 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoteIt: A System Converting Instructional Videos to Interactable Notes Through Multimodal Video Understanding
Aug 20, 2025



Users often take notes for instructional videos to access key knowledge later without revisiting long videos. Automated note generation tools enable users to obtain informative notes efficiently. However, notes generated by existing research or off-the-shelf tools fail to preserve the information conveyed in the original videos comprehensively, nor can they satisfy users' expectations for diverse presentation formats and interactive features when using notes digitally. In this work, we present NoteIt, a system, which automatically converts instructional videos to interactable notes using a novel pipeline that faithfully extracts hierarchical structure and multimodal key information from videos. With NoteIt's interface, users can interact with the system to further customize the content and presentation formats of the notes according to their preferences. We conducted both a technical evaluation and a comparison user study (N=36). The solid performance in objective metrics and the positive user feedback demonstrated the effectiveness of the pipeline and the overall usability of NoteIt. Project website: https://zhaorunning.github.io/NoteIt/
Holistic Tokenizer for Autoregressive Image Generation
Jul 03, 2025The vanilla autoregressive image generation model generates visual tokens in a step-by-step fashion, which limits the ability to capture holistic relationships among token sequences. Moreover, most visual tokenizers map local image patches into latent tokens, leading to limited global information. To address this, we introduce \textit{Hita}, a novel image tokenizer for autoregressive (AR) image generation. It introduces a holistic-to-local tokenization scheme with learnable holistic queries and local patch tokens. Besides, Hita incorporates two key strategies for improved alignment with the AR generation process: 1) it arranges a sequential structure with holistic tokens at the beginning followed by patch-level tokens while using causal attention to maintain awareness of previous tokens; and 2) before feeding the de-quantized tokens into the decoder, Hita adopts a lightweight fusion module to control information flow to prioritize holistic tokens. Extensive experiments show that Hita accelerates the training speed of AR generators and outperforms those trained with vanilla tokenizers, achieving \textbf{2.59 FID} and \textbf{281.9 IS} on the ImageNet benchmark. A detailed analysis of the holistic representation highlights its ability to capture global image properties such as textures, materials, and shapes. Additionally, Hita also demonstrates effectiveness in zero-shot style transfer and image in-painting. The code is available at \href{https://github.com/CVMI-Lab/Hita}{https://github.com/CVMI-Lab/Hita}
Multi-GraspLLM: A Multimodal LLM for Multi-Hand Semantic Guided Grasp Generation
Dec 11, 2024


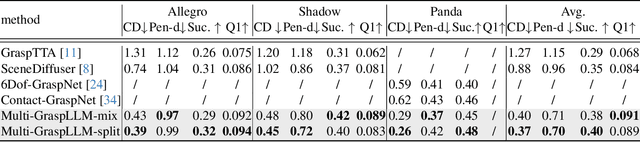
Multi-hand semantic grasp generation aims to generate feasible and semantically appropriate grasp poses for different robotic hands based on natural language instructions. Although the task is highly valuable, due to the lack of multi-hand grasp datasets with fine-grained contact description between robotic hands and objects, it is still a long-standing difficult task. In this paper, we present Multi-GraspSet, the first large-scale multi-hand grasp dataset with automatically contact annotations. Based on Multi-GraspSet, we propose Multi-GraspLLM, a unified language-guided grasp generation framework. It leverages large language models (LLM) to handle variable-length sequences, generating grasp poses for diverse robotic hands in a single unified architecture. Multi-GraspLLM first aligns the encoded point cloud features and text features into a unified semantic space. It then generates grasp bin tokens which are subsequently converted into grasp pose for each robotic hand via hand-aware linear mapping. The experimental results demonstrate that our approach significantly outperforms existing methods on Multi-GraspSet. More information can be found on our project page https://multi-graspllm.github.io.
