 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGS: Color-Adaptive Volumetric Video Streaming with Dynamic 3D Gaussian Splatting
May 10, 2026Volumetric video (VV) streaming enables real-time, immersive access to remote 3D environments, powering telepresence, ecological monitoring, and robotic teleoperation. These applications turn VV streaming into a real-time interface to remote physical environments, imposing new system-level demands for photorealistic scene representation, low-latency interaction, and robust performance under heterogeneous networks. 3D Gaussian Splatting (3DGS) has been widely used for real-time photorealistic rendering, offering superior visual quality and rendering performance, but it faces challenges due to bandwidth consumption. Furthermore, as the foundation of adaptive VV streaming, existing Levels of Detail (LoD) methods based on density are not well-suited to Gaussian representations, leading to visible gaps and severe quality degradation. Recent studies have also explored attribute compression techniques to reduce bandwidth consumption. Our preliminary studies reveal that aggressive attribute compression primarily causes color distortion, which can be effectively corrected in the rendered image using a reference image. Motivated by these findings, we propose a novel Color-Adaptive scheme for adaptive VV streaming that uses vector quantization (VQ) to establish LoDs and correct color distortions with low-resolution reference images. We further present CAGS, an adaptive VV streaming system compatible with diverse Gaussian representations, which integrates the Color-Adaptive scheme by rendering reference images on the streaming server and performing color restoration on the client. Extensive experiments on our prototype system demonstrate that CAGS outperforms the existing adaptive streaming systems in PSNR by 5$\sim$20 dB under fluctuating bandwidth, operates significantly faster than existing scalable Gaussian compression methods, and generalizes across different Gaussian representations.
* SIGGRAPH 2026 Conference Paper. Code is available at https://github.com/yindaheng98/ColorAdaptiveGaussianSplatting
TrackerSplat: Exploiting Point Tracking for Fast and Robust Dynamic 3D Gaussians Reconstruction
Apr 02, 2026Recent advancements in 3D Gaussian Splatting (3DGS) have demonstrated its potential for efficient and photorealistic 3D reconstructions, which is crucial for diverse applications such as robotics and immersive media. However, current Gaussian-based methods for dynamic scene reconstruction struggle with large inter-frame displacements, leading to artifacts and temporal inconsistencies under fast object motions. To address this, we introduce \textit{TrackerSplat}, a novel method that integrates advanced point tracking methods to enhance the robustness and scalability of 3DGS for dynamic scene reconstruction. TrackerSplat utilizes off-the-shelf point tracking models to extract pixel trajectories and triangulate per-view pixel trajectories onto 3D Gaussians to guide the relocation, rotation, and scaling of Gaussians before training. This strategy effectively handles large displacements between frames, dramatically reducing the fading and recoloring artifacts prevalent in prior methods. By accurately positioning Gaussians prior to gradient-based optimization, TrackerSplat overcomes the quality degradation associated with large frame gaps when processing multiple adjacent frames in parallel across multiple devices, thereby boosting reconstruction throughput while preserving rendering quality. Experiments on real-world datasets confirm the robustness of TrackerSplat in challenging scenarios with significant displacements, achieving superior throughput under parallel settings and maintaining visual quality compared to baselines. The code is available at https://github.com/yindaheng98/TrackerSplat.
* 11 pages, 6 figures
ViTMAlis: Towards Latency-Critical Mobile Video Analytics with Vision Transformers
Jan 29, 2026Edge-assisted mobile video analytics (MVA) applications are increasingly shifting from using vision models based on convolutional neural networks (CNNs) to those built on vision transformers (ViTs) to leverage their superior global context modeling and generalization capabilities. However, deploying these advanced models in latency-critical MVA scenarios presents significant challenges. Unlike traditional CNN-based offloading paradigms where network transmission is the primary bottleneck, ViT-based systems are constrained by substantial inference delays, particularly for dense prediction tasks where the need for high-resolution inputs exacerbates the inherent quadratic computational complexity of ViTs. To address these challenges, we propose a dynamic mixed-resolution inference strategy tailored for ViT-backboned dense prediction models, enabling flexible runtime trade-offs between speed and accuracy. Building on this, we introduce ViTMAlis, a ViT-native device-to-edge offloading framework that dynamically adapts to network conditions and video content to jointly reduce transmission and inference delays. We implement a fully functional prototype of ViTMAlis on commodity mobile and edge devices. Extensive experiments demonstrate that, compared to state-of-the-art accuracy-centric, content-aware, and latency-adaptive baselines, ViTMAlis significantly reduces end-to-end offloading latency while improving user-perceived rendering accuracy, providing a practical foundation for next-generation mobile intelligence.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
Self-Supervised Compression and Artifact Correction for Streaming Underwater Imaging Sonar
Nov 17, 2025Real-time imaging sonar has become an important tool for underwater monitoring in environments where optical sensing is unreliable. Its broader use is constrained by two coupled challenges: highly limited uplink bandwidth and severe sonar-specific artifacts (speckle, motion blur, reverberation, acoustic shadows) that affect up to 98% of frames. We present SCOPE, a self-supervised framework that jointly performs compression and artifact correction without clean-noise pairs or synthetic assumptions. SCOPE combines (i) Adaptive Codebook Compression (ACC), which learns frequency-encoded latent representations tailored to sonar, with (ii) Frequency-Aware Multiscale Segmentation (FAMS), which decomposes frames into low-frequency structure and sparse high-frequency dynamics while suppressing rapidly fluctuating artifacts. A hedging training strategy further guides frequency-aware learning using low-pass proxy pairs generated without labels. Evaluated on months of in-situ ARIS sonar data, SCOPE achieves a structural similarity index (SSIM) of 0.77, representing a 40% improvement over prior self-supervised denoising baselines, at bitrates down to <= 0.0118 bpp. It reduces uplink bandwidth by more than 80% while improving downstream detection. The system runs in real time, with 3.1 ms encoding on an embedded GPU and 97 ms full multi-layer decoding on the server end. SCOPE has been deployed for months in three Pacific Northwest rivers to support real-time salmon enumeration and environmental monitoring in the wild. Results demonstrate that learning frequency-structured latents enables practical, low-bitrate sonar streaming with preserved signal details under real-world deployment conditions.
