 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaI-TeA: A Benchmark for Evaluating Autocompletion of Interactions with LLM-based Chatbots
Dec 24, 2024
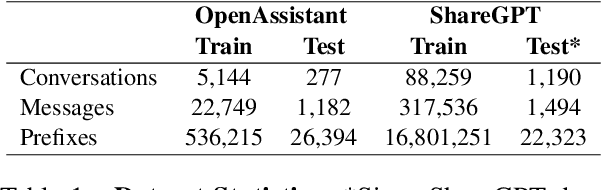

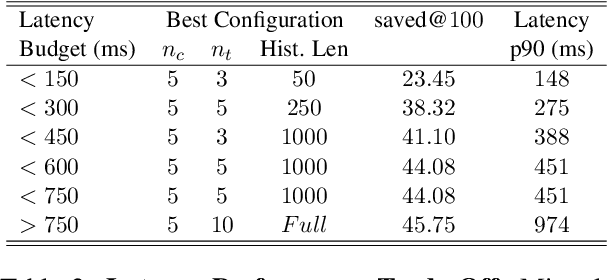
The rise of LLMs has deflected a growing portion of human-computer interactions towards LLM-based chatbots. The remarkable abilities of these models allow users to interact using long, diverse natural language text covering a wide range of topics and styles. Phrasing these messages is a time and effort consuming task, calling for an autocomplete solution to assist users. We introduce the task of chatbot interaction autocomplete. We present ChaI-TeA: CHat InTEraction Autocomplete; An autcomplete evaluation framework for LLM-based chatbot interactions. The framework includes a formal definition of the task, coupled with suitable datasets and metrics. We use the framework to evaluate After formally defining the task along with suitable datasets and metrics, we test 9 models on the defined auto completion task, finding that while current off-the-shelf models perform fairly, there is still much room for improvement, mainly in ranking of the generated suggestions. We provide insights for practitioners working on this task and open new research directions for researchers in the field. We release our framework to serve as a foundation for future research.
Evaluating D-MERIT of Partial-annotation on Information Retrieval
Jun 23, 2024



Retrieval models are often evaluated on partially-annotated datasets. Each query is mapped to a few relevant texts and the remaining corpus is assumed to be irrelevant. As a result, models that successfully retrieve false negatives are punished in evaluation. Unfortunately, completely annotating all texts for every query is not resource efficient. In this work, we show that using partially-annotated datasets in evaluation can paint a distorted picture. We curate D-MERIT, a passage retrieval evaluation set from Wikipedia, aspiring to contain all relevant passages for each query. Queries describe a group (e.g., ``journals about linguistics'') and relevant passages are evidence that entities belong to the group (e.g., a passage indicating that Language is a journal about linguistics). We show that evaluating on a dataset containing annotations for only a subset of the relevant passages might result in misleading ranking of the retrieval systems and that as more relevant texts are included in the evaluation set, the rankings converge. We propose our dataset as a resource for evaluation and our study as a recommendation for balance between resource-efficiency and reliable evaluation when annotating evaluation sets for text retrieval.
A Two-Stage Masked LM Method for Term Set Expansion
May 03, 2020
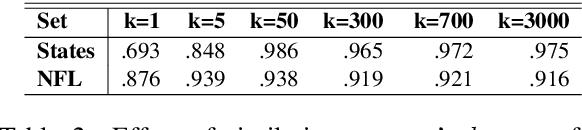
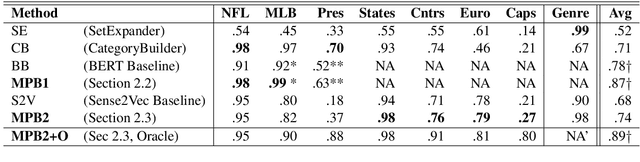

We tackle the task of Term Set Expansion (TSE): given a small seed set of example terms from a semantic class, finding more members of that class. The task is of great practical utility, and also of theoretical utility as it requires generalization from few examples. Previous approaches to the TSE task can be characterized as either distributional or pattern-based. We harness the power of neural masked language models (MLM) and propose a novel TSE algorithm, which combines the pattern-based and distributional approaches. Due to the small size of the seed set, fine-tuning methods are not effective, calling for more creative use of the MLM. The gist of the idea is to use the MLM to first mine for informative patterns with respect to the seed set, and then to obtain more members of the seed class by generalizing these patterns. Our method outperforms state-of-the-art TSE algorithms. Implementation is available at: https://github.com/ guykush/TermSetExpansion-MPB/