 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabTransformer: Tabular Data Modeling Using Contextual Embeddings
Dec 11, 2020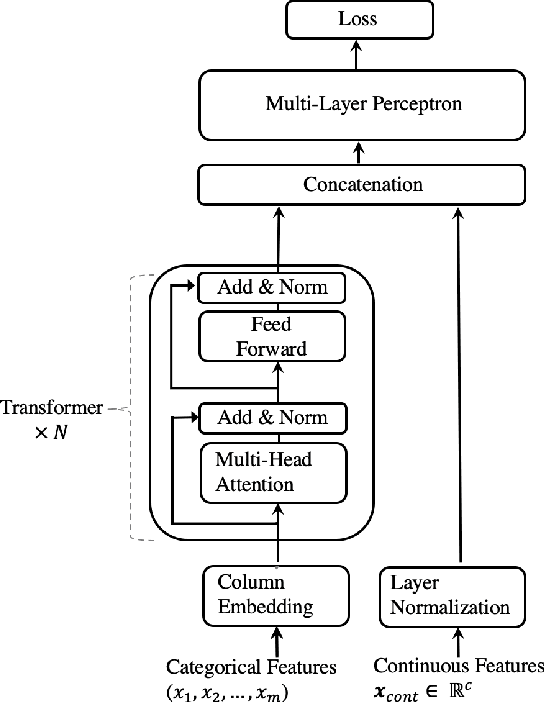
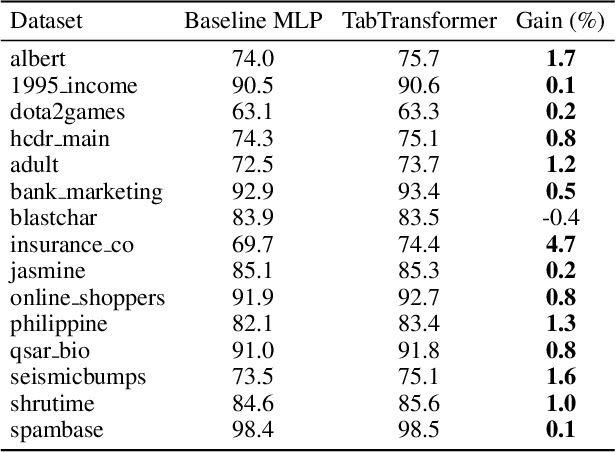
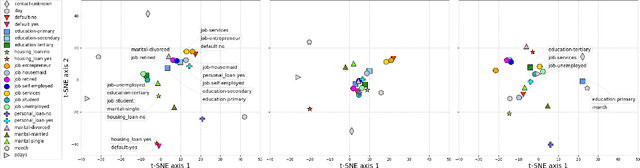
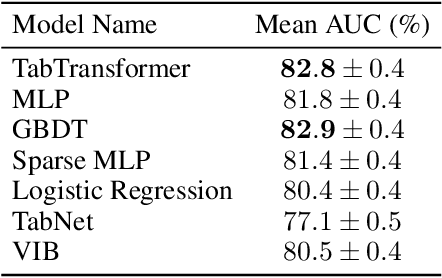
We propose TabTransformer, a novel deep tabular data modeling architecture for supervised and semi-supervised learning. The TabTransformer is built upon self-attention based Transformers. The Transformer layers transform the embeddings of categorical features into robust contextual embeddings to achieve higher prediction accuracy. Through extensive experiments on fifteen publicly available datasets, we show that the TabTransformer outperforms the state-of-the-art deep learning methods for tabular data by at least 1.0% on mean AUC, and matches the performance of tree-based ensemble models. Furthermore, we demonstrate that the contextual embeddings learned from TabTransformer are highly robust against both missing and noisy data features, and provide better interpretability. Lastly, for the semi-supervised setting we develop an unsupervised pre-training procedure to learn data-driven contextual embeddings, resulting in an average 2.1% AUC lift over the state-of-the-art methods.
