 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Language Diffusion as a Decoder-Interface Problem
Jun 07, 2026Gaussian-corrupted sentence embeddings have no direct linguistic interpretation, yet continuous diffusion language models can generate fluent text from them. We study this puzzle through Embedded Language Flows (ELF) and identify a decoder-basin mechanism: denoising succeeds when trajectories reach regions where the native decoder can read stable tokens. We introduce a diagnostic protocol for denoisability, semantic recoverability, order sensitivity, decoder compatibility, and trajectory reliability. It exposes failures hidden by scalar metrics: low mean-squared error can discard linguistic content, low perplexity can reflect low-entropy collapse, and clean latent reconstruction can coexist with a narrow decoder basin. A decoder-margin bound explains why token recovery depends on margin and local decoder sensitivity, not latent error alone. Auditing public ELF checkpoints reveals an interface phase diagram: early predictions are weakly readable, mid-trajectory disagreement marks a competition region, and late predictions enter a high-margin final-token basin. Once inside, token realization is surprisingly simple on generated ELF states: frozen T5 token-embedding lookup recovers $93$--$96\%$ of native decoder decisions, and a single linear readout reaches $97.9\%$ agreement at 32k samples, leaving about a 1.1 perplexity gap in a structured residual tail. A conservative margin gate exits $17$--$27\%$ earlier in denoising steps under an explicit diagnostic monitor. Boundary checks on LangFlow, BitstreamDiffusion, and the Continuous Latent Diffusion Language Model (Cola-DLM) show that the same interface questions remain meaningful when the state object and decoder change. Continuous and latent diffusion language models should therefore be evaluated as representation-decoder systems.
Auditing Training-Free 3D Shape Retrieval with Diffused Geodesic Moments
May 27, 2026Reported retrieval scores for training-free shape descriptors conflate local signal design, normalization, aggregation, codebook fitting, and metric choices, making isolated component evaluation difficult. This paper reframes descriptor evaluation as a {\em protocol audit}. We introduce Diffused Geodesic Moments (DGM), a seed-conditioned descriptor that computes sparse implicit heat responses, converts them to distance-like fields, and summarizes each vertex by low-order moments across seeds and scales. DGM is used both as a practical non-spectral baseline and as an instrument for isolating protocol effects. On the registered FAUST benchmark split (FAUST-Reg) and the TOSCA shape collection, aggregation-matched experiments show that an independent Geometric Moment Shape Descriptor baseline built on Heat Kernel Signature features (GMSD-HKS) obtains the highest scores in this implementation ($0.621/0.820$ and $0.865/0.963$ mean average precision (mAP)/top-1), Wave Kernel Signature (WKS) remains a strong classical signal, and DGM is useful mainly when sparse solves, non-spectral deployment, or symmetry-informative seed frames are priorities. The broader finding is methodological: the input field and aggregation protocol can dominate the moment formula. The paper contributes a reproducible protocol-cascade analysis, a cross-shape alignment diagnostic for functional-map compatibility, and concrete recommendations for designing and reporting training-free shape descriptors.
DepthArb: Training-Free Depth-Arbitrated Generation for Occlusion-Robust Image Synthesis
Mar 25, 2026Text-to-image diffusion models frequently exhibit deficiencies in synthesizing accurate occlusion relationships of multiple objects, particularly within dense overlapping regions. Existing training-free layout-guided methods predominantly rely on rigid spatial priors that remain agnostic to depth order, often resulting in concept mixing or illogical occlusion. To address these limitations, we propose DepthArb, a training-free framework that resolves occlusion ambiguities by arbitrating attention competition between interacting objects. Specifically, DepthArb employs two core mechanisms: Attention Arbitration Modulation (AAM), which enforces depth-ordered visibility by suppressing background activations in overlapping regions, and Spatial Compactness Control (SCC), which preserves structural integrity by curbing attention divergence. These mechanisms enable robust occlusion generation without model retraining. To systematically evaluate this capability, we propose OcclBench, a comprehensive benchmark designed to evaluate diverse occlusion scenarios. Extensive evaluations demonstrate that DepthArb consistently outperforms state-of-the-art baselines in both occlusion accuracy and visual fidelity. As a plug-and-play method, DepthArb seamlessly enhances the compositional capabilities of diffusion backbones, offering a novel perspective on spatial layering within generative models.