Generative Flow Networks for Personalized Multimedia Systems: A Case Study on Short Video Feeds
Aug 23, 2025Multimedia systems underpin modern digital interactions, facilitating seamless integration and optimization of resources across diverse multimedia applications. To meet growing personalization demands, multimedia systems must efficiently manage competing resource needs, adaptive content, and user-specific data handling. This paper introduces Generative Flow Networks (GFlowNets, GFNs) as a brave new framework for enabling personalized multimedia systems. By integrating multi-candidate generative modeling with flow-based principles, GFlowNets offer a scalable and flexible solution for enhancing user-specific multimedia experiences. To illustrate the effectiveness of GFlowNets, we focus on short video feeds, a multimedia application characterized by high personalization demands and significant resource constraints, as a case study. Our proposed GFlowNet-based personalized feeds algorithm demonstrates superior performance compared to traditional rule-based and reinforcement learning methods across critical metrics, including video quality, resource utilization efficiency, and delivery cost. Moreover, we propose a unified GFlowNet-based framework generalizable to other multimedia systems, highlighting its adaptability and wide-ranging applicability. These findings underscore the potential of GFlowNets to advance personalized multimedia systems by addressing complex optimization challenges and supporting sophisticated multimedia application scenarios.
Generative AI for Multimedia Communication: Recent Advances, An Information-Theoretic Framework, and Future Opportunities
Aug 23, 2025Recent breakthroughs in generative artificial intelligence (AI) are transforming multimedia communication. This paper systematically reviews key recent advancements across generative AI for multimedia communication, emphasizing transformative models like diffusion and transformers. However, conventional information-theoretic frameworks fail to address semantic fidelity, critical to human perception. We propose an innovative semantic information-theoretic framework, introducing semantic entropy, mutual information, channel capacity, and rate-distortion concepts specifically adapted to multimedia applications. This framework redefines multimedia communication from purely syntactic data transmission to semantic information conveyance. We further highlight future opportunities and critical research directions. We chart a path toward robust, efficient, and semantically meaningful multimedia communication systems by bridging generative AI innovations with information theory. This exploratory paper aims to inspire a semantic-first paradigm shift, offering a fresh perspective with significant implications for future multimedia research.
OmniSense: Towards Edge-Assisted Online Analytics for 360-Degree Videos
Aug 19, 2025With the reduced hardware costs of omnidirectional cameras and the proliferation of various extended reality applications, more and more $360^\circ$ videos are being captured. To fully unleash their potential, advanced video analytics is expected to extract actionable insights and situational knowledge without blind spots from the videos. In this paper, we present OmniSense, a novel edge-assisted framework for online immersive video analytics. OmniSense achieves both low latency and high accuracy, combating the significant computation and network resource challenges of analyzing $360^\circ$ videos. Motivated by our measurement insights into $360^\circ$ videos, OmniSense introduces a lightweight spherical region of interest (SRoI) prediction algorithm to prune redundant information in $360^\circ$ frames. Incorporating the video content and network dynamics, it then smartly scales vision models to analyze the predicted SRoIs with optimized resource utilization. We implement a prototype of OmniSense with commodity devices and evaluate it on diverse real-world collected $360^\circ$ videos. Extensive evaluation results show that compared to resource-agnostic baselines, it improves the accuracy by $19.8\%$ -- $114.6\%$ with similar end-to-end latencies. Meanwhile, it hits $2.0\times$ -- $2.4\times$ speedups while keeping the accuracy on par with the highest accuracy of baselines.