Supervised Learning on Relational Databases with Graph Neural Networks
Feb 06, 2020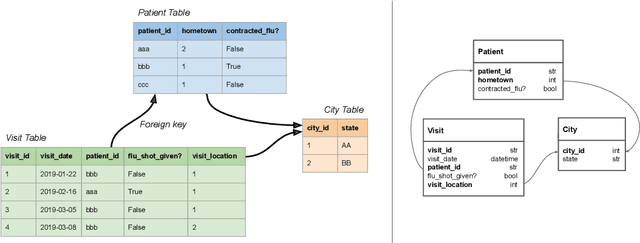

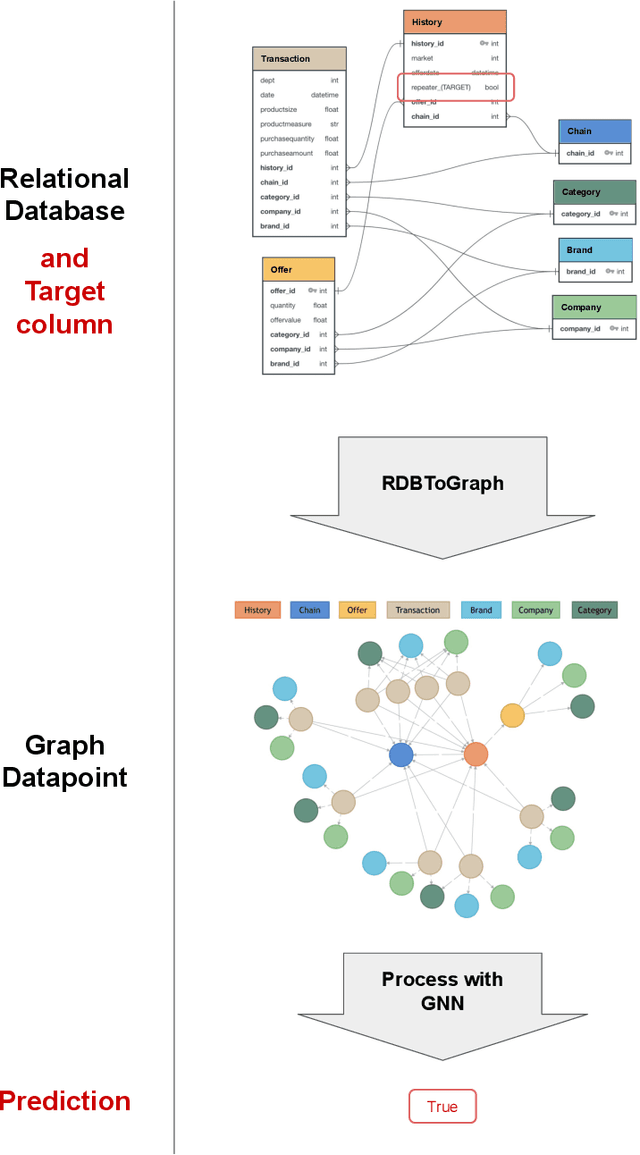
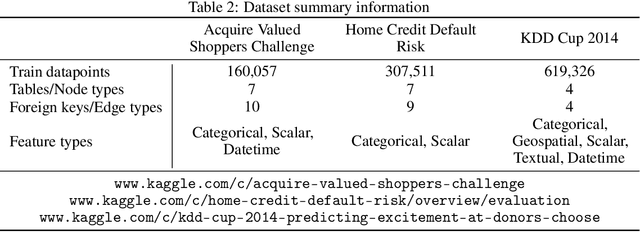
The majority of data scientists and machine learning practitioners use relational data in their work [State of ML and Data Science 2017, Kaggle, Inc.]. But training machine learning models on data stored in relational databases requires significant data extraction and feature engineering efforts. These efforts are not only costly, but they also destroy potentially important relational structure in the data. We introduce a method that uses Graph Neural Networks to overcome these challenges. Our proposed method outperforms state-of-the-art automatic feature engineering methods on two out of three datasets.
