 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisTIRA: Closing the Image-Text Modality Gap in Visual Math Reasoning via Structured Tool Integration
Jan 20, 2026Vision-language models (VLMs) lag behind text-only language models on mathematical reasoning when the same problems are presented as images rather than text. We empirically characterize this as a modality gap: the same question in text form yields markedly higher accuracy than its visually typeset counterpart, due to compounded failures in reading dense formulas, layout, and mixed symbolic-diagrammatic context. First, we introduce VisTIRA (Vision and Tool-Integrated Reasoning Agent), a tool-integrated reasoning framework that enables structured problem solving by iteratively decomposing a given math problem (as an image) into natural language rationales and executable Python steps to determine the final answer. Second, we build a framework to measure and improve visual math reasoning: a LaTeX-based pipeline that converts chain-of-thought math corpora (e.g., NuminaMath) into challenging image counterparts, and a large set of synthetic tool-use trajectories derived from a real-world, homework-style image dataset (called SnapAsk) for fine-tuning VLMs. Our experiments show that tool-integrated supervision improves image-based reasoning, and OCR grounding can further narrow the gap for smaller models, although its benefit diminishes at scale. These findings highlight that modality gap severity inversely correlates with model size, and that structured reasoning and OCR-based grounding are complementary strategies for advancing visual mathematical reasoning.
RS-DPO: A Hybrid Rejection Sampling and Direct Preference Optimization Method for Alignment of Large Language Models
Feb 15, 2024Reinforcement learning from human feedback (RLHF) has been extensively employed to align large language models with user intent. However, proximal policy optimization (PPO) based RLHF is occasionally unstable requiring significant hyperparameter finetuning, and computationally expensive to maximize the estimated reward during alignment. Recently, direct preference optimization (DPO) is proposed to address those challenges. However, DPO relies on contrastive responses generated from human annotator and alternative LLM, instead of the policy model, limiting the effectiveness of the RLHF. In this paper, we addresses both challenges by systematically combining rejection sampling (RS) and DPO. Our proposed method, RS-DPO, initiates with the development of a supervised fine-tuned policy model (SFT). A varied set of k responses per prompt are sampled directly from the SFT model. RS-DPO identifies pairs of contrastive samples based on their reward distribution. Finally, we apply DPO with the contrastive samples to align the model to human preference. Our experiments indicate that our proposed method effectively fine-tunes LLMs with limited resource environments, leading to improved alignment with user intent. Furthermore, it outperforms existing methods, including RS, PPO, and DPO.
A Hybrid Deep Learning-based Approach for Optimal Genotype by Environment Selection
Sep 22, 2023
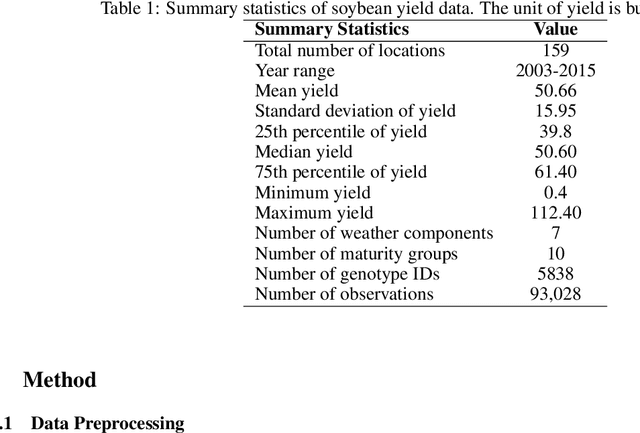


Precise crop yield prediction is essential for improving agricultural practices and ensuring crop resilience in varying climates. Integrating weather data across the growing season, especially for different crop varieties, is crucial for understanding their adaptability in the face of climate change. In the MLCAS2021 Crop Yield Prediction Challenge, we utilized a dataset comprising 93,028 training records to forecast yields for 10,337 test records, covering 159 locations across 28 U.S. states and Canadian provinces over 13 years (2003-2015). This dataset included details on 5,838 distinct genotypes and daily weather data for a 214-day growing season, enabling comprehensive analysis. As one of the winning teams, we developed two novel convolutional neural network (CNN) architectures: the CNN-DNN model, combining CNN and fully-connected networks, and the CNN-LSTM-DNN model, with an added LSTM layer for weather variables. Leveraging the Generalized Ensemble Method (GEM), we determined optimal model weights, resulting in superior performance compared to baseline models. The GEM model achieved lower RMSE (5.55% to 39.88%), reduced MAE (5.34% to 43.76%), and higher correlation coefficients (1.1% to 10.79%) when evaluated on test data. We applied the CNN-DNN model to identify top-performing genotypes for various locations and weather conditions, aiding genotype selection based on weather variables. Our data-driven approach is valuable for scenarios with limited testing years. Additionally, a feature importance analysis using RMSE change highlighted the significance of location, MG, year, and genotype, along with the importance of weather variables MDNI and AP.