Exploring Multimodal Foundation AI and Expert-in-the-Loop for Sustainable Management of Wild Salmon Fisheries in Indigenous Rivers
May 10, 2025


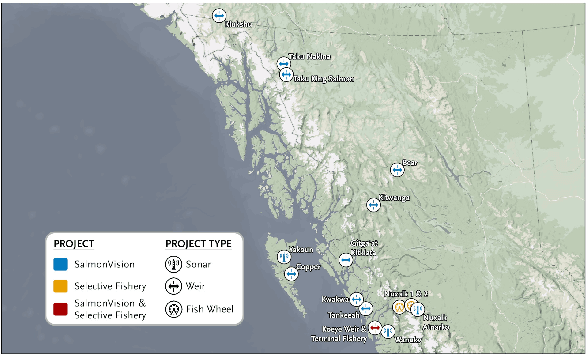
Wild salmon are essential to the ecological, economic, and cultural sustainability of the North Pacific Rim. Yet climate variability, habitat loss, and data limitations in remote ecosystems that lack basic infrastructure support pose significant challenges to effective fisheries management. This project explores the integration of multimodal foundation AI and expert-in-the-loop frameworks to enhance wild salmon monitoring and sustainable fisheries management in Indigenous rivers across Pacific Northwest. By leveraging video and sonar-based monitoring, we develop AI-powered tools for automated species identification, counting, and length measurement, reducing manual effort, expediting delivery of results, and improving decision-making accuracy. Expert validation and active learning frameworks ensure ecological relevance while reducing annotation burdens. To address unique technical and societal challenges, we bring together a cross-domain, interdisciplinary team of university researchers, fisheries biologists, Indigenous stewardship practitioners, government agencies, and conservation organizations. Through these collaborations, our research fosters ethical AI co-development, open data sharing, and culturally informed fisheries management.
Towards Edge General Intelligence via Large Language Models: Opportunities and Challenges
Oct 16, 2024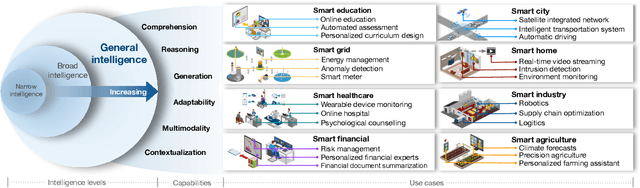
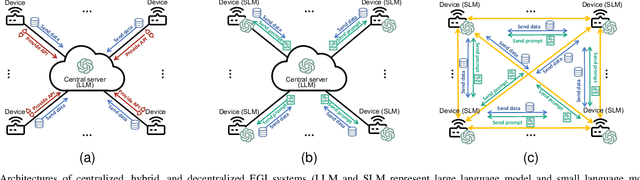
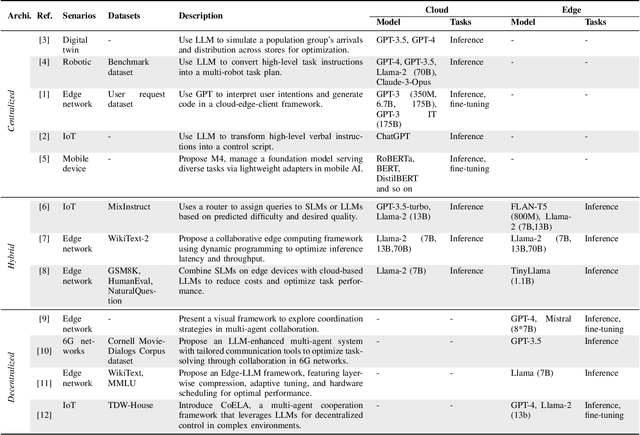
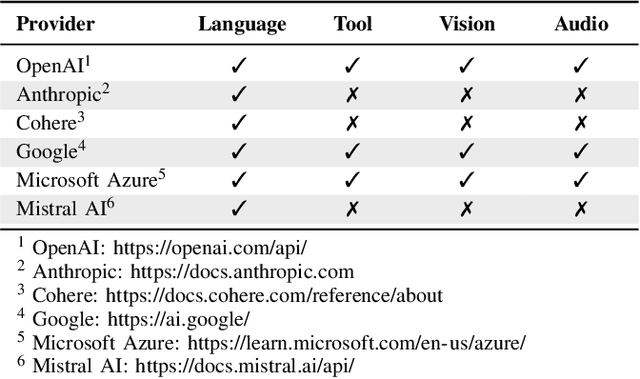
Edge Intelligence (EI) has been instrumental in delivering real-time, localized services by leveraging the computational capabilities of edge networks. The integration of Large Language Models (LLMs) empowers EI to evolve into the next stage: Edge General Intelligence (EGI), enabling more adaptive and versatile applications that require advanced understanding and reasoning capabilities. However, systematic exploration in this area remains insufficient. This survey delineates the distinctions between EGI and traditional EI, categorizing LLM-empowered EGI into three conceptual systems: centralized, hybrid, and decentralized. For each system, we detail the framework designs and review existing implementations. Furthermore, we evaluate the performance and throughput of various Small Language Models (SLMs) that are more suitable for development on edge devices. This survey provides researchers with a comprehensive vision of EGI, offering insights into its vast potential and establishing a foundation for future advancements in this rapidly evolving field.