SLM Lab: A Comprehensive Benchmark and Modular Software Framework for Reproducible Deep Reinforcement Learning
Dec 28, 2019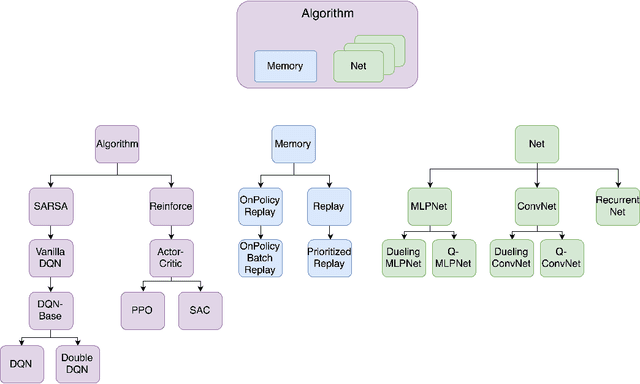
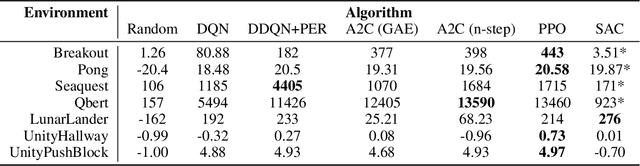

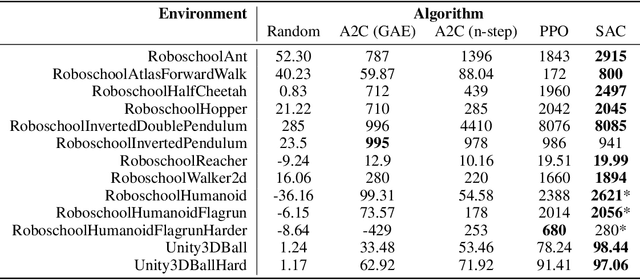
We introduce SLM Lab, a software framework for reproducible reinforcement learning (RL) research. SLM Lab implements a number of popular RL algorithms, provides synchronous and asynchronous parallel experiment execution, hyperparameter search, and result analysis. RL algorithms in SLM Lab are implemented in a modular way such that differences in algorithm performance can be confidently ascribed to differences between algorithms, not between implementations. In this work we present the design choices behind SLM Lab and use it to produce a comprehensive single-codebase RL algorithm benchmark. In addition, as a consequence of SLM Lab's modular design, we introduce and evaluate a discrete-action variant of the Soft Actor-Critic algorithm (Haarnoja et al., 2018) and a hybrid synchronous/asynchronous training method for RL agents.
Sampling-Free Learning of Bayesian Quantized Neural Networks
Dec 06, 2019
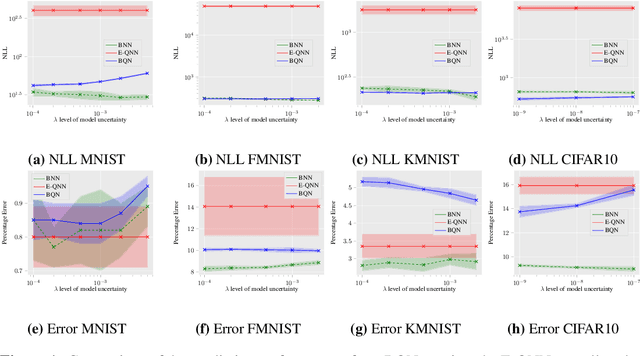
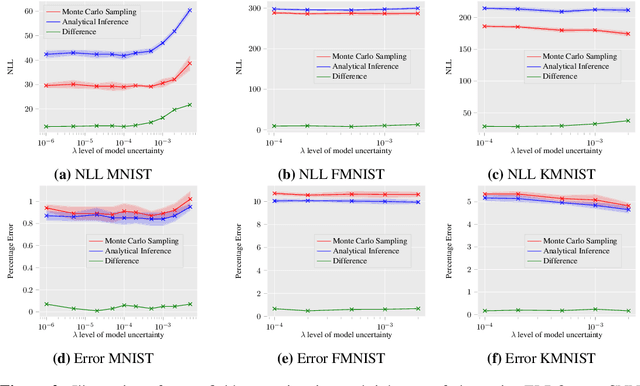