Uncovering Drift in Textual Data: An Unsupervised Method for Detecting and Mitigating Drift in Machine Learning Models
Sep 07, 2023
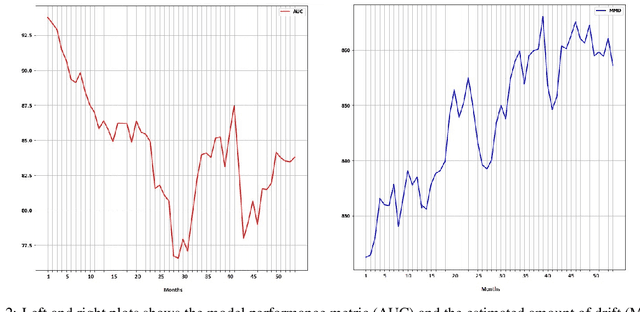


Drift in machine learning refers to the phenomenon where the statistical properties of data or context, in which the model operates, change over time leading to a decrease in its performance. Therefore, maintaining a constant monitoring process for machine learning model performance is crucial in order to proactively prevent any potential performance regression. However, supervised drift detection methods require human annotation and consequently lead to a longer time to detect and mitigate the drift. In our proposed unsupervised drift detection method, we follow a two step process. Our first step involves encoding a sample of production data as the target distribution, and the model training data as the reference distribution. In the second step, we employ a kernel-based statistical test that utilizes the maximum mean discrepancy (MMD) distance metric to compare the reference and target distributions and estimate any potential drift. Our method also identifies the subset of production data that is the root cause of the drift. The models retrained using these identified high drift samples show improved performance on online customer experience quality metrics.
Corn Yield Prediction with Ensemble CNN-DNN
May 29, 2021
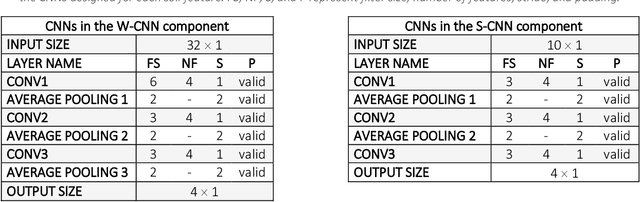
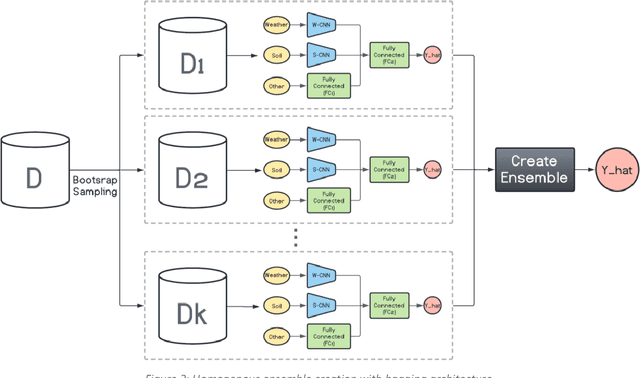
We investigate the predictive performance of two novel CNN-DNN machine learning ensemble models in predicting county-level corn yields across the US Corn Belt (12 states). The developed data set is a combination of management, environment, and historical corn yields from 1980-2019. Two scenarios for ensemble creation are considered: homogenous and heterogeneous ensembles. In homogenous ensembles, the base CNN-DNN models are all the same, but they are generated with a bagging procedure to ensure they exhibit a certain level of diversity. Heterogenous ensembles are created from different base CNN-DNN models which share the same architecture but have different levels of depth. Three types of ensemble creation methods were used to create several ensembles for either of the scenarios: Basic Ensemble Method (BEM), Generalized Ensemble Method (GEM), and stacked generalized ensembles. Results indicated that both designed ensemble types (heterogenous and homogenous) outperform the ensembles created from five individual ML models (linear regression, LASSO, random forest, XGBoost, and LightGBM). Furthermore, by introducing improvements over the heterogeneous ensembles, the homogenous ensembles provide the most accurate yield predictions across US Corn Belt states. This model could make 2019 yield predictions with a root mean square error of 866 kg/ha, equivalent to 8.5% relative root mean square, and could successfully explain about 77% of the spatio-temporal variation in the corn grain yields. The significant predictive power of this model can be leveraged for designing a reliable tool for corn yield prediction which will, in turn, assist agronomic decision-makers.
