 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCInfer: An Efficient Inference System via Error Compensation for Resource-Constrained Devices
May 07, 2026LLMs often struggle with memory-constrained deployment on consumer-grade hardware due to their massive parameter sizes. While existing solutions such as model compression and offloading improve deployment feasibility, they often suffer from substantial accuracy degradation or severe throughput bottlenecks. Recent error compensation methods recover accuracy through auxiliary LoRA-style branches, and we observe that these branches are inherently amenable to offloading: they require substantial parameter storage but access only a small subset of compensation parameters during each inference step. Motivated by this opportunity, we propose HCInfer, a heterogeneous inference system that offloads residual compensation to the CPU while executing the compressed backbone on the GPU, and further introduces an asynchronous compensation pipeline and sensitivity-aware dynamic rank allocation to hide compensation overhead and maximize accuracy recovery. Experimental results show that HCInfer achieves a maximum accuracy improvement of 5.2% on downstream tasks compared to compression model and sustaining a maximum speedup of 10.4x compared to full-precision model.
Reasoning with Autoregressive-Diffusion Collaborative Thoughts
Feb 02, 2026Autoregressive and diffusion models represent two complementary generative paradigms. Autoregressive models excel at sequential planning and constraint composition, yet struggle with tasks that require explicit spatial or physical grounding. Diffusion models, in contrast, capture rich spatial structure through high-dimensional generation, but lack the stepwise logical control needed to satisfy complex, multi-stage constraints or to reliably identify and correct errors. We introduce Collaborative Thoughts, a unified collaborative framework that enables autoregressive and diffusion models to reason and generate jointly through a closed-loop interaction. In Collaborative Thoughts, autoregressive models perform structured planning and constraint management, diffusion models instantiate these constraints as intermediate visual thoughts, and a vision-based critic module evaluates whether the visual thoughts satisfy the intended structural and physical requirements. This feedback is then used to iteratively refine subsequent planning and generation steps, mitigating error propagation across modalities. Importantly, Collaborative Thoughts uses the same collaborative loop regardless of whether the task is autoregressive question answering or diffusion-based visual generation. Through representative examples, we illustrate how Collaborative Thoughts can improve the reliability of spatial reasoning and the controllability of generation.
QUIDS: Quality-informed Incentive-driven Multi-agent Dispatching System for Mobile Crowdsensing
Dec 18, 2025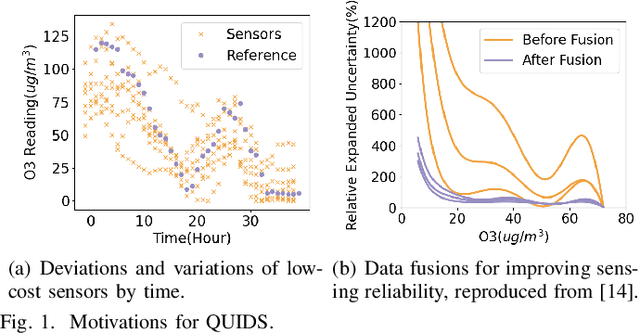
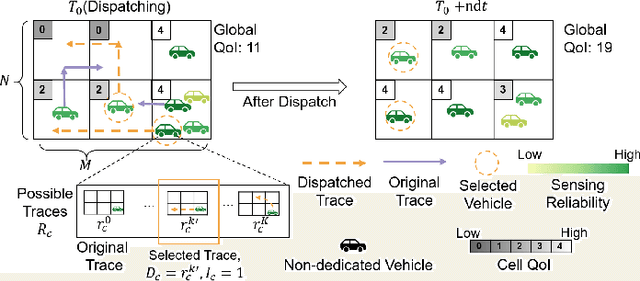
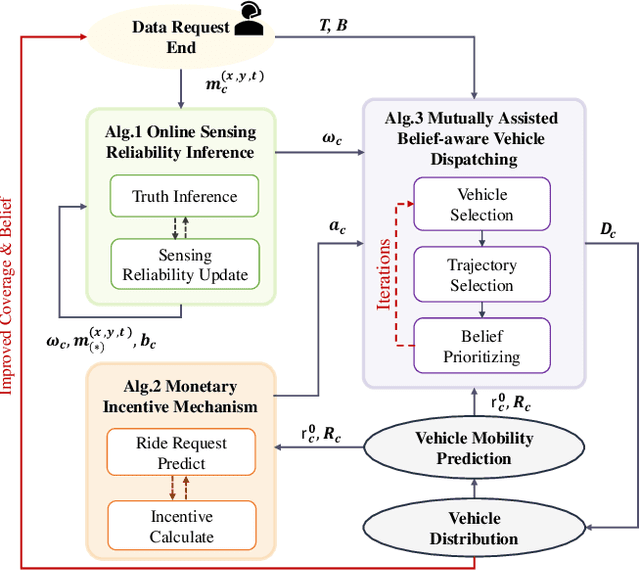

This paper addresses the challenge of achieving optimal Quality of Information (QoI) in non-dedicated vehicular mobile crowdsensing (NVMCS) systems. The key obstacles are the interrelated issues of sensing coverage, sensing reliability, and the dynamic participation of vehicles. To tackle these, we propose QUIDS, a QUality-informed Incentive-driven multi-agent Dispatching System, which ensures high sensing coverage and reliability under budget constraints. QUIDS introduces a novel metric, Aggregated Sensing Quality (ASQ), to quantitatively capture QoI by integrating both coverage and reliability. We also