Enabling Real-Time Colonoscopic Polyp Segmentation on Commodity CPUs via Ultra-Lightweight Architecture
Feb 04, 2026Early detection of colorectal cancer hinges on real-time, accurate polyp identification and resection. Yet current high-precision segmentation models rely on GPUs, making them impractical to deploy in primary hospitals, mobile endoscopy units, or capsule robots. To bridge this gap, we present the UltraSeg family, operating in an extreme-compression regime (<0.3 M parameters). UltraSeg-108K (0.108 M parameters) is optimized for single-center data, while UltraSeg-130K (0.13 M parameters) generalizes to multi-center, multi-modal images. By jointly optimizing encoder-decoder widths, incorporating constrained dilated convolutions to enlarge receptive fields, and integrating a cross-layer lightweight fusion module, the models achieve 90 FPS on a single CPU core without sacrificing accuracy. Evaluated on seven public datasets, UltraSeg retains >94% of the Dice score of a 31 M-parameter U-Net while utilizing only 0.4% of its parameters, establishing a strong, clinically viable baseline for the extreme-compression domain and offering an immediately deployable solution for resource-constrained settings. This work provides not only a CPU-native solution for colonoscopy but also a reproducible blueprint for broader minimally invasive surgical vision applications. Source code is publicly available to ensure reproducibility and facilitate future benchmarking.
LLaVA-RE: Binary Image-Text Relevancy Evaluation with Multimodal Large Language Model
Aug 07, 2025


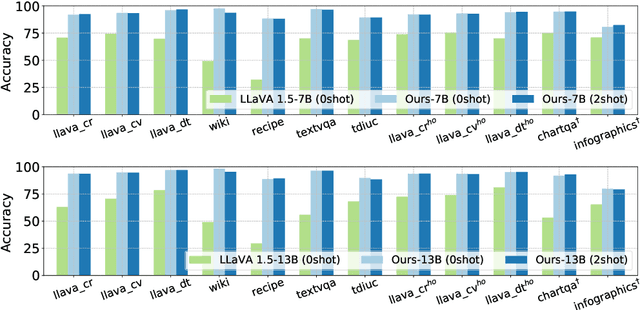
Multimodal generative AI usually involves generating image or text responses given inputs in another modality. The evaluation of image-text relevancy is essential for measuring response quality or ranking candidate responses. In particular, binary relevancy evaluation, i.e., ``Relevant'' vs. ``Not Relevant'', is a fundamental problem. However, this is a challenging task considering that texts have diverse formats and the definition of relevancy varies in different scenarios. We find that Multimodal Large Language Models (MLLMs) are an ideal choice to build such evaluators, as they can flexibly handle complex text formats and take in additional task information. In this paper, we present LLaVA-RE, a first attempt for binary image-text relevancy evaluation with MLLM. It follows the LLaVA architecture and adopts detailed task instructions and multimodal in-context samples. In addition, we propose a novel binary relevancy data set that covers various tasks. Experimental results validate the effectiveness of our framework.
A New Deep-learning-Based Approach For mRNA Optimization: High Fidelity, Computation Efficiency, and Multiple Optimization Factors
May 29, 2025The mRNA optimization is critical for therapeutic and biotechnological applications, since sequence features directly govern protein expression levels and efficacy. However, current methods face significant challenges in simultaneously achieving three key objectives: (1) fidelity (preventing unintended amino acid changes), (2) computational efficiency (speed and scalability), and (3) the scope of optimization variables considered (multi-objective capability). Furthermore, existing methods often fall short of comprehensively incorporating the factors related to the mRNA lifecycle and translation process, including intrinsic mRNA sequence properties, secondary structure, translation elongation kinetics, and tRNA availability. To address these limitations, we introduce \textbf{RNop}, a novel deep learning-based method for mRNA optimization. We collect a large-scale dataset containing over 3 million sequences and design four specialized loss functions, the GPLoss, CAILoss, tAILoss, and MFELoss, which simultaneously enable explicit control over sequence fidelity while optimizing species-specific codon adaptation, tRNA availability, and desirable mRNA secondary structure features. Then, we demonstrate RNop's effectiveness through extensive in silico and in vivo experiments. RNop ensures high sequence fidelity, achieves significant computational throughput up to 47.32 sequences/s, and yields optimized mRNA sequences resulting in a significant increase in protein expression for functional proteins compared to controls. RNop surpasses current methodologies in both quantitative metrics and experimental validation, enlightening a new dawn for efficient and effective mRNA design. Code and models will be available at https://github.com/HudenJear/RPLoss.