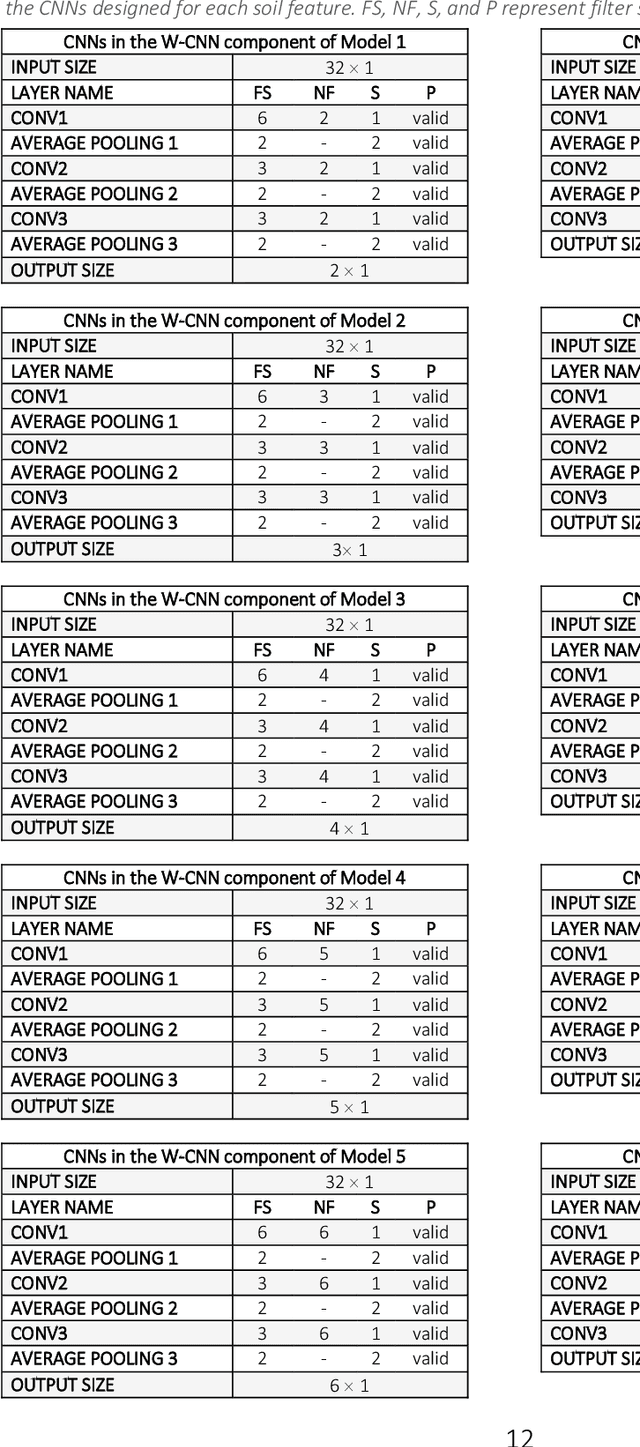
Comparison of Machine Learning Methods for Predicting Winter Wheat Yield in Germany
May 04, 2021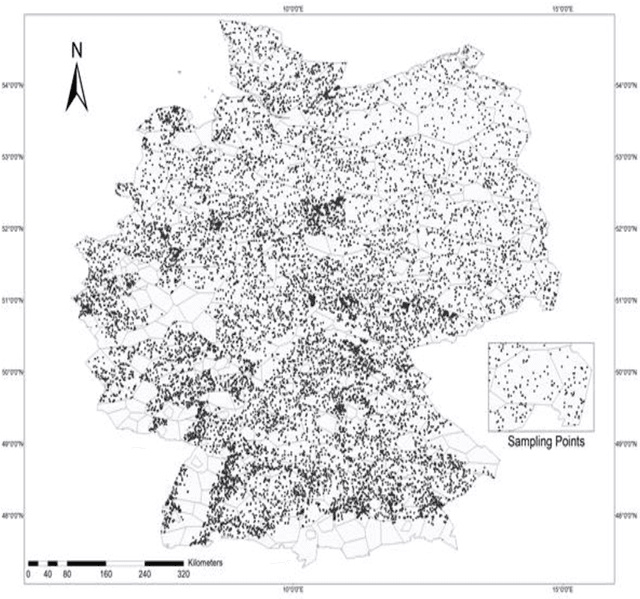
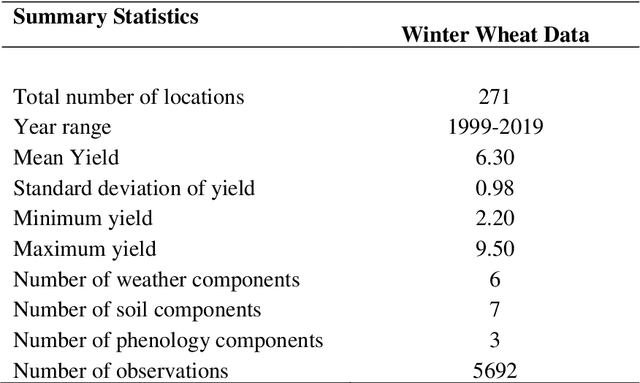
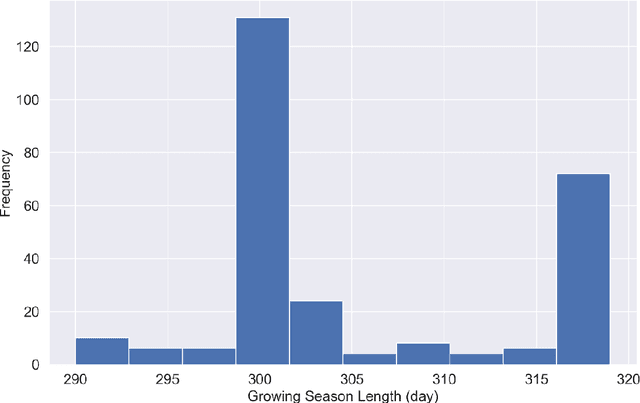
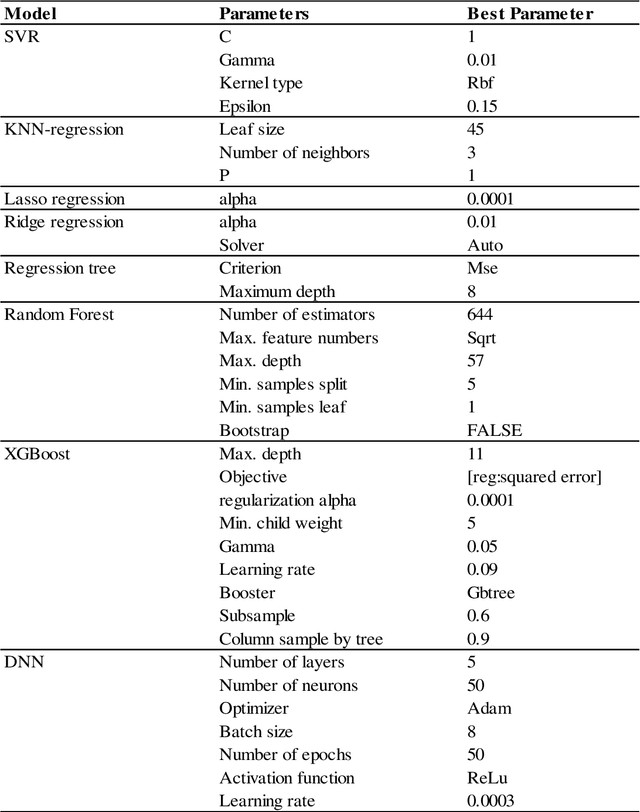
This study analyzed the performance of different machine learning methods for winter wheat yield prediction using extensive datasets of weather, soil, and crop phenology. To address the seasonality, weekly features were used that explicitly take soil moisture conditions and meteorological events into account. Our results indicated that nonlinear models such as deep neural networks (DNN) and XGboost are more effective in finding the functional relationship between the crop yield and input data compared to linear models. The results also revealed that the deep neural networks often had a higher prediction accuracy than XGboost. One of the main limitations of machine learning models is their black box property. As a result, we moved beyond prediction and performed feature selection, as it provides key results towards explaining yield prediction (variable importance by time). The feature selection method estimated the individual effect of weather components, soil conditions, and phenology variables as well as the time that these variables become important. As such, our study indicates which variables have the most significant effect on winter wheat yield.
