 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Wideband WiFi Sensing via Self-Conditioned CSI Extrapolation
Jan 10, 2026WiFi sensing has suffered from the limited bandwidths designated for its original communication purpose, leading to fundamental limits in multipath resolution and thus multi-user sensing. Unfortunately, it is practically prohibitive to obtain large bandwidths on commercial WiFi, considering the conflict between the limited spectrum and the crowded networks. In this paper, we present Neuro-Wideband (NWB), a completely different paradigm that enables wideband WiFi sensing without specialized hardware or extra channel measurements. Our key insight is that any physical measurement of channel state information (CSI) inherently encapsulates multipath parameters, which, while unsolvable in isolation, can be transformed into an expanded form of CSI (eCSI) approximating measurements over a broader bandwidth. To ground this insight, we propose WUKONG to address NWB as a unique self-conditioned learning problem that can be trained by using any existing CSI data as self-labeled samples. WUKONG introduces a novel deep learning framework by integrating Transformer and Diffusion models, which captures sample-specific multipath parameters and transfers this sample-level knowledge to the outcome eCSI. We conduct real-world experiments to evaluate WUKONG on diverse WiFi signals across protocols and bandwidths. The results show the promising effectiveness of NWB, which is further demonstrated through case studies on localization and multi-person breathing monitoring using eCSI. Overall, the proposed NWB promises a practical pathway toward realizing wideband WiFi sensing on commodity hardware, expanding the design space of wireless sensing systems.
Generative AI Meets Wireless Sensing: Towards Wireless Foundation Model
Sep 18, 2025



Generative Artificial Intelligence (GenAI) has made significant advancements in fields such as computer vision (CV) and natural language processing (NLP), demonstrating its capability to synthesize high-fidelity data and improve generalization. Recently, there has been growing interest in integrating GenAI into wireless sensing systems. By leveraging generative techniques such as data augmentation, domain adaptation, and denoising, wireless sensing applications, including device localization, human activity recognition, and environmental monitoring, can be significantly improved. This survey investigates the convergence of GenAI and wireless sensing from two complementary perspectives. First, we explore how GenAI can be integrated into wireless sensing pipelines, focusing on two modes of integration: as a plugin to augment task-specific models and as a solver to directly address sensing tasks. Second, we analyze the characteristics of mainstream generative models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models, and discuss their applicability and unique advantages across various wireless sensing tasks. We further identify key challenges in applying GenAI to wireless sensing and outline a future direction toward a wireless foundation model: a unified, pre-trained design capable of scalable, adaptable, and efficient signal understanding across diverse sensing tasks.
Unlocking Interpretability for RF Sensing: A Complex-Valued White-Box Transformer
Jul 29, 2025The empirical success of deep learning has spurred its application to the radio-frequency (RF) domain, leading to significant advances in Deep Wireless Sensing (DWS). However, most existing DWS models function as black boxes with limited interpretability, which hampers their generalizability and raises concerns in security-sensitive physical applications. In this work, inspired by the remarkable advances of white-box transformers, we present RF-CRATE, the first mathematically interpretable deep network architecture for RF sensing, grounded in the principles of complex sparse rate reduction. To accommodate the unique RF signals, we conduct non-trivial theoretical derivations that extend the original real-valued white-box transformer to the complex domain. By leveraging the CR-Calculus framework, we successfully construct a fully complex-valued white-box transformer with theoretically derived self-attention and residual multi-layer perceptron modules. Furthermore, to improve the model's ability to extract discriminative features from limited wireless data, we introduce Subspace Regularization, a novel regularization strategy that enhances feature diversity, resulting in an average performance improvement of 19.98% across multiple sensing tasks. We extensively evaluate RF-CRATE against seven baselines with multiple public and self-collected datasets involving different RF signals. The results show that RF-CRATE achieves performance on par with thoroughly engineered black-box models, while offering full mathematical interpretability. More importantly, by extending CRATE to the complex domain, RF-CRATE yields substantial improvements, achieving an average classification gain of 5.08% and reducing regression error by 10.34% across diverse sensing tasks compared to CRATE. RF-CRATE is fully open-sourced at: https://github.com/rfcrate/RF_CRATE.