Towards Edge General Intelligence via Large Language Models: Opportunities and Challenges
Oct 16, 2024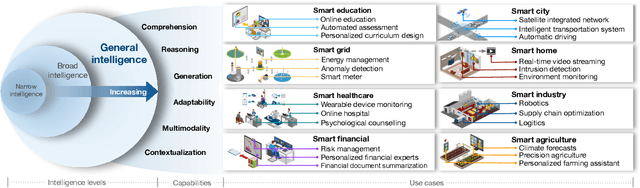
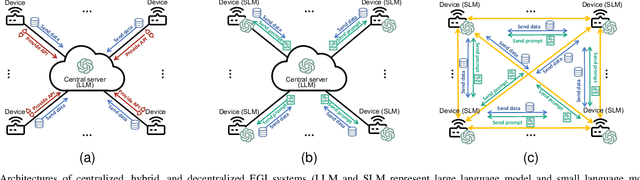
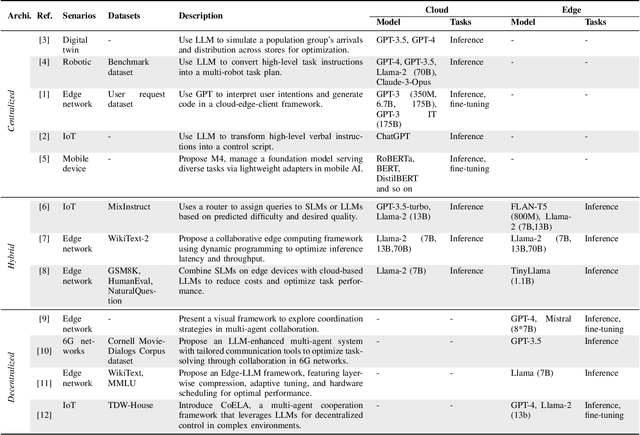
Edge Intelligence (EI) has been instrumental in delivering real-time, localized services by leveraging the computational capabilities of edge networks. The integration of Large Language Models (LLMs) empowers EI to evolve into the next stage: Edge General Intelligence (EGI), enabling more adaptive and versatile applications that require advanced understanding and reasoning capabilities. However, systematic exploration in this area remains insufficient. This survey delineates the distinctions between EGI and traditional EI, categorizing LLM-empowered EGI into three conceptual systems: centralized, hybrid, and decentralized. For each system, we detail the framework designs and review existing implementations. Furthermore, we evaluate the performance and throughput of various Small Language Models (SLMs) that are more suitable for development on edge devices. This survey provides researchers with a comprehensive vision of EGI, offering insights into its vast potential and establishing a foundation for future advancements in this rapidly evolving field.
SegGrasp: Zero-Shot Task-Oriented Grasping via Semantic and Geometric Guided Segmentation
Oct 11, 2024



Task-oriented grasping, which involves grasping specific parts of objects based on their functions, is crucial for developing advanced robotic systems capable of performing complex tasks in dynamic environments. In this paper, we propose a training-free framework that incorporates both semantic and geometric priors for zero-shot task-oriented grasp generation. The proposed framework, SegGrasp, first leverages the vision-language models like GLIP for coarse segmentation. It then uses detailed geometric information from convex decomposition to improve segmentation quality through a fusion policy named GeoFusion. An effective grasp pose can be generated by a grasping network with improved segmentation. We conducted the experiments on both segmentation benchmark and real-world robot grasping. The experimental results show that SegGrasp surpasses the baseline by more than 15\% in grasp and segmentation performance.
Can 3D Vision-Language Models Truly Understand Natural Language?