WheatNet: A Lightweight Convolutional Neural Network for High-throughput Image-based Wheat Head Detection and Counting
Mar 20, 2021
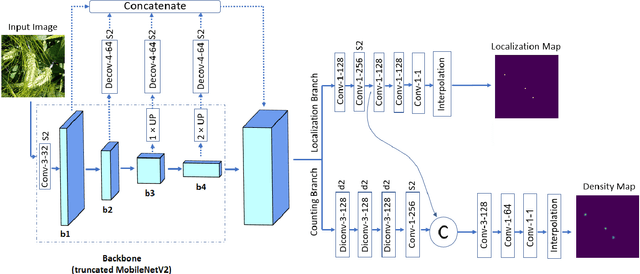
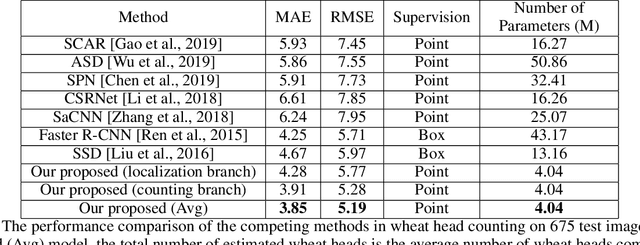

For a globally recognized planting breeding organization, manually-recorded field observation data is crucial for plant breeding decision making. However, certain phenotypic traits such as plant color, height, kernel counts, etc. can only be collected during a specific time-window of a crop's growth cycle. Due to labor-intensive requirements, only a small subset of possible field observations are recorded each season. To help mitigate this data collection bottleneck in wheat breeding, we propose a novel deep learning framework to accurately and efficiently count wheat heads to aid in the gathering of real-time data for decision making. We call our model WheatNet and show that our approach is robust and accurate for a wide range of environmental conditions of the wheat field. WheatNet uses a truncated MobileNetV2 as a lightweight backbone feature extractor which merges feature maps with different scales to counter image scale variations. Then, extracted multi-scale features go to two parallel sub-networks for simultaneous density-based counting and localization tasks. Our proposed method achieves an MAE and RMSE of 3.85 and 5.19 in our wheat head counting task, respectively, while having significantly fewer parameters when compared to other state-of-the-art methods. Our experiments and comparisons with other state-of-the-art methods demonstrate the superiority and effectiveness of our proposed method.
YieldNet: A Convolutional Neural Network for Simultaneous Corn and Soybean Yield Prediction Based on Remote Sensing Data
Dec 05, 2020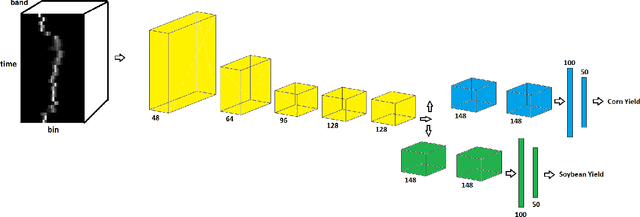

Large scale crop yield estimation is, in part, made possible due to the availability of remote sensing data allowing for the continuous monitoring of crops throughout its growth state. Having this information allows stakeholders the ability to make real-time decisions to maximize yield potential. Although various models exist that predict yield from remote sensing data, there currently does not exist an approach that can estimate yield for multiple crops simultaneously, and thus leads to more accurate predictions. A model that predicts yield of multiple crops and concurrently considers the interaction between multiple crop's yield. We propose a new model called YieldNet which utilizes a novel deep learning framework that uses transfer learning between corn and soybean yield predictions by sharing the weights of the backbone feature extractor. Additionally, to consider the multi-target response variable, we propose a new loss function. Numerical results demonstrate that our proposed method accurately predicts yield from one to four months before the harvest, and is competitive to other state-of-the-art approaches.
