 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadioSES: mmWave-Based Audioradio Speech Enhancement and Separation System
Apr 14, 2022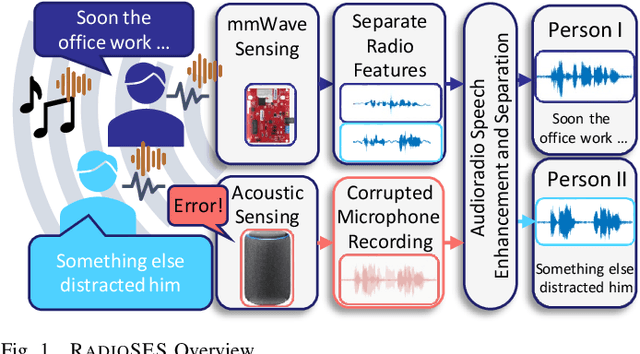
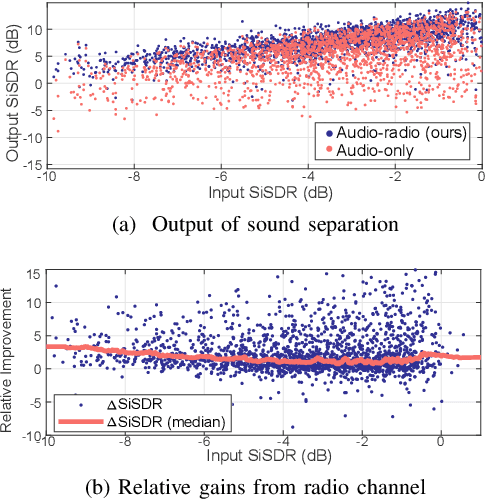

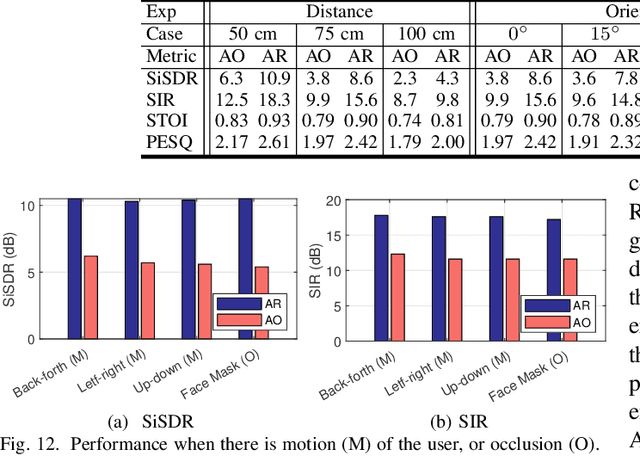
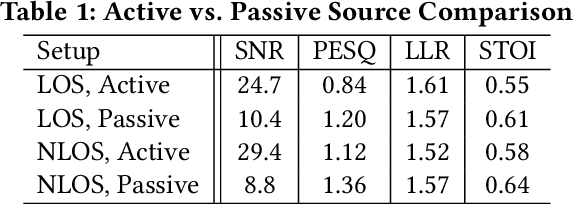
Speech enhancement and separation have been a long-standing problem, especially with the recent advances using a single microphone. Although microphones perform well in constrained settings, their performance for speech separation decreases in noisy conditions. In this work, we propose RadioSES, an audioradio speech enhancement and separation system that overcomes inherent problems in audio-only systems. By fusing a complementary radio modality, RadioSES can estimate the number of speakers, solve source association problem, separate and enhance noisy mixture speeches, and improve both intelligibility and perceptual quality. We perform millimeter-wave sensing to detect and localize speakers, and introduce an audioradio deep learning framework to fuse the separate radio features with the mixed audio features. Extensive experiments using commercial off-the-shelf devices show that RadioSES outperforms a variety of state-of-the-art baselines, with consistent performance gains in different environmental settings. Compared with the audiovisual methods, RadioSES provides similar improvements (e.g., ~3 dB gains in SiSDR), along with the benefits of lower computational complexity and being less privacy concerning.
RadioMic: Sound Sensing via mmWave Signals
Aug 06, 2021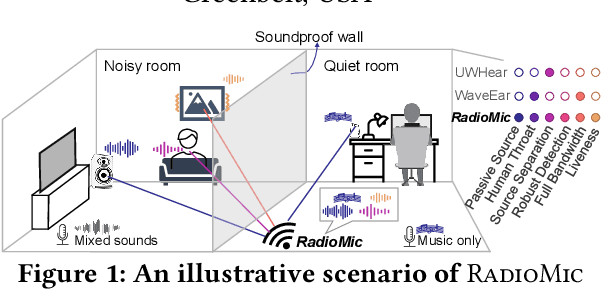
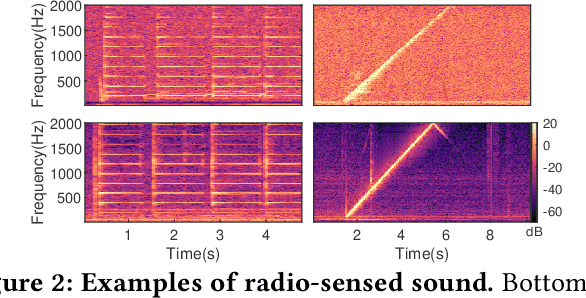

Voice interfaces has become an integral part of our lives, with the proliferation of smart devices. Today, IoT devices mainly rely on microphones to sense sound. Microphones, however, have fundamental limitations, such as weak source separation, limited range in the presence of acoustic insulation, and being prone to multiple side-channel attacks. In this paper, we propose RadioMic, a radio-based sound sensing system to mitigate these issues and enrich sound applications. RadioMic constructs sound based on tiny vibrations on active sources (e.g., a speaker or human throat) or object surfaces (e.g., paper bag), and can work through walls, even a soundproof one. To convert the extremely weak sound vibration in the radio signals into sound signals, RadioMic introduces radio acoustics, and presents training-free approaches for robust sound detection and high-fidelity sound recovery. It then exploits a neural network to further enhance the recovered sound by expanding the recoverable frequencies and reducing the noises. RadioMic translates massive online audios to synthesized data to train the network, and thus minimizes the need of RF data. We thoroughly evaluate RadioMic under different scenarios using a commodity mmWave radar. The results show RadioMic outperforms the state-of-the-art systems significantly. We believe RadioMic provides new horizons for sound sensing and inspires attractive sensing capabilities of mmWave sensing devices