Experience Paper: Scaling WiFi Sensing to Millions of Commodity Devices for Ubiquitous Home Monitoring
Jun 04, 2025WiFi-based home monitoring has emerged as a compelling alternative to traditional camera- and sensor-based solutions, offering wide coverage with minimal intrusion by leveraging existing wireless infrastructure. This paper presents key insights and lessons learned from developing and deploying a large-scale WiFi sensing solution, currently operational across over 10 million commodity off-the-shelf routers and 100 million smart bulbs worldwide. Through this extensive deployment, we identify four real-world challenges that hinder the practical adoption of prior research: 1) Non-human movements (e.g., pets) frequently trigger false positives; 2) Low-cost WiFi chipsets and heterogeneous hardware introduce inconsistencies in channel state information (CSI) measurements; 3) Motion interference in multi-user environments complicates occupant differentiation; 4) Computational constraints on edge devices and limited cloud transmission impede real-time processing. To address these challenges, we present a practical and scalable system, validated through comprehensive two-year evaluations involving 280 edge devices, across 16 scenarios, and over 4 million motion samples. Our solutions achieve an accuracy of 92.61% in diverse real-world homes while reducing false alarms due to non-human movements from 63.1% to 8.4% and lowering CSI transmission overhead by 99.72%. Notably, our system integrates sensing and communication, supporting simultaneous WiFi sensing and data transmission over home WiFi networks. While focused on home monitoring, our findings and strategies generalize to various WiFi sensing applications. By bridging the gaps between theoretical research and commercial deployment, this work offers practical insights for scaling WiFi sensing in real-world environments.
ASE: Practical Acoustic Speed Estimation Beyond Doppler via Sound Diffusion Field
Dec 28, 2024


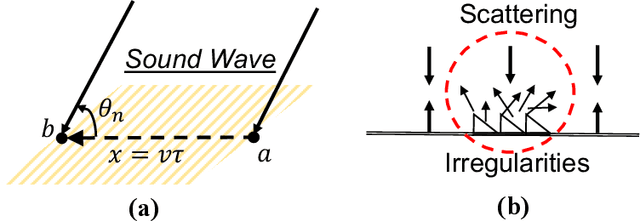
Passive human speed estimation plays a critical role in acoustic sensing. Despite extensive study, existing systems, however, suffer from various limitations: First, previous acoustic speed estimation exploits Doppler Frequency Shifts (DFS) created by moving targets and relies on microphone arrays, making them only capable of sensing the radial speed within a constrained distance. Second, the channel measurement rate proves inadequate to estimate high moving speeds. To overcome these issues, we present ASE, an accurate and robust Acoustic Speed Estimation system on a single commodity microphone. We model the sound propagation from a unique perspective of the acoustic diffusion field, and infer the speed from the acoustic spatial distribution, a completely different way of thinking about speed estimation beyond prior DFS-based approaches. We then propose a novel Orthogonal Time-Delayed Multiplexing (OTDM) scheme for acoustic channel estimation at a high rate that was previously infeasible, making it possible to estimate high speeds. We further develop novel techniques for motion detection and signal enhancement to deliver a robust and practical system. We implement and evaluate ASE through extensive real-world experiments. Our results show that ASE reliably tracks walking speed, independently of target location and direction, with a mean error of 0.13 m/s, a reduction of 2.5x from DFS, and a detection rate of 97.4% for large coverage, e.g., free walking in a 4m $\times$ 4m room. We believe ASE pushes acoustic speed estimation beyond the conventional DFS-based paradigm and will inspire exciting research in acoustic sensing.
Unfolding Target Detection with State Space Model
Oct 30, 2024



Target detection is a fundamental task in radar sensing, serving as the precursor to any further processing for various applications. Numerous detection algorithms have been proposed. Classical methods based on signal processing, e.g., the most widely used CFAR, are challenging to tune and sensitive to environmental conditions. Deep learning-based methods can be more accurate and robust, yet usually lack interpretability and physical relevance. In this paper, we introduce a novel method that combines signal processing and deep learning by unfolding the CFAR detector with a state space model architecture. By reserving the CFAR pipeline yet turning its sophisticated configurations into trainable parameters, our method achieves high detection performance without manual parameter tuning, while preserving model interpretability. We implement a lightweight model of only 260K parameters and conduct real-world experiments for human target detection using FMCW radars. The results highlight the remarkable performance of the proposed method, outperforming CFAR and its variants by 10X in detection rate and false alarm rate. Our code is open-sourced here: https://github.com/aiot-lab/NeuroDet.