Mar 28, 2024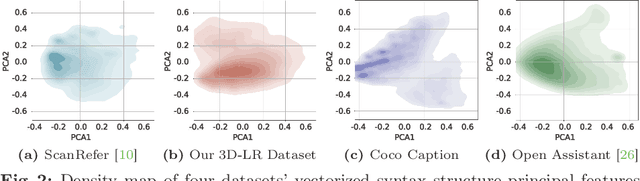
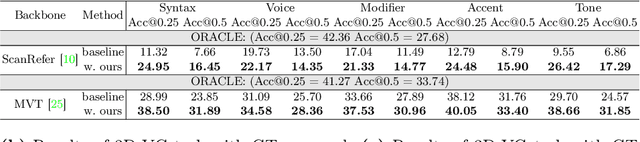
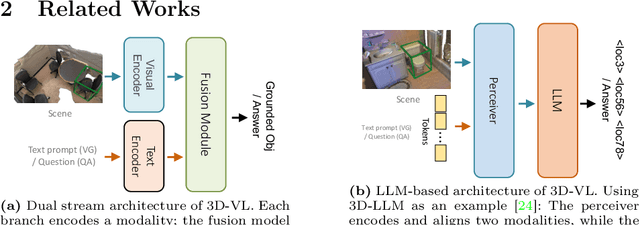
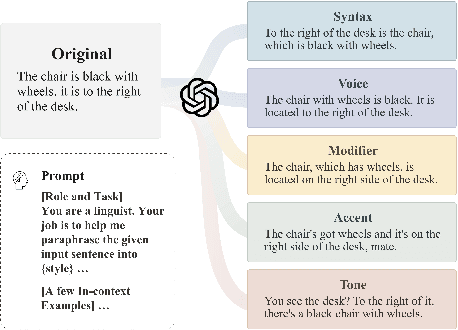
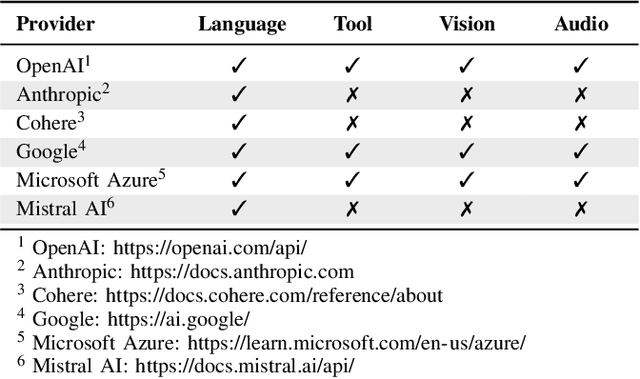
Rapid advancements in 3D vision-language (3D-VL) tasks have opened up new avenues for human interaction with embodied agents or robots using natural language. Despite this progress, we find a notable limitation: existing 3D-VL models exhibit sensitivity to the styles of language input, struggling to understand sentences with the same semantic meaning but written in different variants. This observation raises a critical question: Can 3D vision-language models truly understand natural language? To test the language understandability of 3D-VL models, we first propose a language robustness task for systematically assessing 3D-VL models across various tasks, benchmarking their performance when presented with different language style variants. Importantly, these variants are commonly encountered in applications requiring direct interaction with humans, such as embodied robotics, given the diversity and unpredictability of human language. We propose a 3D Language Robustness Dataset, designed based on the characteristics of human language, to facilitate the systematic study of robustness. Our comprehensive evaluation uncovers a significant drop in the performance of all existing models across various 3D-VL tasks. Even the state-of-the-art 3D-LLM fails to understand some variants of the same sentences. Further in-depth analysis suggests that the existing models have a fragile and biased fusion module, which stems from the low diversity of the existing dataset. Finally, we propose a training-free module driven by LLM, which improves language robustness. Datasets and code will be available at github.
Beyond Finite Data: Towards Data-free Out-of-distribution Generalization via Extrapolation
Mar 11, 2024Out-of-distribution (OOD) generalization is a favorable yet challenging property for deep neural networks. The core challenges lie in the limited availability of source domains that help models learn an invariant representation from the spurious features. Various domain augmentation have been proposed but largely rely on interpolating existing domains and frequently face difficulties in creating truly "novel" domains. Humans, on the other hand, can easily extrapolate novel domains, thus, an intriguing question arises: How can neural networks extrapolate like humans and achieve OOD generalization? We introduce a novel approach to domain extrapolation that leverages reasoning ability and the extensive knowledge encapsulated within large language models (LLMs) to synthesize entirely new domains. Starting with the class of interest, we query the LLMs to extract relevant knowledge for these novel domains. We then bridge the gap between the text-centric knowledge derived from LLMs and the pixel input space of the model using text-to-image generation techniques. By augmenting the training set of domain generalization datasets with high-fidelity, photo-realistic images of these new domains, we achieve significant improvements over all existing methods, as demonstrated in both single and multi-domain generalization across various benchmarks. With the ability to extrapolate any domains for any class, our method has the potential to learn a generalized model for any task without any data. To illustrate, we put forth a much more difficult setting termed, data-free domain generalization, that aims to learn a generalized model in the absence of any collected data. Our empirical findings support the above argument and our methods exhibit commendable performance in this setting, even surpassing the supervised setting by approximately 1-2\% on datasets such as VLCS.