develop a Mutually Assisted Belief-aware Vehicle Dispatching algorithm that estimates sensing reliability and allocates incentives under uncertainty, further improving ASQ. Evaluation using real-world data from a metropolitan NVMCS deployment shows QUIDS improves ASQ by 38% over non-dispatching scenarios and by 10% over state-of-the-art methods. It also reduces reconstruction map errors by 39-74% across algorithms. By jointly optimizing coverage and reliability via a quality-informed incentive mechanism, QUIDS enables low-cost, high-quality urban monitoring without dedicated infrastructure, applicable to smart-city scenarios like traffic and environmental sensing.
Stealth Fine-Tuning: Efficiently Breaking Alignment in RVLMs Using Self-Generated CoT
Nov 18, 2025Reasoning-augmented Vision-Language Models (RVLMs) rely on safety alignment to prevent harmful behavior, yet their exposed chain-of-thought (CoT) traces introduce new attack surfaces. In this work, we find that the safety alignment of RVLMs can be easily break through a novel attack method termed \textbf{Stealth Fine-Tuning}. Our method elicits harmful reasoning traces through \textbf{segment-level interference} and reuses the self-generated outputs as supervised fine-tuning data. Through a \textbf{turn-based weighted} loss design, yielding a lightweight, distribution-consistent finetuning method. In our experiment, with only 499 samples and under 3 hours on a single A100 (QLoRA), Stealth Fine-Tuning outperforms IDEATOR by 38.52\% ASR while preserving general reasoning ability, as the tuned model retains the original representation distribution. Experiments on AdvBench and several general benchmarks demonstrate that Stealth Fine-Tuning is a low-cost and highly effective way to bypass alignment defenses. \textcolor{red}{\textbf{Disclaimer: This paper contains content that may be disturbing or offensive.}}
Count Every Rotation and Every Rotation Counts: Exploring Drone Dynamics via Propeller Sensing
Nov 17, 2025As drone-based applications proliferate, paramount contactless sensing of airborne drones from the ground becomes indispensable. This work demonstrates concentrating on propeller rotational speed will substantially improve drone sensing performance and proposes an event-camera-based solution, \sysname. \sysname features two components: \textit{Count Every Rotation} achieves accurate, real-time propeller speed estimation by mitigating ultra-high sensitivity of event cameras to environmental noise. \textit{Every Rotation Counts} leverages these speeds to infer both internal and external drone dynamics. Extensive evaluations in real-world drone delivery scenarios show that \sysname achieves a sensing latency of 3$ms$ and a rotational speed estimation error of merely 0.23\%. Additionally, \sysname infers drone flight commands with 96.5\% precision and improves drone tracking accuracy by over 22\% when combined with other sensing modalities. \textit{ Demo: {\color{blue}https://eventpro25.github.io/EventPro/.} }
Enabling High-Frequency Cross-Modality Visual Positioning Service for Accurate Drone Landing
Oct 01, 2025After years of growth, drone-based delivery is transforming logistics. At its core, real-time 6-DoF drone pose tracking enables precise flight control and accurate drone landing. With the widespread availability of urban 3D maps, the Visual Positioning Service (VPS), a mobile pose estimation system, has been adapted to enhance drone pose tracking during the landing phase, as conventional systems like GPS are unreliable in urban environments due to signal attenuation and multi-path propagation. However, deploying the current VPS on drones faces limitations in