 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing When to Quit: A Principled Framework for Dynamic Abstention in LLM Reasoning
Apr 20, 2026Large language models (LLMs) using chain-of-thought reasoning often waste substantial compute by producing long, incorrect responses. Abstention can mitigate this by withholding outputs unlikely to be correct. While most abstention methods decide to withhold outputs before or after generation, dynamic mid-generation abstention considers early termination of unpromising reasoning traces at each token position. Prior work has explored empirical variants of this idea, but principled guidance for the abstention rule remains lacking. We present a formal analysis of dynamic abstention for LLMs, modeling abstention as an explicit action within a regularized reinforcement learning framework. An abstention reward parameter controls the trade-off between compute and information. We show that abstaining when the value function falls below this reward strictly outperforms natural baselines under general conditions. We further derive a principled and efficient method to approximate the value function. Empirical results on mathematical reasoning and toxicity avoidance tasks support our theory and demonstrate improved selective accuracy over existing methods.
ChaI-TeA: A Benchmark for Evaluating Autocompletion of Interactions with LLM-based Chatbots
Dec 24, 2024
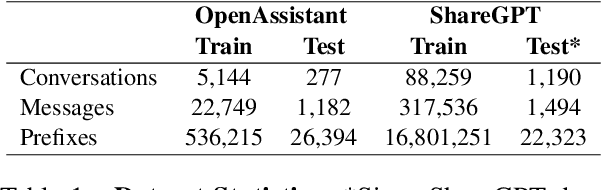

The rise of LLMs has deflected a growing portion of human-computer interactions towards LLM-based chatbots. The remarkable abilities of these models allow users to interact using long, diverse natural language text covering a wide range of topics and styles. Phrasing these messages is a time and effort consuming task, calling for an autocomplete solution to assist users. We introduce the task of chatbot interaction autocomplete. We present ChaI-TeA: CHat InTEraction Autocomplete; An autcomplete evaluation framework for LLM-based chatbot interactions. The framework includes a formal definition of the task, coupled with suitable datasets and metrics. We use the framework to evaluate After formally defining the task along with suitable datasets and metrics, we test 9 models on the defined auto completion task, finding that while current off-the-shelf models perform fairly, there is still much room for improvement, mainly in ranking of the generated suggestions. We provide insights for practitioners working on this task and open new research directions for researchers in the field. We release our framework to serve as a foundation for future research.
Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs
Sep 26, 2024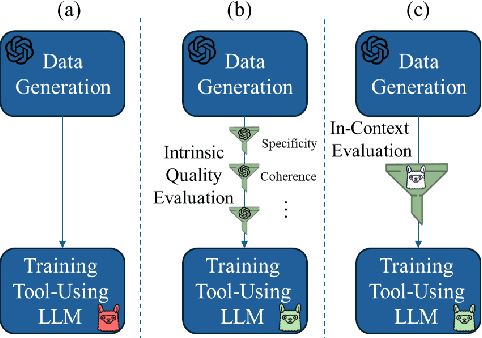


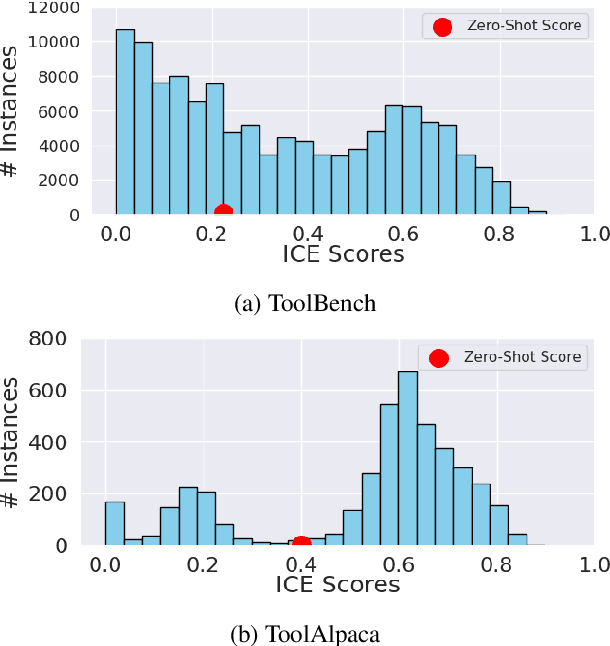
Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs to use external tools. The first approach uses intuitive, human-defined correctness criteria. The second approach uses a model-driven assessment with in-context evaluation. We conduct a thorough evaluation of data quality on two popular benchmarks, followed by an extrinsic evaluation that showcases the impact of data quality on model performance. Our results demonstrate that models trained on high-quality data outperform those trained on unvalidated data, even when trained with a smaller quantity of data. These findings empirically support the significance of assessing and ensuring the reliability of training data for tool-using LLMs.
