 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical and sample efficient zero-shot HPO
Jul 27, 2020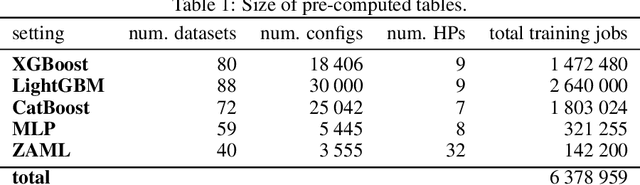
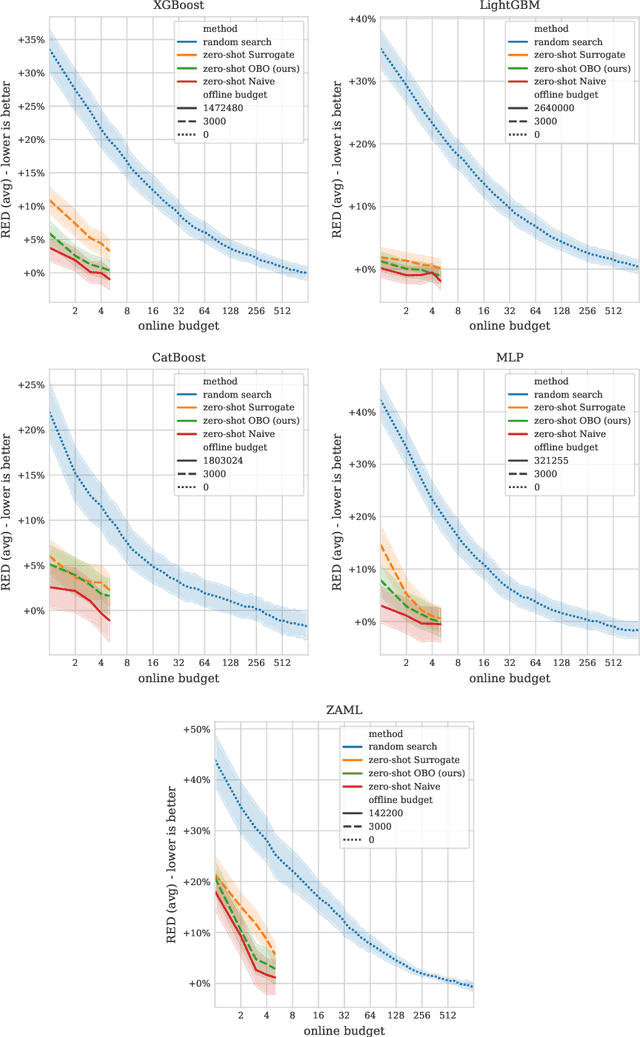
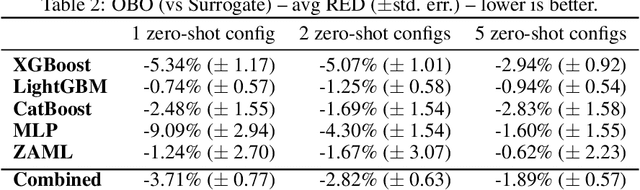
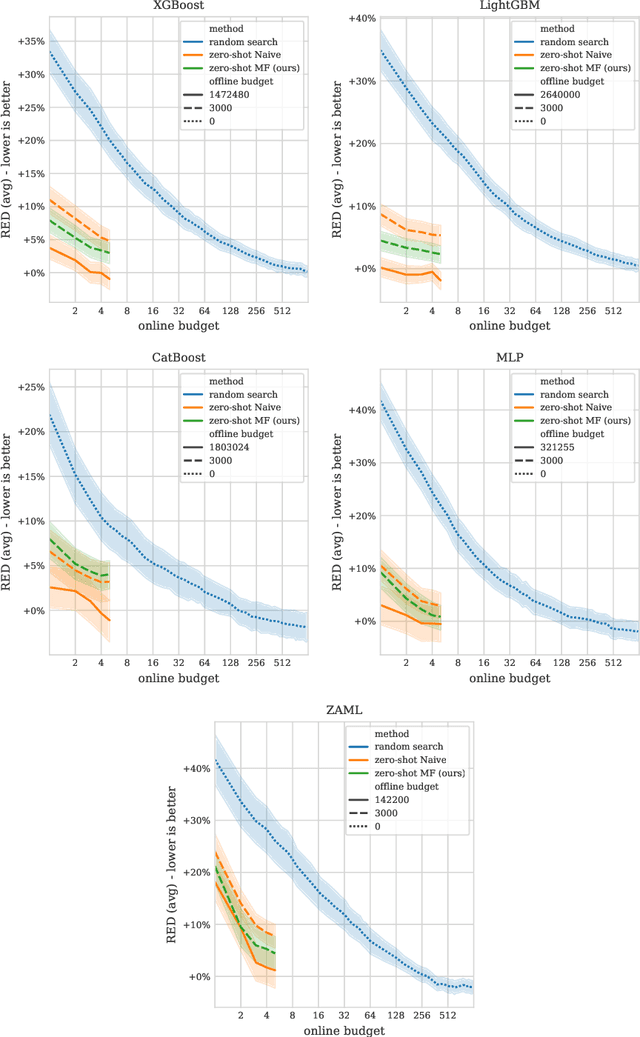
Zero-shot hyperparameter optimization (HPO) is a simple yet effective use of transfer learning for constructing a small list of hyperparameter (HP) configurations that complement each other. That is to say, for any given dataset, at least one of them is expected to perform well. Current techniques for obtaining this list are computationally expensive as they rely on running training jobs on a diverse collection of datasets and a large collection of randomly drawn HPs. This cost is especially problematic in environments where the space of HPs is regularly changing due to new algorithm versions, or changing architectures of deep networks. We provide an overview of available approaches and introduce two novel techniques to handle the problem. The first is based on a surrogate model and adaptively chooses pairs of dataset, configuration to query. The second, for settings where finding, tuning and testing a surrogate model is problematic, is a multi-fidelity technique combining HyperBand with submodular optimization. We benchmark our methods experimentally on five tasks (XGBoost, LightGBM, CatBoost, MLP and AutoML) and show significant improvement in accuracy compared to standard zero-shot HPO with the same training budget. In addition to contributing new algorithms, we provide an extensive study of the zero-shot HPO technique resulting in (1) default hyper-parameters for popular algorithms that would benefit the community using them, (2) massive lookup tables to further the research of hyper-parameter tuning.