both estimation accuracy and efficiency. In this work, we redesign drone-oriented VPS with the event camera and introduce EV-Pose to enable accurate, high-frequency 6-DoF pose tracking for accurate drone landing. EV-Pose introduces a spatio-temporal feature-instructed pose estimation module that extracts a temporal distance field to enable 3D point map matching for pose estimation; and a motion-aware hierarchical fusion and optimization scheme to enhance the above estimation in accuracy and efficiency, by utilizing drone motion in the \textit{early stage} of event filtering and the \textit{later stage} of pose optimization. Evaluation shows that EV-Pose achieves a rotation accuracy of 1.34$\degree$ and a translation accuracy of 6.9$mm$ with a tracking latency of 10.08$ms$, outperforming baselines by $>$50\%, \tmcrevise{thus enabling accurate drone landings.} Demo: https://ev-pose.github.io/
Generative AI Meets Wireless Sensing: Towards Wireless Foundation Model
Sep 18, 2025



Generative Artificial Intelligence (GenAI) has made significant advancements in fields such as computer vision (CV) and natural language processing (NLP), demonstrating its capability to synthesize high-fidelity data and improve generalization. Recently, there has been growing interest in integrating GenAI into wireless sensing systems. By leveraging generative techniques such as data augmentation, domain adaptation, and denoising, wireless sensing applications, including device localization, human activity recognition, and environmental monitoring, can be significantly improved. This survey investigates the convergence of GenAI and wireless sensing from two complementary perspectives. First, we explore how GenAI can be integrated into wireless sensing pipelines, focusing on two modes of integration: as a plugin to augment task-specific models and as a solver to directly address sensing tasks. Second, we analyze the characteristics of mainstream generative models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models, and discuss their applicability and unique advantages across various wireless sensing tasks. We further identify key challenges in applying GenAI to wireless sensing and outline a future direction toward a wireless foundation model: a unified, pre-trained design capable of scalable, adaptable, and efficient signal understanding across diverse sensing tasks.
SynSeg: Feature Synergy for Multi-Category Contrastive Learning in Open-Vocabulary Semantic Segmentation
Aug 08, 2025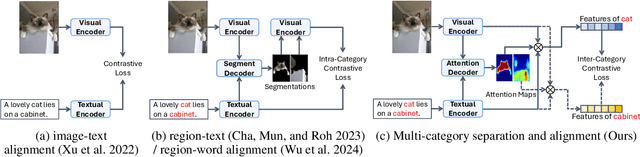
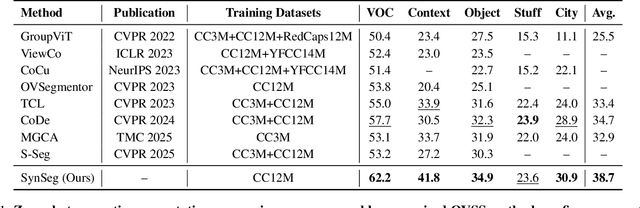
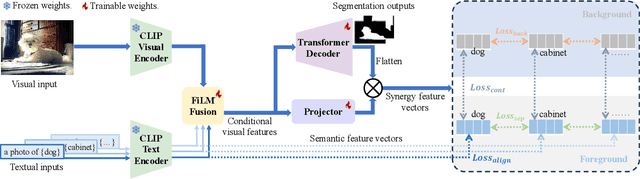
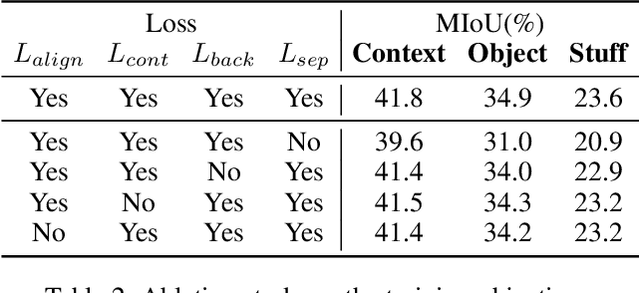
Semantic segmentation in open-vocabulary scenarios presents significant challenges due to the wide range and granularity of semantic categories. Existing weakly-supervised methods often rely on category-specific supervision and ill-suited feature construction methods for contrastive learning, leading to semantic misalignment and poor performance. In this work, we propose a novel weakly-supervised approach, SynSeg, to address the challenges. SynSeg performs Multi-Category Contrastive Learning (MCCL) as a stronger training signal with a new feature reconstruction framework named Feature Synergy Structure (FSS). Specifically, MCCL strategy robustly combines both intra- and inter-category alignment and separation in order to make the model learn the knowledge of correlations from different categories within the same image. Moreover, FSS reconstructs discriminative features for contrastive learning through prior fusion and semantic-activation-map enhancement, effectively avoiding the foreground bias introduced by the visual encoder. In general, SynSeg effectively improves the abilities in semantic localization and discrimination under weak supervision. Extensive experiments on benchmarks demonstrate that our method outperforms state-of-the-art (SOTA) performance. For instance, SynSeg achieves higher accuracy than SOTA baselines by 4.5\% on VOC, 8.9\% on Context, 2.6\% on Object and 2.0\% on City.
