy efficiency gains over traditional multiple access schemes. While conventional optimization approaches such as weighted minimum mean square error (WMMSE) achieve suboptimal solutions for RSMA beamforming optimization, they are computationally demanding. A novel approach based on fractional programming (FP) has unveiled the optimal beamforming structure (OBS) for RSMA. This method, combined with a hyperplane fixed point iteration (HFPI) approach, named FP-HFPI, provides suboptimal beamforming solutions with identical sum rate performance but much lower computational complexity compared to WMMSE. Inspired by such an approach, in this work, a novel deep unfolding framework based on FP-HFPI, named rate-splitting-beamforming neural network (RS-BNN), is proposed to unfold the FP-HFPI algorithm. Numerical results indicate that the proposed RS-BNN attains a level of performance closely matching that of WMMSE and FP-HFPI, while dramatically reducing the computational complexity.
NeurIT: Pushing the Limit of Neural Inertial Tracking for Indoor Robotic IoT
Apr 13, 2024Inertial tracking is vital for robotic IoT and has gained popularity thanks to the ubiquity of low-cost Inertial Measurement Units (IMUs) and deep learning-powered tracking algorithms. Existing works, however, have not fully utilized IMU measurements, particularly magnetometers, nor maximized the potential of deep learning to achieve the desired accuracy. To enhance the tracking accuracy for indoor robotic applications, we introduce NeurIT, a sequence-to-sequence framework that elevates tracking accuracy to a new level. NeurIT employs a Time-Frequency Block-recurrent Transformer (TF-BRT) at its core, combining the power of recurrent neural network (RNN) and Transformer to learn representative features in both time and frequency domains. To fully utilize IMU information, we strategically employ body-frame differentiation of the magnetometer, which considerably reduces the tracking error. NeurIT is implemented on a customized robotic platform and evaluated in various indoor environments. Experimental results demonstrate that NeurIT achieves a mere 1-meter tracking error over a 300-meter distance. Notably, it significantly outperforms state-of-the-art baselines by 48.21% on unseen data. NeurIT also performs comparably to the visual-inertial approach (Tango Phone) in vision-favored conditions and surpasses it in plain environments. We believe NeurIT takes an important step forward toward practical neural inertial tracking for ubiquitous and scalable tracking of robotic things. NeurIT, including the source code and the dataset, is open-sourced here: https://github.com/NeurIT-Project/NeurIT.
Are You Being Tracked? Discover the Power of Zero-Shot Trajectory Tracing with LLMs!
Mar 10, 2024

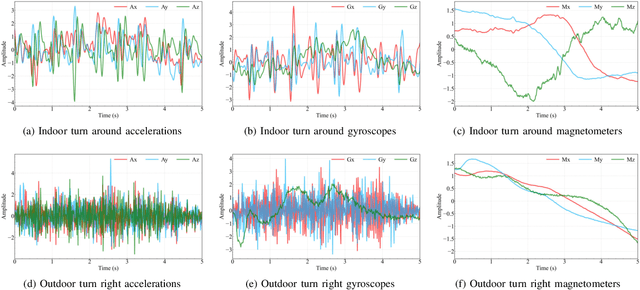

There is a burgeoning discussion around the capabilities of Large Language Models (LLMs) in acting as fundamental components that can be seamlessly incorporated into Artificial Intelligence of Things (AIoT) to interpret complex trajectories. This study introduces LLMTrack, a model that illustrates how LLMs can be leveraged for Zero-Shot Trajectory Recognition by employing a novel single-prompt technique that combines role-play and think step-by-step methodologies with unprocessed Inertial Measurement Unit (IMU) data. We evaluate the model using real-world datasets designed to challenge it with distinct trajectories characterized by indoor and outdoor scenarios. In both test scenarios, LLMTrack not only meets but exceeds the performance benchmarks set by traditional machine learning approaches and even contemporary state-of-the-art deep learning models, all without the requirement of training on specialized datasets. The results of our research suggest that, with strategically designed prompts, LLMs can tap into their extensive knowledge base and are well-equipped to analyze raw sensor data with remarkable effectiveness.
HARGPT: Are LLMs Zero-Shot Human Activity Recognizers?
Mar 05, 2024



There is an ongoing debate regarding the potential of Large Language Models (LLMs) as foundational models seamlessly integrated with Cyber-Physical Systems (CPS) for interpreting the physical world. In this paper, we carry out a case study to answer the following question: Are LLMs capable of zero-shot human activity recognition (HAR). Our study, HARGPT, presents an affirmative answer by demonstrating that LLMs can comprehend raw IMU data and perform HAR tasks in a zero-shot manner, with only appropriate prompts. HARGPT inputs raw IMU data into LLMs and utilizes the role-play and think step-by-step strategies for prompting. We benchmark HARGPT on GPT4 using two public datasets of different inter-class similarities and compare various baselines both based on traditional machine learning and state-of-the-art deep classification models. Remarkably, LLMs successfully recognize human activities from raw IMU data and consistently outperform all the baselines on both datasets. Our findings indicate that by effective prompting, LLMs can interpret raw IMU data based on their knowledge base, possessing a promising potential to analyze raw sensor data of the physical world effectively.