Towards White-box Benchmarks for Algorithm Control
Jun 18, 2019
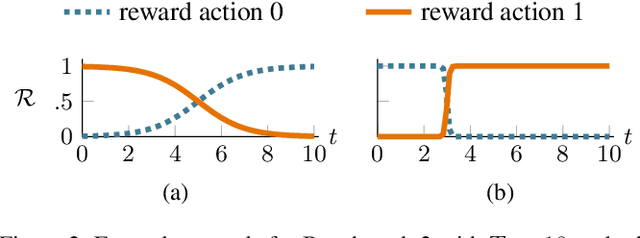
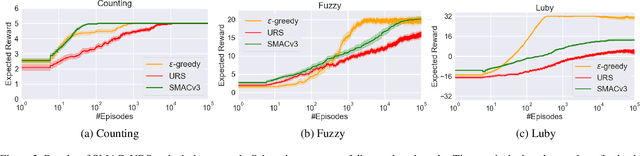
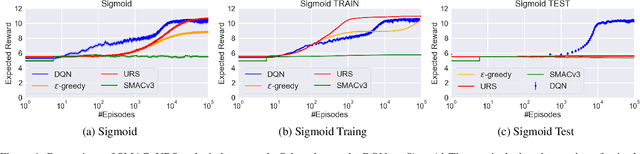
The performance of many algorithms in the fields of hard combinatorial problem solving, machine learning or AI in general depends on tuned hyperparameter configurations. Automated methods have been proposed to alleviate users from the tedious and error-prone task of manually searching for performance-optimized configurations across a set of problem instances. However there is still a lot of untapped potential through adjusting an algorithm's hyperparameters online since different hyperparameters are potentially optimal at different stages of the algorithm. We formulate the problem of adjusting an algorithm's hyperparameters for a given instance on the fly as a contextual MDP, making reinforcement learning (RL) the prime candidate to solve the resulting algorithm control problem in a data-driven way. Furthermore, inspired by applications of algorithm configuration, we introduce new white-box benchmarks suitable to study algorithm control. We show that on short sequences, algorithm configuration is a valid choice, but that with increasing sequence length a black-box view on the problem quickly becomes infeasible and RL performs better.