 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Matters: Evaluating Synthetic Data for Tool-Using LLMs
Sep 26, 2024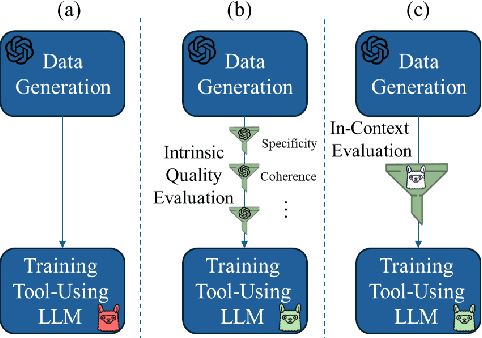


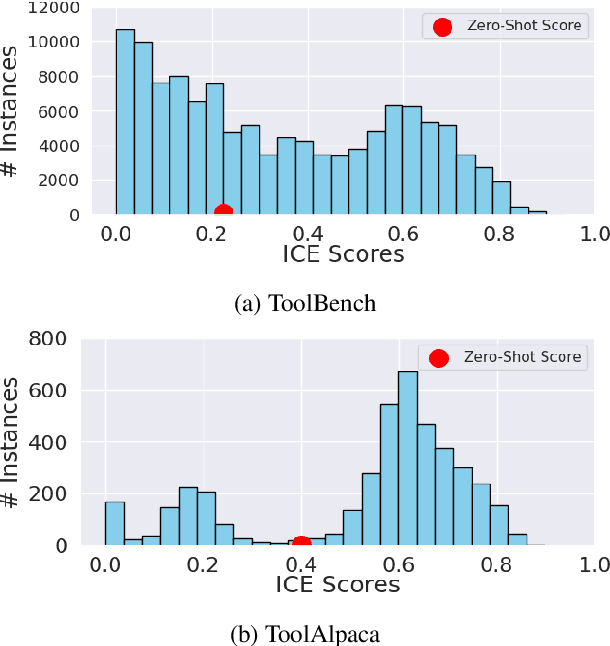
Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs to use external tools. The first approach uses intuitive, human-defined correctness criteria. The second approach uses a model-driven assessment with in-context evaluation. We conduct a thorough evaluation of data quality on two popular benchmarks, followed by an extrinsic evaluation that showcases the impact of data quality on model performance. Our results demonstrate that models trained on high-quality data outperform those trained on unvalidated data, even when trained with a smaller quantity of data. These findings empirically support the significance of assessing and ensuring the reliability of training data for tool-using LLMs.
Leveraging Prototypical Representations for Mitigating Social Bias without Demographic Information
Mar 14, 2024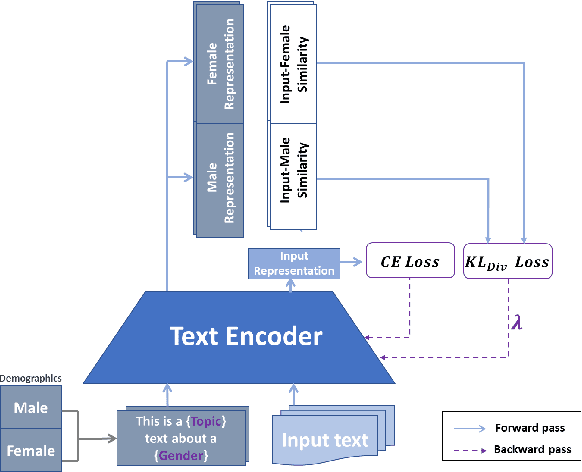
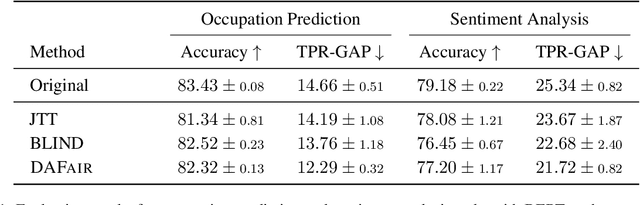

Mitigating social biases typically requires identifying the social groups associated with each data sample. In this paper, we present DAFair, a novel approach to address social bias in language models. Unlike traditional methods that rely on explicit demographic labels, our approach does not require any such information. Instead, we leverage predefined prototypical demographic texts and incorporate a regularization term during the fine-tuning process to mitigate bias in the model's representations. Our empirical results across two tasks and two models demonstrate the effectiveness of our method compared to previous approaches that do not rely on labeled data. Moreover, with limited demographic-annotated data, our approach outperforms common debiasing approaches.