Bayesian learning of model parameters in neural networks is important in scenarios where estimates with well-calibrated uncertainty are important. In this paper, we propose Bayesian quantized networks (BQNs), quantized neural networks (QNNs) for which we learn a posterior distribution over their discrete parameters. We provide a set of efficient algorithms for learning and prediction in BQNs without the need to sample from their parameters or activations, which not only allows for differentiable learning in QNNs, but also reduces the variance in gradients. We evaluate BQNs on MNIST, Fashion-MNIST, KMNIST and CIFAR10 image classification datasets, compared against bootstrap ensemble of QNNs (E-QNN). We demonstrate BQNs achieve both lower predictive errors and better-calibrated uncertainties than E-QNN (with less than 20% of the negative log-likelihood).
Minimal Achievable Sufficient Statistic Learning
May 19, 2019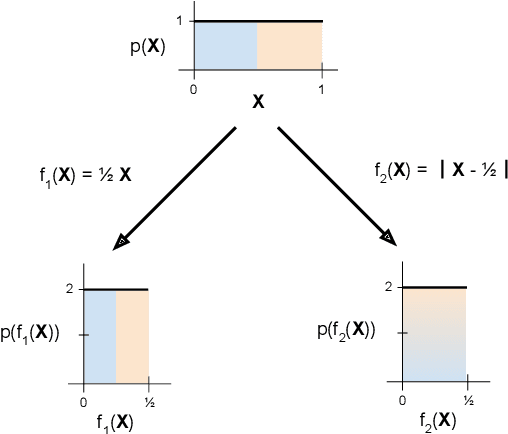
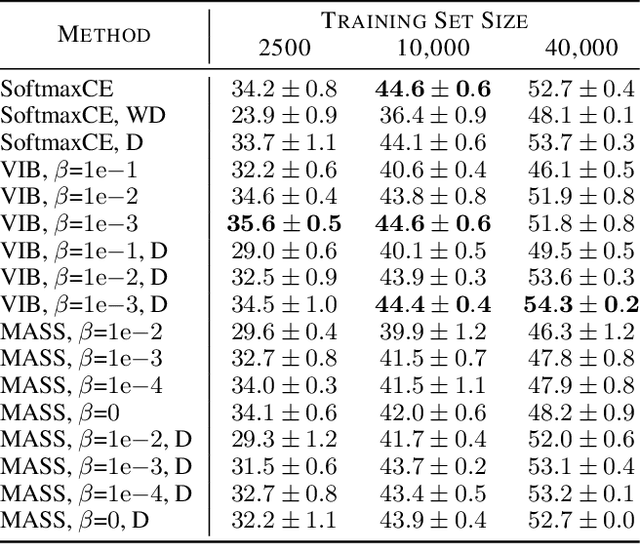
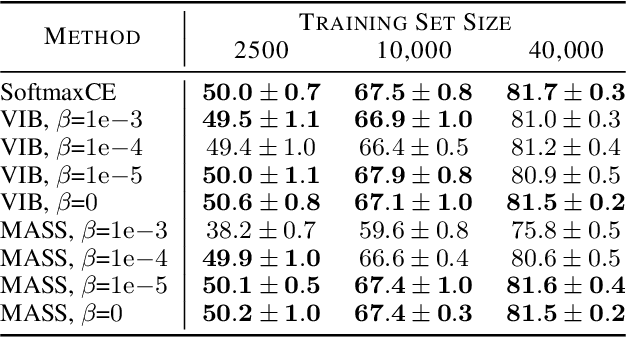
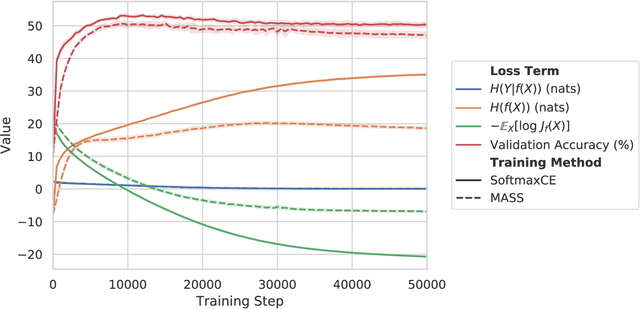
We introduce Minimal Achievable Sufficient Statistic (MASS) Learning, a training method for machine learning models that attempts to produce minimal sufficient statistics with respect to a class of functions (e.g. deep networks) being optimized over. In deriving MASS Learning, we also introduce Conserved Differential Information (CDI), an information-theoretic quantity that - unlike standard mutual information - can be usefully applied to deterministically-dependent continuous random variables like