High-Throughput Image-Based Plant Stand Count Estimation Using Convolutional Neural Networks
Oct 23, 2020
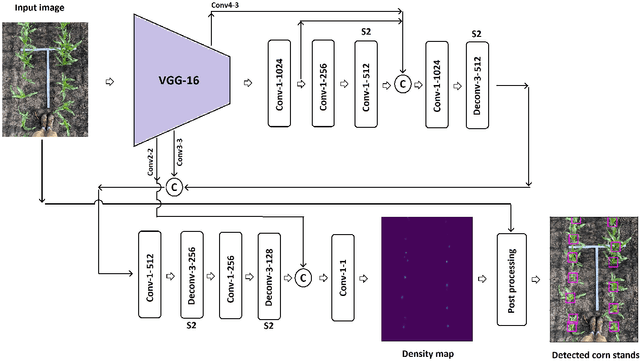
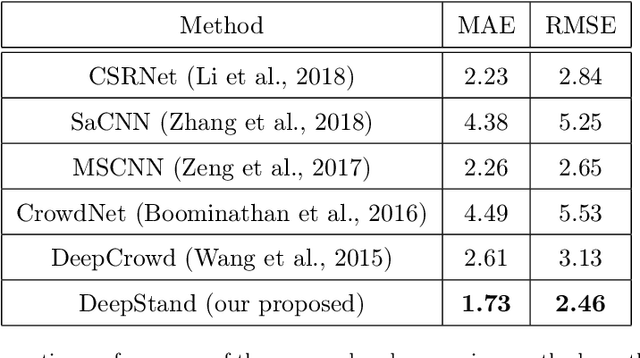

The future landscape of modern farming and plant breeding is rapidly changing due to the complex needs of our society. The explosion of collectable data has started a revolution in agriculture to the point where innovation must occur. To a commercial organization, the accurate and efficient collection of information is necessary to ensure that optimal decisions are made at key points of the breeding cycle. However, due to the shear size of a breeding program and current resource limitations, the ability to collect precise data on individual plants is not possible. In particular, efficient phenotyping of crops to record its color, shape, chemical properties, disease susceptibility, etc. is severely limited due to labor requirements and, oftentimes, expert domain knowledge. In this paper, we propose a deep learning based approach, named DeepStand, for image-based corn stand counting at early phenological stages. The proposed method adopts a truncated VGG-16 network as a backbone feature extractor and merges multiple feature maps with different scales to make the network robust against scale variation. Our extensive computational experiments suggest that our proposed method can successfully count corn stands and out-perform other state-of-the-art methods. It is the goal of our work to be used by the larger agricultural community as a way to enable high-throughput phenotyping without the use of extensive time and labor requirements.
DeepCorn: A Semi-Supervised Deep Learning Method for High-Throughput Image-Based Corn Kernel Counting and Yield Estimation
Jul 20, 2020

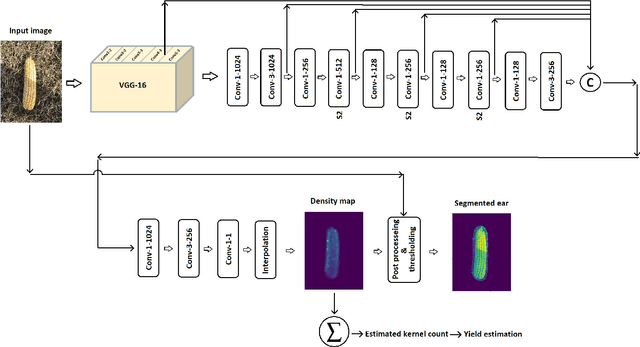
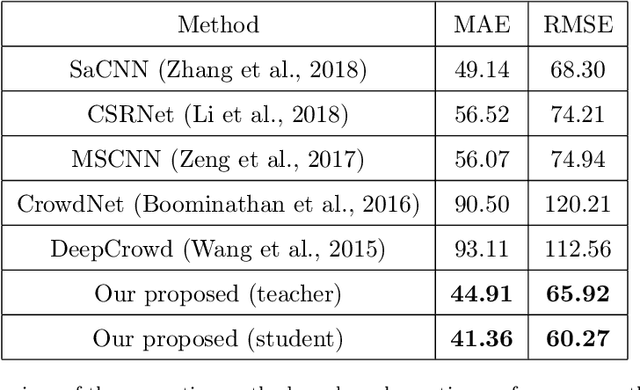
The success of modern farming and plant breeding relies on accurate and efficient collection of data. For a commercial organization that manages large amounts of crops, collecting accurate and consistent data is a bottleneck. Due to limited time and labor, accurately phenotyping crops to record color, head count, height, weight, etc. is severely limited. However, this information, combined with other genetic and environmental factors, is vital for developing new superior crop species that help feed the world's growing population. Recent advances in machine learning, in particular deep learning, have shown promise in mitigating this bottleneck. In this paper, we propose a novel deep learning method for counting on-ear corn kernels in-field to aid in the gathering of real-time data and, ultimately, to improve decision making to maximize yield. We name this approach DeepCorn, and show that this framework is robust under various conditions and can accurately and efficiently count corn kernels. We also adopt a semi-supervised learning approach to further improve the performance of our proposed method. Our experimental results demonstrate the superiority and effectiveness of our proposed method compared to other state-of-the-art methods.