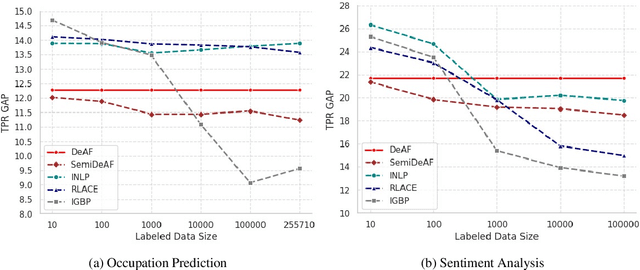
Shielded Representations: Protecting Sensitive Attributes Through Iterative Gradient-Based Projection
May 17, 2023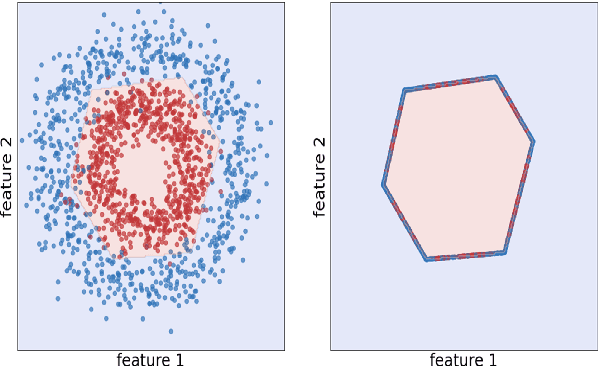
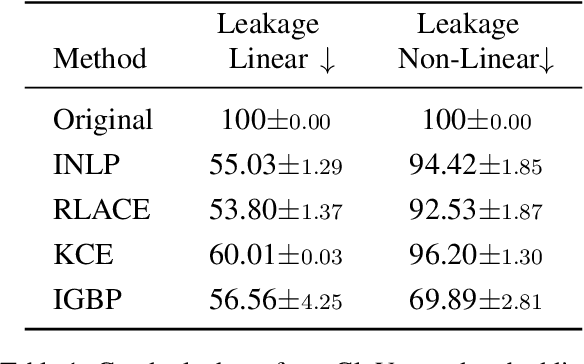
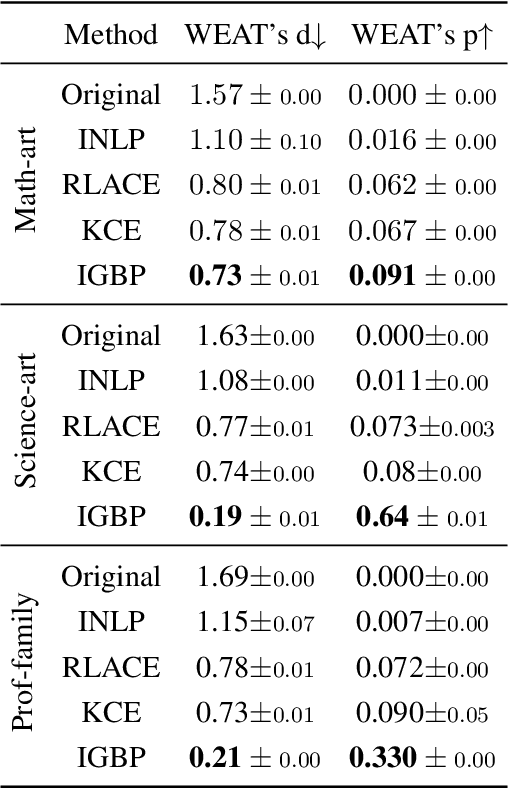
Natural language processing models tend to learn and encode social biases present in the data. One popular approach for addressing such biases is to eliminate encoded information from the model's representations. However, current methods are restricted to removing only linearly encoded information. In this work, we propose Iterative Gradient-Based Projection (IGBP), a novel method for removing non-linear encoded concepts from neural representations. Our method consists of iteratively training neural classifiers to predict a particular attribute we seek to eliminate, followed by a projection of the representation on a hypersurface, such that the classifiers become oblivious to the target attribute. We evaluate the effectiveness of our method on the task of removing gender and race information as sensitive attributes. Our results demonstrate that IGBP is effective in mitigating bias through intrinsic and extrinsic evaluations, with minimal impact on downstream task accuracy.