 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniGen: Unified $S^3$ Fields for Animatable 3D Asset Generation
Apr 14, 2026Animatable 3D assets, defined as geometry equipped with an articulated skeleton and skinning weights, are fundamental to interactive graphics, embodied agents, and animation production. While recent 3D generative models can synthesize visually plausible shapes from images, the results are typically static. Obtaining usable rigs via post-hoc auto-rigging is brittle and often produces skeletons that are topologically inconsistent with the generated geometry. We present AniGen, a unified framework that directly generates animate-ready 3D assets conditioned on a single image. Our key insight is to represent shape, skeleton, and skinning as mutually consistent $S^3$ Fields (Shape, Skeleton, Skin) defined over a shared spatial domain. To enable the robust learning of these fields, we introduce two technical innovations: (i) a confidence-decaying skeleton field that explicitly handles the geometric ambiguity of bone prediction at Voronoi boundaries, and (ii) a dual skin feature field that decouples skinning weights from specific joint counts, allowing a fixed-architecture network to predict rigs of arbitrary complexity. Built upon a two-stage flow-matching pipeline, AniGen first synthesizes a sparse structural scaffold and then generates dense geometry and articulation in a structured latent space. Extensive experiments demonstrate that AniGen substantially outperforms state-of-the-art sequential baselines in rig validity and animation quality, generalizing effectively to in-the-wild images across diverse categories including animals, humanoids, and machinery. Homepage: https://yihua7.github.io/AniGen-web/
ObjectMorpher: 3D-Aware Image Editing via Deformable 3DGS Models
Mar 30, 2026Achieving precise, object-level control in image editing remains challenging: 2D methods lack 3D awareness and often yield ambiguous or implausible results, while existing 3D-aware approaches rely on heavy optimization or incomplete monocular reconstructions. We present ObjectMorpher, a unified, interactive framework that converts ambiguous 2D edits into geometry-grounded operations. ObjectMorpher lifts target instances with an image-to-3D generator into editable 3D Gaussian Splatting (3DGS), enabling fast, identity-preserving manipulation. Users drag control points; a graph-based non-rigid deformation with as-rigid-as-possible (ARAP) constraints ensures physically sensible shape and pose changes. A composite diffusion module harmonizes lighting, color, and boundaries for seamless reintegration. Across diverse categories, ObjectMorpher delivers fine-grained, photorealistic edits with superior controllability and efficiency, outperforming 2D drag and 3D-aware baselines on KID, LPIPS, SIFID, and user preference.
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Dec 18, 2025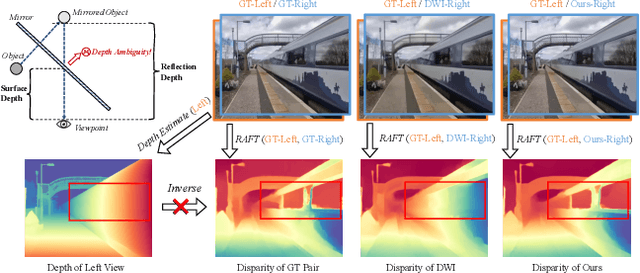