USpeech: Ultrasound-Enhanced Speech with Minimal Human Effort via Cross-Modal Synthesis
Oct 29, 2024



Speech enhancement is crucial in human-computer interaction, especially for ubiquitous devices. Ultrasound-based speech enhancement has emerged as an attractive choice because of its superior ubiquity and performance. However, inevitable interference from unexpected and unintended sources during audio-ultrasound data acquisition makes existing solutions rely heavily on human effort for data collection and processing. This leads to significant data scarcity that limits the full potential of ultrasound-based speech enhancement. To address this, we propose USpeech, a cross-modal ultrasound synthesis framework for speech enhancement with minimal human effort. At its core is a two-stage framework that establishes correspondence between visual and ultrasonic modalities by leveraging audible audio as a bridge. This approach overcomes challenges from the lack of paired video-ultrasound datasets and the inherent heterogeneity between video and ultrasound data. Our framework incorporates contrastive video-audio pre-training to project modalities into a shared semantic space and employs an audio-ultrasound encoder-decoder for ultrasound synthesis. We then present a speech enhancement network that enhances speech in the time-frequency domain and recovers the clean speech waveform via a neural vocoder. Comprehensive experiments show USpeech achieves remarkable performance using synthetic ultrasound data comparable to physical data, significantly outperforming state-of-the-art ultrasound-based speech enhancement baselines. USpeech is open-sourced at https://github.com/aiot-lab/USpeech/.
RFBoost: Understanding and Boosting Deep WiFi Sensing via Physical Data Augmentation
Oct 04, 2024Deep learning shows promising performance in wireless sensing. However, deep wireless sensing (DWS) heavily relies on large datasets. Unfortunately, building comprehensive datasets for DWS is difficult and costly, because wireless data depends on environmental factors and cannot be labeled offline. Despite recent advances in few-shot/cross-domain learning, DWS is still facing data scarcity issues. In this paper, we investigate a distinct perspective of radio data augmentation (RDA) for WiFi sensing and present a data-space solution. Our key insight is that wireless signals inherently exhibit data diversity, contributing more information to be extracted for DWS. We present RFBoost, a simple and effective RDA framework encompassing novel physical data augmentation techniques. We implement RFBoost as a plug-and-play module integrated with existing deep models and evaluate it on multiple datasets. Experimental results demonstrate that RFBoost achieves remarkable average accuracy improvements of 5.4% on existing models without additional data collection or model modifications, and the best-boosted performance outperforms 11 state-of-the-art baseline models without RDA. RFBoost pioneers the study of RDA, an important yet currently underexplored building block for DWS, which we expect to become a standard DWS component of WiFi sensing and beyond. RFBoost is released at https://github.com/aiot-lab/RFBoost.
* Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 8, 2, Article 58 (June 2024), 26 pages
