 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Budgeted Adaptation of Large Language Models
Feb 01, 2026The trade-off between labeled data availability and downstream accuracy remains a central challenge in fine-tuning large language models (LLMs). We propose a principled framework for \emph{budget-aware supervised fine-tuning} by casting LLM adaptation as a contextual Stackelberg game. In our formulation, the learner (leader) commits to a scoring policy and a label-querying strategy, while an adaptive environment (follower) selects challenging supervised alternatives in response. To explicitly address label efficiency, we incorporate a finite supervision budget directly into the learning objective. Our algorithm operates in the full-feedback regime and achieves $\tilde{O}(d\sqrt{T})$ regret under standard linear contextual assumptions. We extend the framework with a Largest-Latency-First (LLF) confidence gate that selectively queries labels, achieving a budget-aware regret bound of $\tilde{O}(\sqrt{dB} + c\sqrt{B})$ with $B=βT$.
Linguistic and Argument Diversity in Synthetic Data for Function-Calling Agents
Jan 25, 2026The construction of function calling agents has emerged as a promising avenue for extending model capabilities. A major challenge for this task is obtaining high quality diverse data for training. Prior work emphasizes diversity in functions, invocation patterns, and interaction turns, yet linguistic diversity of requests and coverage of arguments (e.g., \texttt{city\_name}, \texttt{stock\_ticker}) remain underexplored. We propose a method that generates synthetic datasets via optimizing general-purpose diversity metrics across both queries and arguments, without relying on hand-crafted rules or taxonomies, making it robust to different usecases. We demonstrate the effectiveness of our technique via both intrinsic and extrinsic testing, comparing it to SoTA data generation methods. We show a superiority over baselines in terms of diversity, while keeping comparable correctness. Additionally, when used as a training set, the model resulting from our dataset exhibits superior performance compared to analogous models based on the baseline data generation methods in out-of-distribution performance. In particular, we achieve an $7.4\%$ increase in accuracy on the BFCL benchmark compared to similar counterparts.
The Cross-Lingual Cost: Retrieval Biases in RAG over Arabic-English Corpora
Jul 10, 2025Cross-lingual retrieval-augmented generation (RAG) is a critical capability for retrieving and generating answers across languages. Prior work in this context has mostly focused on generation and relied on benchmarks derived from open-domain sources, most notably Wikipedia. In such settings, retrieval challenges often remain hidden due to language imbalances, overlap with pretraining data, and memorized content. To address this gap, we study Arabic-English RAG in a domain-specific setting using benchmarks derived from real-world corporate datasets. Our benchmarks include all combinations of languages for the user query and the supporting document, drawn independently and uniformly at random. This enables a systematic study of multilingual retrieval behavior. Our findings reveal that retrieval is a critical bottleneck in cross-lingual domain-specific scenarios, with significant performance drops occurring when the user query and supporting document languages differ. A key insight is that these failures stem primarily from the retriever's difficulty in ranking documents across languages. Finally, we propose a simple retrieval strategy that addresses this source of failure by enforcing equal retrieval from both languages, resulting in substantial improvements in cross-lingual and overall performance. These results highlight meaningful opportunities for improving multilingual retrieval, particularly in practical, real-world RAG applications.
The Distracting Effect: Understanding Irrelevant Passages in RAG
May 11, 2025A well-known issue with Retrieval Augmented Generation (RAG) is that retrieved passages that are irrelevant to the query sometimes distract the answer-generating LLM, causing it to provide an incorrect response. In this paper, we shed light on this core issue and formulate the distracting effect of a passage w.r.t. a query (and an LLM). We provide a quantifiable measure of the distracting effect of a passage and demonstrate its robustness across LLMs. Our research introduces novel methods for identifying and using hard distracting passages to improve RAG systems. By fine-tuning LLMs with these carefully selected distracting passages, we achieve up to a 7.5% increase in answering accuracy compared to counterparts fine-tuned on conventional RAG datasets. Our contribution is two-fold: first, we move beyond the simple binary classification of irrelevant passages as either completely unrelated vs. distracting, and second, we develop and analyze multiple methods for finding hard distracting passages. To our knowledge, no other research has provided such a comprehensive framework for identifying and utilizing hard distracting passages.
Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs
Sep 26, 2024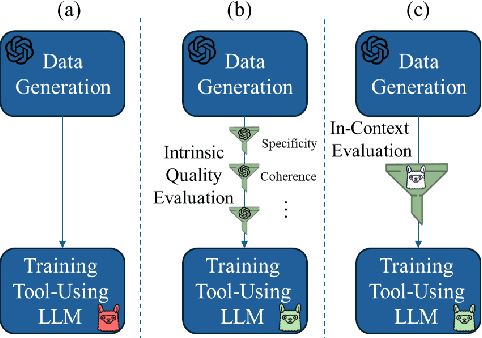


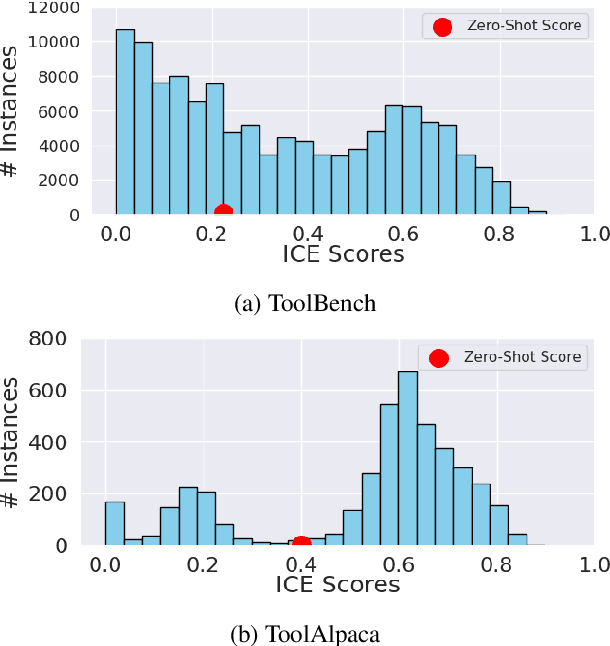
Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs to use external tools. The first approach uses intuitive, human-defined correctness criteria. The second approach uses a model-driven assessment with in-context evaluation. We conduct a thorough evaluation of data quality on two popular benchmarks, followed by an extrinsic evaluation that showcases the impact of data quality on model performance. Our results demonstrate that models trained on high-quality data outperform those trained on unvalidated data, even when trained with a smaller quantity of data. These findings empirically support the significance of assessing and ensuring the reliability of training data for tool-using LLMs.
Uncovering Drift in Textual Data: An Unsupervised Method for Detecting and Mitigating Drift in Machine Learning Models
Sep 07, 2023
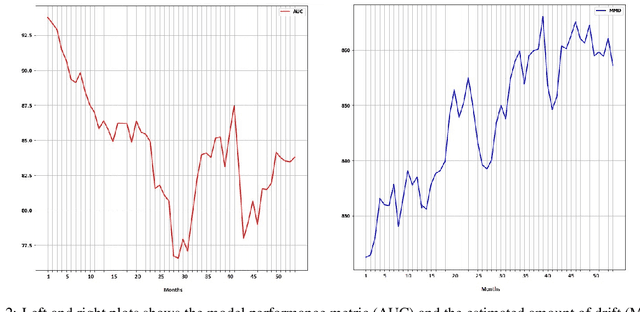


Drift in machine learning refers to the phenomenon where the statistical properties of data or context, in which the model operates, change over time leading to a decrease in its performance. Therefore, maintaining a constant monitoring process for machine learning model performance is crucial in order to proactively prevent any potential performance regression. However, supervised drift detection methods require human annotation and consequently lead to a longer time to detect and mitigate the drift. In our proposed unsupervised drift detection method, we follow a two step process. Our first step involves encoding a sample of production data as the target distribution, and the model training data as the reference distribution. In the second step, we employ a kernel-based statistical test that utilizes the maximum mean discrepancy (MMD) distance metric to compare the reference and target distributions and estimate any potential drift. Our method also identifies the subset of production data that is the root cause of the drift. The models retrained using these identified high drift samples show improved performance on online customer experience quality metrics.