the input and output of a deep network. In a series of experiments, we show that deep networks trained with MASS Learning achieve competitive performance on supervised learning, regularization, and uncertainty quantification benchmarks.
A General Method for Amortizing Variational Filtering
Nov 13, 2018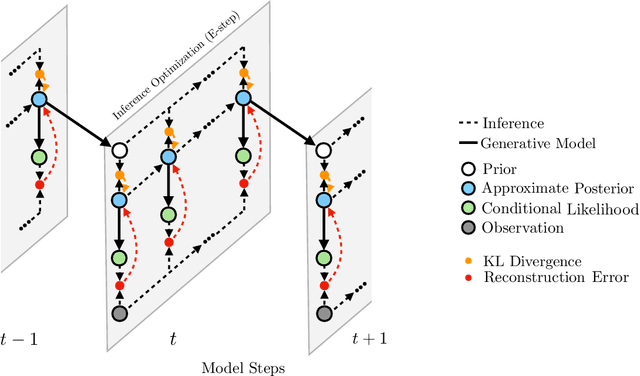
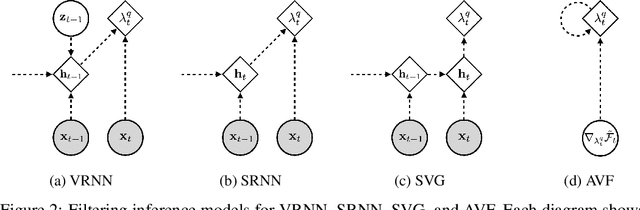
We introduce the variational filtering EM algorithm, a simple, general-purpose method for performing variational inference in dynamical latent variable models using information from only past and present variables, i.e. filtering. The algorithm is derived from the variational objective in the filtering setting and consists of an optimization procedure at each time step. By performing each inference optimization procedure with an iterative amortized inference model, we obtain a computationally efficient implementation of the algorithm, which we call amortized variational filtering. We present experiments demonstrating that this general-purpose method improves performance across several deep dynamical latent variable models.
Some Requests for Machine Learning Research from the East African Tech Scene
Oct 25, 2018Based on 46 in-depth interviews with scientists, engineers, and CEOs, this document presents a list of concrete machine research problems, progress on which would directly benefit tech ventures in East Africa.