Multitemporal Latent Dynamical Framework for Hyperspectral Images Unmixing
May 27, 2025Multitemporal hyperspectral unmixing can capture dynamical evolution of materials. Despite its capability, current methods emphasize variability of endmembers while neglecting dynamics of abundances, which motivates our adoption of neural ordinary differential equations to model abundances temporally. However, this motivation is hindered by two challenges: the inherent complexity in defining, modeling and solving problem, and the absence of theoretical support. To address above challenges, in this paper, we propose a multitemporal latent dynamical (MiLD) unmixing framework by capturing dynamical evolution of materials with theoretical validation. For addressing multitemporal hyperspectral unmixing, MiLD consists of problem definition, mathematical modeling, solution algorithm and theoretical support. We formulate multitemporal unmixing problem definition by conducting ordinary differential equations and developing latent variables. We transfer multitemporal unmixing to mathematical model by dynamical discretization approaches, which describe the discreteness of observed sequence images with mathematical expansions. We propose algorithm to solve problem and capture dynamics of materials, which approximates abundance evolution by neural networks. Furthermore, we provide theoretical support by validating the crucial properties, which verifies consistency, convergence and stability theorems. The major contributions of MiLD include defining problem by ordinary differential equations, modeling problem by dynamical discretization approach, solving problem by multitemporal unmixing algorithm, and presenting theoretical support. Our experiments on both synthetic and real datasets have validated the utility of our work
AI-driven Prediction of Insulin Resistance in Normal Populations: Comparing Models and Criteria
Mar 07, 2025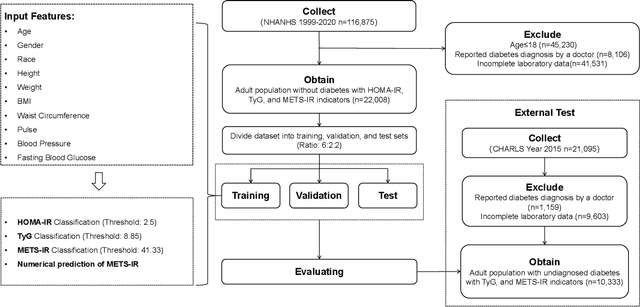
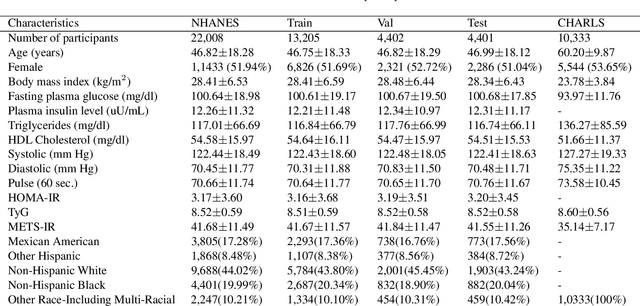
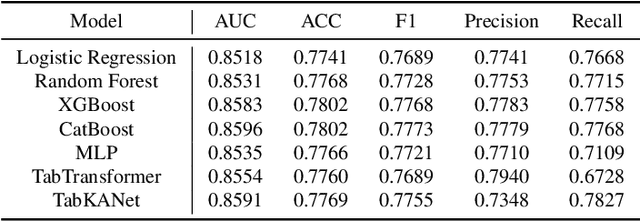
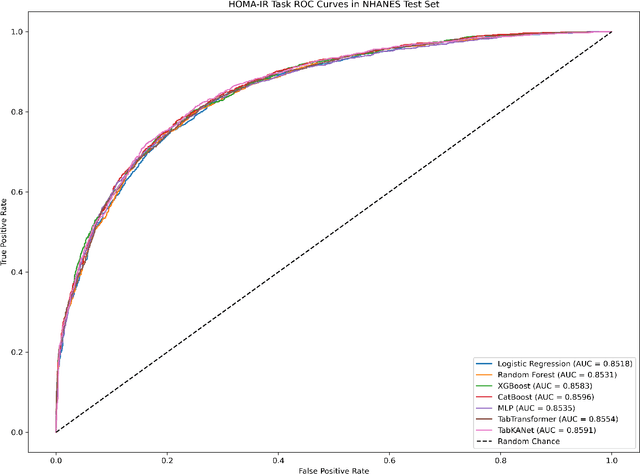
Insulin resistance (IR) is a key precursor to diabetes and a significant risk factor for cardiovascular disease. Traditional IR assessment methods require multiple blood tests. We developed a simple AI model using only fasting blood glucose to predict IR in non-diabetic populations. Data from the NHANES (1999-2020) and CHARLS (2015) studies were used for model training and validation. Input features included age, gender, height, weight, blood pressure, waist circumference, and fasting blood glucose. The CatBoost algorithm achieved AUC values of 0.8596 (HOMA-IR) and 0.7777 (TyG index) in NHANES, with an external AUC of 0.7442 for TyG. For METS-IR prediction, the model achieved AUC values of 0.9731 (internal) and 0.9591 (external), with RMSE values of 3.2643 (internal) and 3.057 (external). SHAP analysis highlighted waist circumference as a key predictor of IR. This AI model offers a minimally invasive and effective tool for IR prediction, supporting early diabetes and cardiovascular disease prevention.