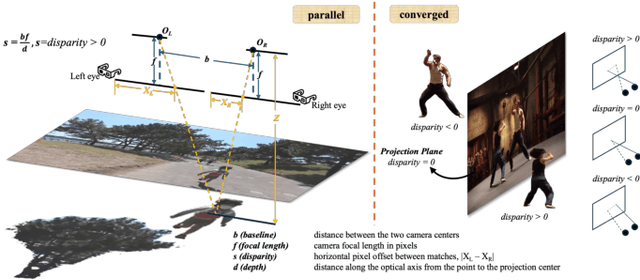

The rapid growth of stereoscopic displays, including VR headsets and 3D cinemas, has led to increasing demand for high-quality stereo video content. However, producing 3D videos remains costly and complex, while automatic Monocular-to-Stereo conversion is hindered by the limitations of the multi-stage ``Depth-Warp-Inpaint'' (DWI) pipeline. This paradigm suffers from error propagation, depth ambiguity, and format inconsistency between parallel and converged stereo configurations. To address these challenges, we introduce UniStereo, the first large-scale unified dataset for stereo video conversion, covering both stereo formats to enable fair benchmarking and robust model training. Building upon this dataset, we propose StereoPilot, an efficient feed-forward model that directly synthesizes the target view without relying on explicit depth maps or iterative diffusion sampling. Equipped with a learnable domain switcher and a cycle consistency loss, StereoPilot adapts seamlessly to different stereo formats and achieves improved consistency. Extensive experiments demonstrate that StereoPilot significantly outperforms state-of-the-art methods in both visual fidelity and computational efficiency. Project page: https://hit-perfect.github.io/StereoPilot/.
ASSIST-3D: Adapted Scene Synthesis for Class-Agnostic 3D Instance Segmentation
Dec 10, 2025Class-agnostic 3D instance segmentation tackles the challenging task of segmenting all object instances, including previously unseen ones, without semantic class reliance. Current methods struggle with generalization due to the scarce annotated 3D scene data or noisy 2D segmentations. While synthetic data generation offers a promising solution, existing 3D scene synthesis methods fail to simultaneously satisfy geometry diversity, context complexity, and layout reasonability, each essential for this task. To address these needs, we propose an Adapted 3D Scene Synthesis pipeline for class-agnostic 3D Instance SegmenTation, termed as ASSIST-3D, to synthesize proper data for model generalization enhancement. Specifically, ASSIST-3D features three key innovations, including 1) Heterogeneous Object Selection from extensive 3D CAD asset collections, incorporating randomness in object sampling to maximize geometric and contextual diversity; 2) Scene Layout Generation through LLM-guided spatial reasoning combined with depth-first search for reasonable object placements; and 3) Realistic Point Cloud Construction via multi-view RGB-D image rendering and fusion from the synthetic scenes, closely mimicking real-world sensor data acquisition. Experiments on ScanNetV2, ScanNet++, and S3DIS benchmarks demonstrate that models trained with ASSIST-3D-generated data significantly outperform existing methods. Further comparisons underscore the superiority of our purpose-built pipeline over existing 3D scene synthesis approaches.
NoteIt: A System Converting Instructional Videos to Interactable Notes Through Multimodal Video Understanding
Aug 20, 2025



Users often take notes for instructional videos to access key knowledge later without revisiting long videos. Automated note generation tools enable users to obtain informative notes efficiently. However, notes generated by existing research or off-the-shelf tools fail to preserve the information conveyed in the original videos comprehensively, nor can they satisfy users' expectations for diverse presentation formats and interactive features when using notes digitally. In this work, we present NoteIt, a system, which automatically converts instructional videos to interactable notes using a novel pipeline that faithfully extracts hierarchical structure and multimodal key information from videos. With NoteIt's interface, users can interact with the system to further customize the content and presentation formats of the notes according to their preferences. We conducted both a technical evaluation and a comparison user study (N=36). The solid performance in objective metrics and the positive user feedback demonstrated the effectiveness of the pipeline and the overall usability of NoteIt. Project website: https://zhaorunning.github.io/NoteIt/
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
What Matters in Detecting AI-Generated Videos like Sora?
Jun 27, 2024Recent advancements in diffusion-based video generation have showcased remarkable results, yet the gap between synthetic and real-world videos remains under-explored. In this study, we examine this gap from three fundamental perspectives: appearance, motion, and geometry, comparing real-world videos with those generated by a state-of-the-art AI model, Stable Video Diffusion. To achieve this, we train three classifiers using 3D convolutional networks, each targeting distinct aspects: vision foundation model features for appearance, optical flow for motion, and monocular depth for geometry. Each classifier exhibits strong performance in fake video detection, both qualitatively and quantitatively. This indicates that AI-generated videos are still easily detectable, and a significant gap between real and fake videos persists. Furthermore, utilizing the Grad-CAM, we pinpoint systematic failures of AI-generated videos in appearance, motion, and geometry. Finally, we propose an Ensemble-of-Experts model that integrates appearance, optical flow, and depth information for fake video detection, resulting in enhanced robustness and generalization ability. Our model is capable of detecting videos generated by Sora with high accuracy, even without exposure to any Sora videos during training. This suggests that the gap between real and fake videos can be generalized across various video generative models. Project page: https://justin-crchang.github.io/3DCNNDetection.github.io/
Object-level Scene Deocclusion
Jun 11, 2024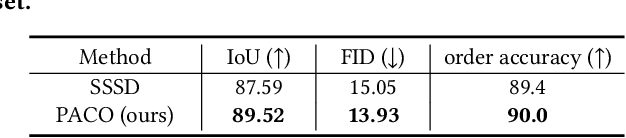