Open Vocabulary Learning on Source Code with a Graph-Structured Cache
Oct 18, 2018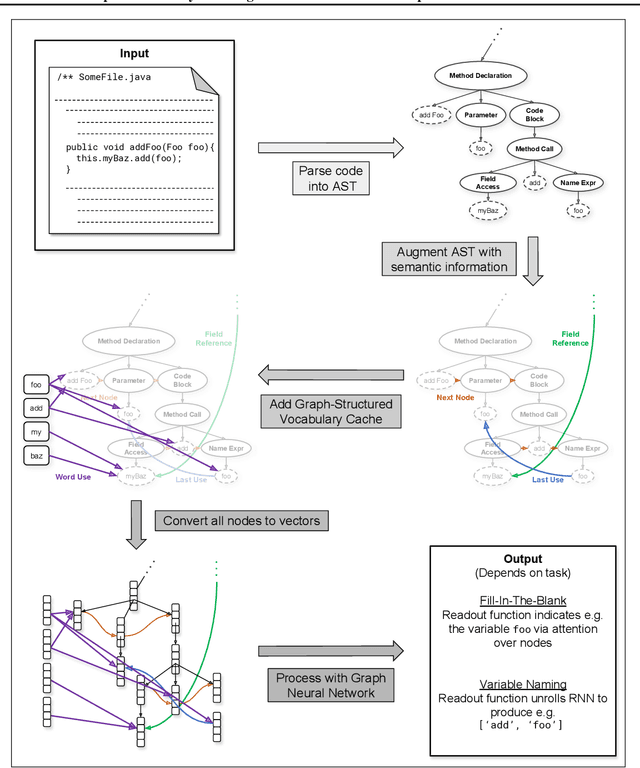
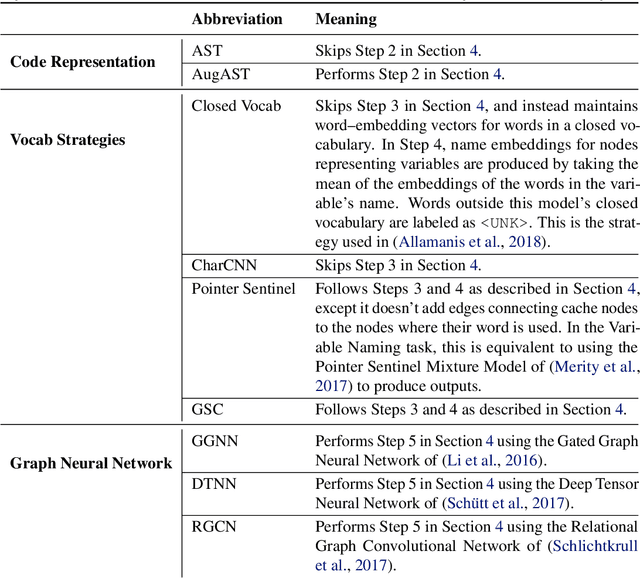
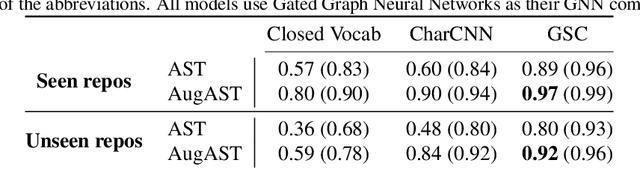
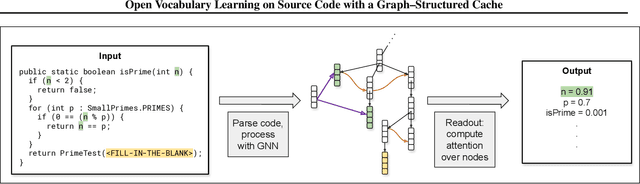
Machine learning models that take computer program source code as input typically use Natural Language Processing (NLP) techniques. However, a major challenge is that code is written using an open, rapidly changing vocabulary due to, e.g., the coinage of new variable and method names. Reasoning over such a vocabulary is not something for which most NLP methods are designed. We introduce a Graph-Structured Cache to address this problem; this cache contains a node for each new word the model encounters with edges connecting each word to its occurrences in the code. We find that combining this graph-structured cache strategy with recent Graph-Neural-Network-based models for supervised learning on code improves the models' performance on a code completion task and a variable naming task --- with over 100% relative improvement on the latter --- at the cost of a moderate increase in computation time.