Acquire Precise and Comparable Fundus Image Quality Score: FTHNet and FQS Dataset
Nov 19, 2024The retinal fundus images are utilized extensively in the diagnosis, and their quality can directly affect the diagnosis results. However, due to the insufficient dataset and algorithm application, current fundus image quality assessment (FIQA) methods are not powerful enough to meet ophthalmologists` demands. In this paper, we address the limitations of datasets and algorithms in FIQA. First, we establish a new FIQA dataset, Fundus Quality Score(FQS), which includes 2246 fundus images with two labels: a continuous Mean Opinion Score varying from 0 to 100 and a three-level quality label. Then, we propose a FIQA Transformer-based Hypernetwork (FTHNet) to solve these tasks with regression results rather than classification results in conventional FIQA works. The FTHNet is optimized for the FIQA tasks with extensive experiments. Results on our FQS dataset show that the FTHNet can give quality scores for fundus images with PLCC of 0.9423 and SRCC of 0.9488, significantly outperforming other methods with fewer parameters and less computation complexity.We successfully build a dataset and model addressing the problems of current FIQA methods. Furthermore, the model deployment experiments demonstrate its potential in automatic medical image quality control. All experiments are carried out with 10-fold cross-validation to ensure the significance of the results.
Versatile Cataract Fundus Image Restoration Model Utilizing Unpaired Cataract and High-quality Images
Nov 19, 2024



Cataract is one of the most common blinding eye diseases and can be treated by surgery. However, because cataract patients may also suffer from other blinding eye diseases, ophthalmologists must diagnose them before surgery. The cloudy lens of cataract patients forms a hazy degeneration in the fundus images, making it challenging to observe the patient's fundus vessels, which brings difficulties to the diagnosis process. To address this issue, this paper establishes a new cataract image restoration method named Catintell. It contains a cataract image synthesizing model, Catintell-Syn, and a restoration model, Catintell-Res. Catintell-Syn uses GAN architecture with fully unsupervised data to generate paired cataract-like images with realistic style and texture rather than the conventional Gaussian degradation algorithm. Meanwhile, Catintell-Res is an image restoration network that can improve the quality of real cataract fundus images using the knowledge learned from synthetic cataract images. Extensive experiments show that Catintell-Res outperforms other cataract image restoration methods in PSNR with 39.03 and SSIM with 0.9476. Furthermore, the universal restoration ability that Catintell-Res gained from unpaired cataract images can process cataract images from various datasets. We hope the models can help ophthalmologists identify other blinding eye diseases of cataract patients and inspire more medical image restoration methods in the future.