Evaluating D-MERIT of Partial-annotation on Information Retrieval
Jun 23, 2024



Retrieval models are often evaluated on partially-annotated datasets. Each query is mapped to a few relevant texts and the remaining corpus is assumed to be irrelevant. As a result, models that successfully retrieve false negatives are punished in evaluation. Unfortunately, completely annotating all texts for every query is not resource efficient. In this work, we show that using partially-annotated datasets in evaluation can paint a distorted picture. We curate D-MERIT, a passage retrieval evaluation set from Wikipedia, aspiring to contain all relevant passages for each query. Queries describe a group (e.g., ``journals about linguistics'') and relevant passages are evidence that entities belong to the group (e.g., a passage indicating that Language is a journal about linguistics). We show that evaluating on a dataset containing annotations for only a subset of the relevant passages might result in misleading ranking of the retrieval systems and that as more relevant texts are included in the evaluation set, the rankings converge. We propose our dataset as a resource for evaluation and our study as a recommendation for balance between resource-efficiency and reliable evaluation when annotating evaluation sets for text retrieval.
Identifying Shopping Intent in Product QA for Proactive Recommendations
Apr 09, 2024


Voice assistants have become ubiquitous in smart devices allowing users to instantly access information via voice questions. While extensive research has been conducted in question answering for voice search, little attention has been paid on how to enable proactive recommendations from a voice assistant to its users. This is a highly challenging problem that often leads to user friction, mainly due to recommendations provided to the users at the wrong time. We focus on the domain of e-commerce, namely in identifying Shopping Product Questions (SPQs), where the user asking a product-related question may have an underlying shopping need. Identifying a user's shopping need allows voice assistants to enhance shopping experience by determining when to provide recommendations, such as product or deal recommendations, or proactive shopping actions recommendation. Identifying SPQs is a challenging problem and cannot be done from question text alone, and thus requires to infer latent user behavior patterns inferred from user's past shopping history. We propose features that capture the user's latent shopping behavior from their purchase history, and combine them using a novel Mixture-of-Experts (MoE) model. Our evaluation shows that the proposed approach is able to identify SPQs with a high score of F1=0.91. Furthermore, based on an online evaluation with real voice assistant users, we identify SPQs in real-time and recommend shopping actions to users to add the queried product into their shopping list. We demonstrate that we are able to accurately identify SPQs, as indicated by the significantly higher rate of added products to users' shopping lists when being prompted after SPQs vs random PQs.