AdaptInfer: Adaptive Token Pruning for Vision-Language Model Inference with Dynamical Text Guidance
Aug 08, 2025Vision-language models (VLMs) have achieved impressive performance on multimodal reasoning tasks such as visual question answering (VQA), but their inference cost remains a significant challenge due to the large number of vision tokens processed during the prefill stage. Existing pruning methods often rely on directly using the attention patterns or static text prompt guidance, failing to exploit the dynamic internal signals generated during inference. To address these issues, we propose AdaptInfer, a plug-and-play framework for adaptive vision token pruning in VLMs. First, we introduce a fine-grained, dynamic text-guided pruning mechanism that reuses layer-wise text-to-text attention maps to construct soft priors over text-token importance, allowing more informed scoring of vision tokens at each stage. Second, we perform an offline analysis of cross-modal attention shifts and identify consistent inflection locations in inference, which inspire us to propose a more principled and efficient pruning schedule. Our method is lightweight and plug-and-play, also generalizable across multi-modal tasks. Experimental results have verified the effectiveness of the proposed method. For example, it reduces CUDA latency by 61.3\% while maintaining an average accuracy of 92.9\% on vanilla LLaVA-1.5-7B. Under the same token budget, AdaptInfer surpasses SOTA in accuracy.
Towards Mobile Sensing with Event Cameras on High-mobility Resource-constrained Devices: A Survey
Mar 29, 2025With the increasing complexity of mobile device applications, these devices are evolving toward high mobility. This shift imposes new demands on mobile sensing, particularly in terms of achieving high accuracy and low latency. Event-based vision has emerged as a disruptive paradigm, offering high temporal resolution, low latency, and energy efficiency, making it well-suited for high-accuracy and low-latency sensing tasks on high-mobility platforms. However, the presence of substantial noisy events, the lack of inherent semantic information, and the large data volume pose significant challenges for event-based data processing on resource-constrained mobile devices. This paper surveys the literature over the period 2014-2024, provides a comprehensive overview of event-based mobile sensing systems, covering fundamental principles, event abstraction methods, algorithmic advancements, hardware and software acceleration strategies. We also discuss key applications of event cameras in mobile sensing, including visual odometry, object tracking, optical flow estimation, and 3D reconstruction, while highlighting the challenges associated with event data processing, sensor fusion, and real-time deployment. Furthermore, we outline future research directions, such as improving event camera hardware with advanced optics, leveraging neuromorphic computing for efficient processing, and integrating bio-inspired algorithms to enhance perception. To support ongoing research, we provide an open-source \textit{Online Sheet} with curated resources and recent developments. We hope this survey serves as a valuable reference, facilitating the adoption of event-based vision across diverse applications.