RF-Diffusion: Radio Signal Generation via Time-Frequency Diffusion
Apr 14, 2024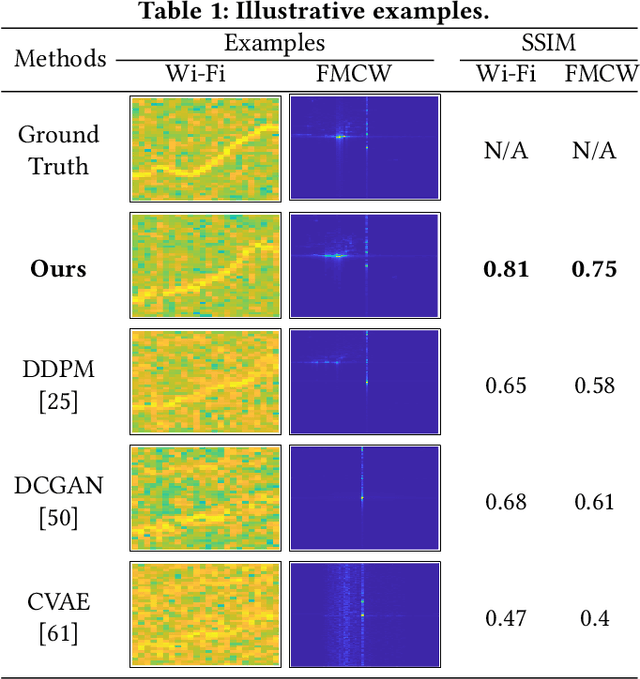
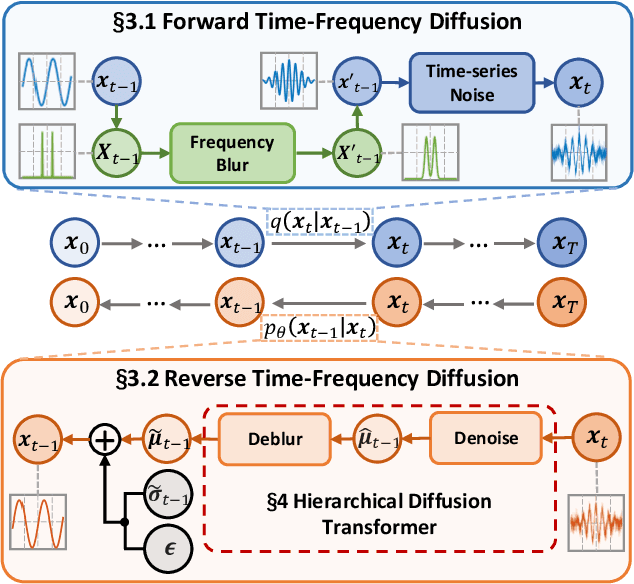
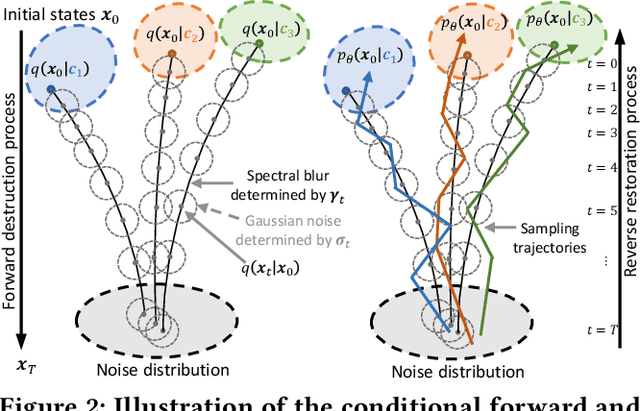
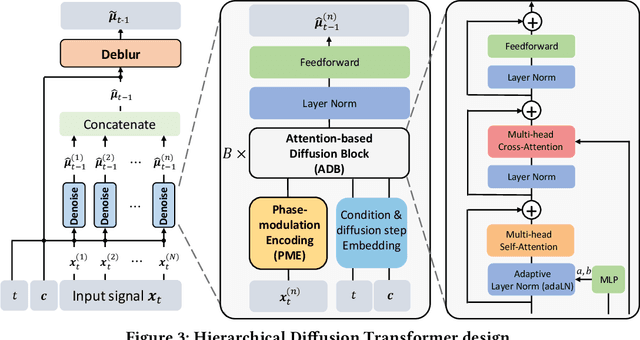
Along with AIGC shines in CV and NLP, its potential in the wireless domain has also emerged in recent years. Yet, existing RF-oriented generative solutions are ill-suited for generating high-quality, time-series RF data due to limited representation capabilities. In this work, inspired by the stellar achievements of the diffusion model in CV and NLP, we adapt it to the RF domain and propose RF-Diffusion. To accommodate the unique characteristics of RF signals, we first introduce a novel Time-Frequency Diffusion theory to enhance the original diffusion model, enabling it to tap into the information within the time, frequency, and complex-valued domains of RF signals. On this basis, we propose a Hierarchical Diffusion Transformer to translate the theory into a practical generative DNN through elaborated design spanning network architecture, functional block, and complex-valued operator, making RF-Diffusion a versatile solution to generate diverse, high-quality, and time-series RF data. Performance comparison with three prevalent generative models demonstrates the RF-Diffusion's superior performance in synthesizing Wi-Fi and FMCW signals. We also showcase the versatility of RF-Diffusion in boosting Wi-Fi sensing systems and performing channel estimation in 5G networks.
NeurIT: Pushing the Limit of Neural Inertial Tracking for Indoor Robotic IoT
Apr 13, 2024Inertial tracking is vital for robotic IoT and has gained popularity thanks to the ubiquity of low-cost Inertial Measurement Units (IMUs) and deep learning-powered tracking algorithms. Existing works, however, have not fully utilized IMU measurements, particularly magnetometers, nor maximized the potential of deep learning to achieve the desired accuracy. To enhance the tracking accuracy for indoor robotic applications, we introduce NeurIT, a sequence-to-sequence framework that elevates tracking accuracy to a new level. NeurIT employs a Time-Frequency Block-recurrent Transformer (TF-BRT) at its core, combining the power of recurrent neural network (RNN) and Transformer to learn representative features in both time and frequency domains. To fully utilize IMU information, we strategically employ body-frame differentiation of the magnetometer, which considerably reduces the tracking error. NeurIT is implemented on a customized robotic platform and evaluated in various indoor environments. Experimental results demonstrate that NeurIT achieves a mere 1-meter tracking error over a 300-meter distance. Notably, it significantly outperforms state-of-the-art baselines by 48.21% on unseen data. NeurIT also performs comparably to the visual-inertial approach (Tango Phone) in vision-favored conditions and surpasses it in plain environments. We believe NeurIT takes an important step forward toward practical neural inertial tracking for ubiquitous and scalable tracking of robotic things. NeurIT, including the source code and the dataset, is open-sourced here: https://github.com/NeurIT-Project/NeurIT.