 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadioSES: mmWave-Based Audioradio Speech Enhancement and Separation System
Paper and Code
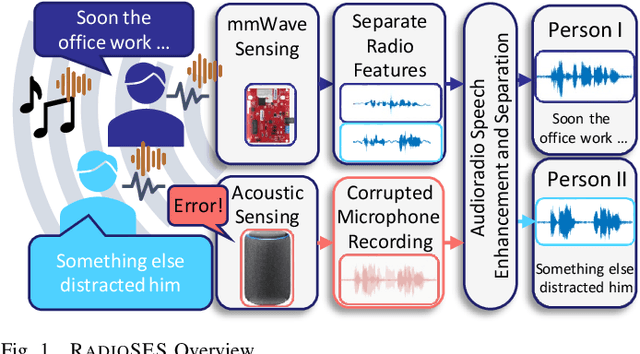
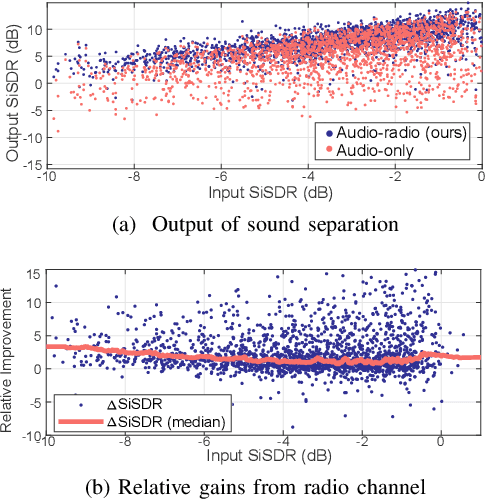

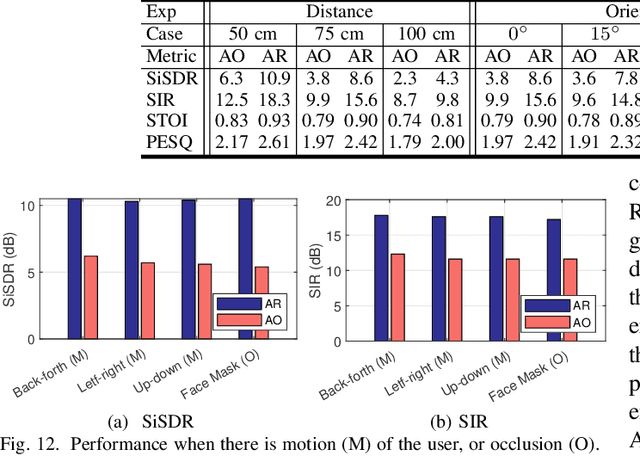
Speech enhancement and separation have been a long-standing problem, especially with the recent advances using a single microphone. Although microphones perform well in constrained settings, their performance for speech separation decreases in noisy conditions. In this work, we propose RadioSES, an audioradio speech enhancement and separation system that overcomes inherent problems in audio-only systems. By fusing a complementary radio modality, RadioSES can estimate the number of speakers, solve source association problem, separate and enhance noisy mixture speeches, and improve both intelligibility and perceptual quality. We perform millimeter-wave sensing to detect and localize speakers, and introduce an audioradio deep learning framework to fuse the separate radio features with the mixed audio features. Extensive experiments using commercial off-the-shelf devices show that RadioSES outperforms a variety of state-of-the-art baselines, with consistent performance gains in different environmental settings. Compared with the audiovisual methods, RadioSES provides similar improvements (e.g., ~3 dB gains in SiSDR), along with the benefits of lower computational complexity and being less privacy concerning.