Improving language models fine-tuning with representation consistency targets
May 23, 2022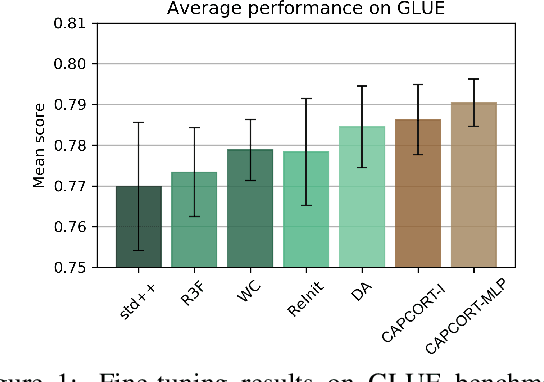

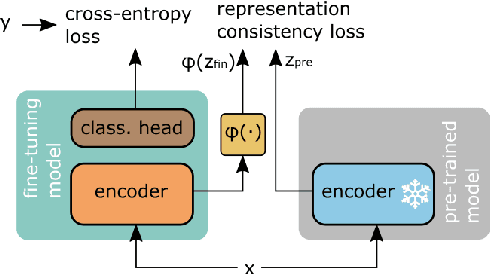

Fine-tuning contextualized representations learned by pre-trained language models has become a standard practice in the NLP field. However, pre-trained representations are prone to degradation (also known as representation collapse) during fine-tuning, which leads to instability, suboptimal performance, and weak generalization. In this paper, we propose a novel fine-tuning method that avoids representation collapse during fine-tuning by discouraging undesirable changes in the representations. We show that our approach matches or exceeds the performance of the existing regularization-based fine-tuning methods across 13 language understanding tasks (GLUE benchmark and six additional datasets). We also demonstrate its effectiveness in low-data settings and robustness to label perturbation. Furthermore, we extend previous studies of representation collapse and propose several metrics to quantify it. Using these metrics and previously proposed experiments, we show that our approach obtains significant improvements in retaining the expressive power of representations.
Pyramid-BERT: Reducing Complexity via Successive Core-set based Token Selection
Mar 27, 2022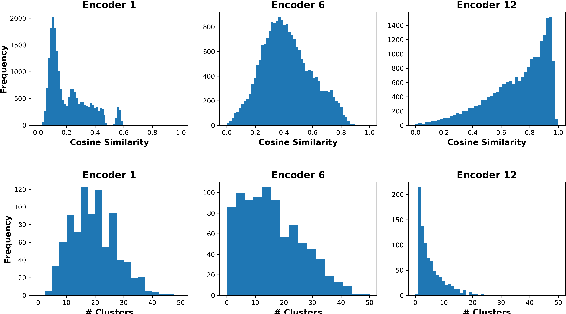
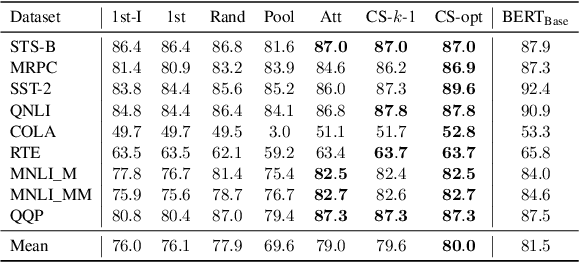
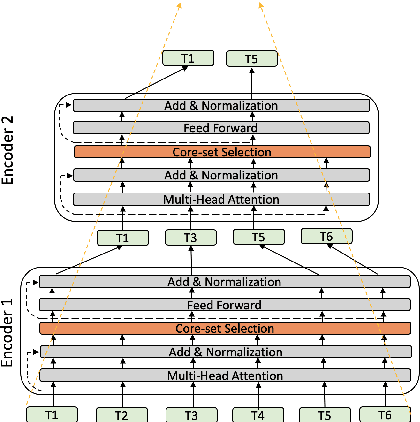
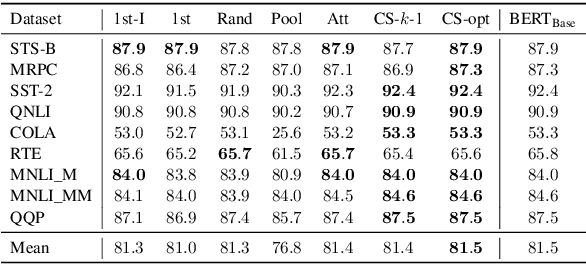
Transformer-based language models such as BERT have achieved the state-of-the-art performance on various NLP tasks, but are computationally prohibitive. A recent line of works use various heuristics to successively shorten sequence length while transforming tokens through encoders, in tasks such as classification and ranking that require a single token embedding for prediction. We present a novel solution to this problem, called Pyramid-BERT where we replace previously used heuristics with a {\em core-set} based token selection method justified by theoretical results. The core-set based token selection technique allows us to avoid expensive pre-training, gives a space-efficient fine tuning, and thus makes it suitable to handle longer sequence lengths. We provide extensive experiments establishing advantages of pyramid BERT over several baselines and existing works on the GLUE benchmarks and Long Range Arena datasets.
Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models
Dec 13, 2021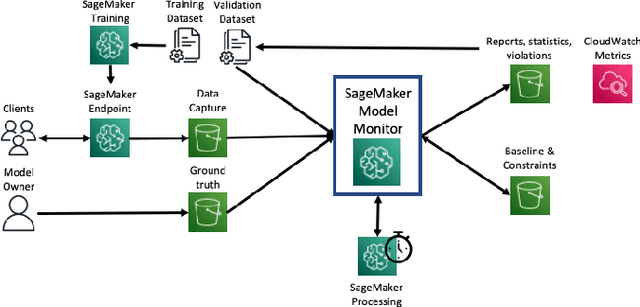
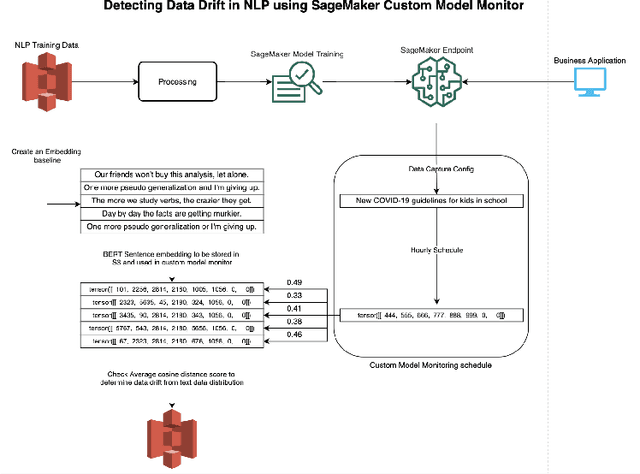
With the increasing adoption of machine learning (ML) models and systems in high-stakes settings across different industries, guaranteeing a model's performance after deployment has become crucial. Monitoring models in production is a critical aspect of ensuring their continued performance and reliability. We present Amazon SageMaker Model Monitor, a fully managed service that continuously monitors the quality of machine learning models hosted on Amazon SageMaker. Our system automatically detects data, concept, bias, and feature attribution drift in models in real-time and provides alerts so that model owners can take corrective actions and thereby maintain high quality models. We describe the key requirements obtained from customers, system design and architecture, and methodology for detecting different types of drift. Further, we provide quantitative evaluations followed by use cases, insights, and lessons learned from more than 1.5 years of production deployment.
Improving Early Sepsis Prediction with Multi Modal Learning
Jul 23, 2021
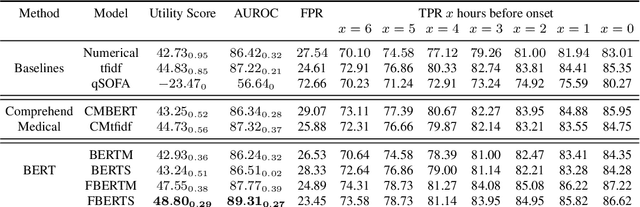


Sepsis is a life-threatening disease with high morbidity, mortality and healthcare costs. The early prediction and administration of antibiotics and intravenous fluids is considered crucial for the treatment of sepsis and can save potentially millions of lives and billions in health care costs. Professional clinical care practitioners have proposed clinical criterion which aid in early detection of sepsis; however, performance of these criterion is often limited. Clinical text provides essential information to estimate the severity of the sepsis in addition to structured clinical data. In this study, we explore how clinical text can complement structured data towards early sepsis prediction task. In this paper, we propose multi modal model which incorporates both structured data in the form of patient measurements as well as textual notes on the patient. We employ state-of-the-art NLP models such as BERT and a highly specialized NLP model in Amazon Comprehend Medical to represent the text. On the MIMIC-III dataset containing records of ICU admissions, we show that by using these notes, one achieves an improvement of 6.07 points in a standard utility score for Sepsis prediction and 2.89% in AUROC score. Our methods significantly outperforms a clinical criteria suggested by experts, qSOFA, as well as the winning model of the PhysioNet Computing in Cardiology Challenge for predicting Sepsis.