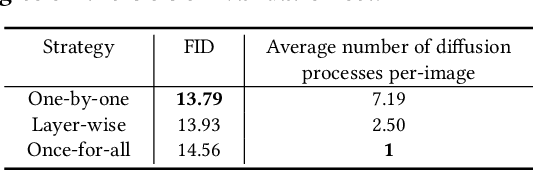
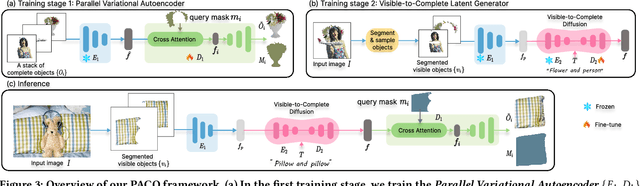
Deoccluding the hidden portions of objects in a scene is a formidable task, particularly when addressing real-world scenes. In this paper, we present a new self-supervised PArallel visible-to-COmplete diffusion framework, named PACO, a foundation model for object-level scene deocclusion. Leveraging the rich prior of pre-trained models, we first design the parallel variational autoencoder, which produces a full-view feature map that simultaneously encodes multiple complete objects, and the visible-to-complete latent generator, which learns to implicitly predict the full-view feature map from partial-view feature map and text prompts extracted from the incomplete objects in the input image. To train PACO, we create a large-scale dataset with 500k samples to enable self-supervised learning, avoiding tedious annotations of the amodal masks and occluded regions. At inference, we devise a layer-wise deocclusion strategy to improve efficiency while maintaining the deocclusion quality. Extensive experiments on COCOA and various real-world scenes demonstrate the superior capability of PACO for scene deocclusion, surpassing the state of the arts by a large margin. Our method can also be extended to cross-domain scenes and novel categories that are not covered by the training set. Further, we demonstrate the deocclusion applicability of PACO in single-view 3D scene reconstruction and object recomposition.
Total-Decom: Decomposed 3D Scene Reconstruction with Minimal Interaction
Mar 30, 2024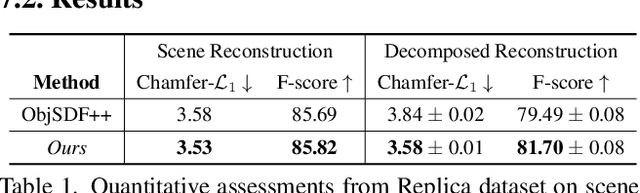



Scene reconstruction from multi-view images is a fundamental problem in computer vision and graphics. Recent neural implicit surface reconstruction methods have achieved high-quality results; however, editing and manipulating the 3D geometry of reconstructed scenes remains challenging due to the absence of naturally decomposed object entities and complex object/background compositions. In this paper, we present Total-Decom, a novel method for decomposed 3D reconstruction with minimal human interaction. Our approach seamlessly integrates the Segment Anything Model (SAM) with hybrid implicit-explicit neural surface representations and a mesh-based region-growing technique for accurate 3D object decomposition. Total-Decom requires minimal human annotations while providing users with real-time control over the granularity and quality of decomposition. We extensively evaluate our method on benchmark datasets and demonstrate its potential for downstream applications, such as animation and scene editing. The code is available at https://github.com/CVMI-Lab/Total-Decom.git.
MarS3D: A Plug-and-Play Motion-Aware Model for Semantic Segmentation on Multi-Scan 3D Point Clouds
Jul 18, 20233D semantic segmentation on multi-scan large-scale point clouds plays an important role in autonomous systems. Unlike the single-scan-based semantic segmentation task, this task requires distinguishing the motion states of points in addition to their semantic categories. However, methods designed for single-scan-based segmentation tasks perform poorly on the multi-scan task due to the lacking of an effective way to integrate temporal information. We propose MarS3D, a plug-and-play motion-aware module for semantic segmentation on multi-scan 3D point clouds. This module can be flexibly combined with single-scan models to allow them to have multi-scan perception abilities. The model encompasses two key designs: the Cross-Frame Feature Embedding module for enriching representation learning and the Motion-Aware Feature Learning module for enhancing motion awareness. Extensive experiments show that MarS3D can improve the performance of the baseline model by a large margin. The code is available at https://github.com/CVMI-Lab/MarS3D.