SDR: Efficient Neural Re-ranking using Succinct Document Representation
Oct 03, 2021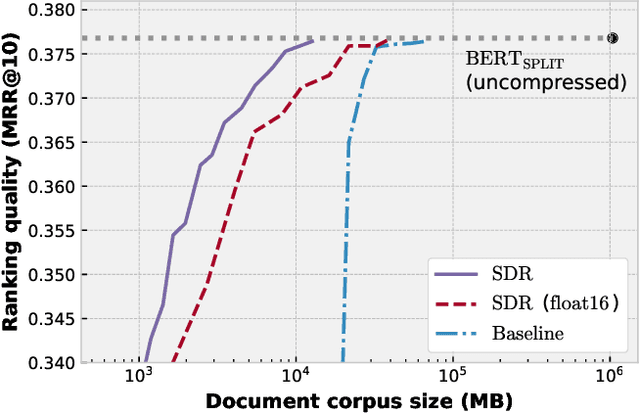
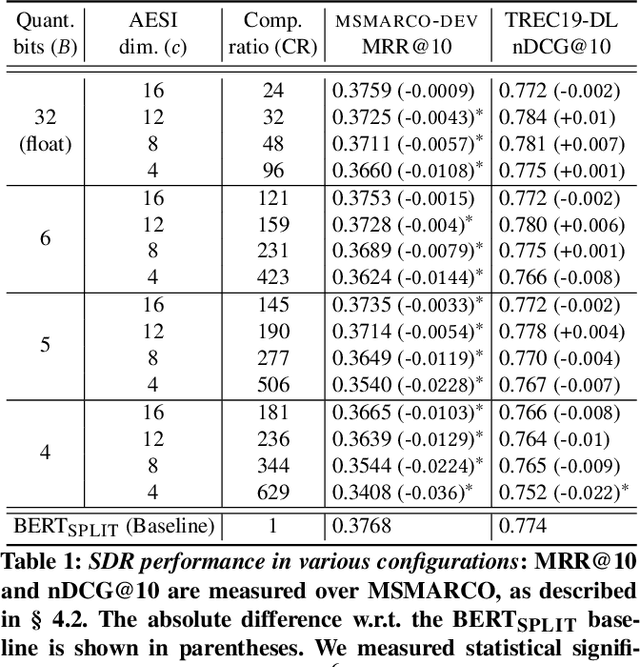
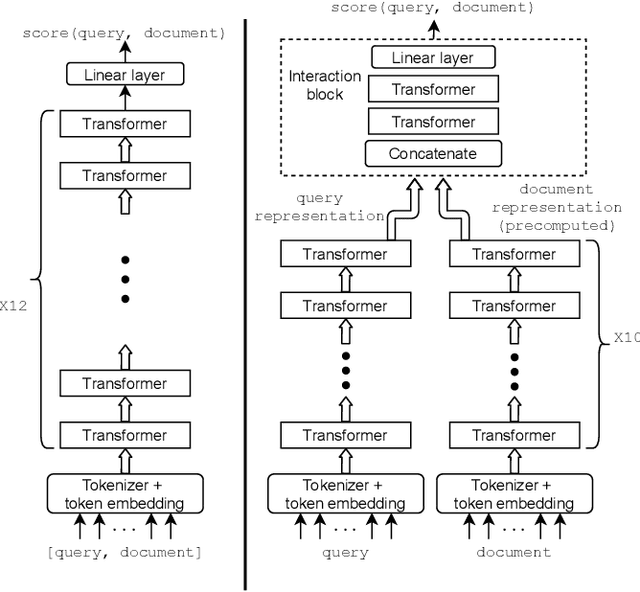
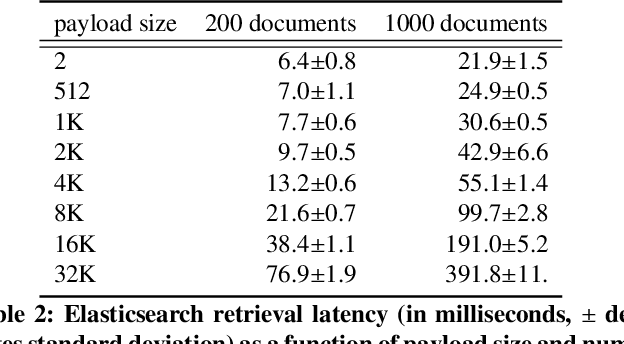
BERT based ranking models have achieved superior performance on various information retrieval tasks. However, the large number of parameters and complex self-attention operation come at a significant latency overhead. To remedy this, recent works propose late-interaction architectures, which allow pre-computation of intermediate document representations, thus reducing the runtime latency. Nonetheless, having solved the immediate latency issue, these methods now introduce storage costs and network fetching latency, which limits their adoption in real-life production systems. In this work, we propose the Succinct Document Representation (SDR) scheme that computes highly compressed intermediate document representations, mitigating the storage/network issue. Our approach first reduces the dimension of token representations by encoding them using a novel autoencoder architecture that uses the document's textual content in both the encoding and decoding phases. After this token encoding step, we further reduce the size of entire document representations using a modern quantization technique. Extensive evaluations on passage re-reranking on the MSMARCO dataset show that compared to existing approaches using compressed document representations, our method is highly efficient, achieving 4x-11.6x better compression rates for the same ranking quality.